Poly-MOT跟踪效果的直接对比,也体现了文章的核心思想,就是为不同类别建立不同的运动模型。汽车使....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 11-20 16:46
•3142次阅读
无人驾驶飞行器(UAV)在各种现实应用中发挥着越来越重要的作用,例如搜索和救援、洞穴勘测、建筑测绘和....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 11-17 09:42
•1987次阅读

我们介绍了开放词汇3D实例分割的任务。当前的3D实例分割方法通常只能从训练数据集中标注的预定义的封闭....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 11-14 15:53
•1745次阅读
深度学习、艺术家策划的扫描和隐式功能(IF)的结合,使从图像中创建详细的、有衣的3D人体成为可能。然....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 11-13 16:11
•1701次阅读

本文还引入了多视角一致性优化模块,以提高学习到的射线-表面距离场在不同视角下的一致性。通过在多个数据....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 11-10 15:04
•1321次阅读
但最近,NVIDIA和ETHZ就联合提出了nvblox,是一个使用GPU加速SDF建图的库。计算速度....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 11-09 16:46
•2715次阅读

在通常使用的nerf数据中,一个场景往往无法从同一视角捕捉多幅图像,这使得数学建模干扰物变得困难。更....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 11-09 16:35
•1696次阅读

神经辐射场 (NeRF)是一种新颖的隐式三维重建方法,显示出巨大的潜力,受到越来越多的关注。它能够仅....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 11-08 16:41
•1963次阅读

最大的好处就是可以直接利用Stable Diffusion这种经过数十亿张图像训练过的2D扩散模型,....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 11-06 16:13
•2123次阅读

但是这个方法同样也存在缺点,即著名的万向锁(或万向节死锁)(Gimbal Lock)问题:在俯仰角为....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 11-03 12:38
•2069次阅读
现有的DETR系列模型在非COCO数据集上表现较差,且预测框不够准确。其主要原因是:DETR在检测头....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 11-01 16:12
•1564次阅读
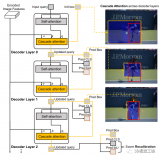
本系列文章将对LOAM源代码进行讲解,在讲解过程中,涉及到论文中提到的部分,会结合论文以及我自己的理....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 11-01 10:49
•4956次阅读

自我监督学习的目的是获得有利于下游任务的良好表现。主流的方法是使用对比学习来与训练网络。受CLIP成....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 10-29 16:54
•3112次阅读
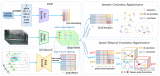
神经辐射场(NeRF)是一种利用神经网络来表示和渲染复杂的三维场景的方法。它可以从一组二维图片中学习....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 10-21 09:46
•1577次阅读
在目标追踪任务中,通常的球机或者枪机方案,无法避免人群遮挡的问题,从而导致较高的ID Swich,造....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 10-18 14:24
•6014次阅读

本文主要介绍了两个与NeRF(Neural Radiance Fields)相关的工作,分别是针对稀....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 10-17 15:46
•1303次阅读

总体而言,现有基于对应关系方法的局限性在于两个方面。首先,目前还没有统一、高效、通用的特征学习框架。....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 10-16 17:18
•2233次阅读

近年来,一些端到端学习方法被提出以增强六自由度物体定位的鲁棒性,包括:直接回归几何参数;采用渲染 -....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 10-16 17:13
•1963次阅读

(i)实例分割 :定义将每个点分配给某个片段 k{1 ...K} 的可能性,其中每个片段都是挤压柱面....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 10-12 16:49
•1537次阅读
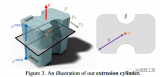
传感器融合对于自动驾驶和自主机器人是至关重要,毫米波雷达-相机融合系统由于其互补的传感能力而广受欢迎....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 10-09 14:17
•1858次阅读
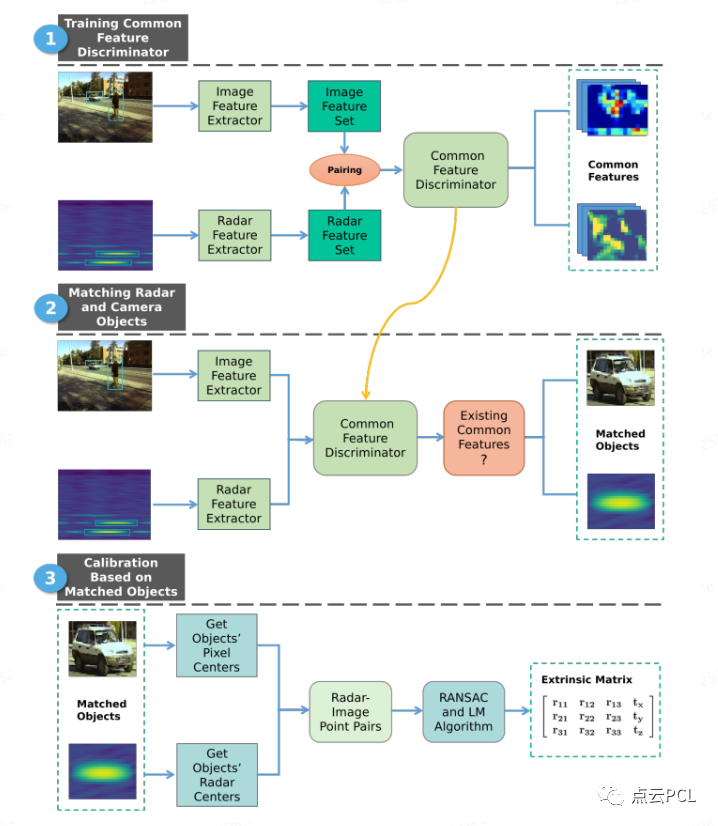
使用标准差代替了梯度计算,该方法相比原本的图像的Canny边缘检测器计算成本更高,但却可以将其应用于....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 10-08 15:46
•3534次阅读
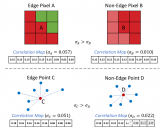
使用真实场景的车载激光点云和两幅全景图像进行试验,验证点-线特征联合的位姿解算方法优于单纯的点特征解....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 09-29 08:01
•1968次阅读
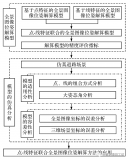
粗配准就是再两个点云还差得十万八千里、完全不清楚两个点云的相对位置关系的情况下,找到一个这两个点云近....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 09-25 11:31
•1978次阅读
目的:对通用人工智能系统的追求导致了强大的端到端可训练模型的开发,其中许多模型渴望为人工智能提供简单....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 09-23 11:16
•1412次阅读
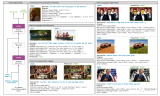
Multi-view Stereo(MVS)方法旨在从具有已知位姿的一组图像中恢复密集的3D场景结构....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 09-22 16:14
•1889次阅读
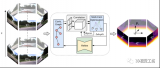
相似结构一直是SLAM和SfM中很难处理却又不得不处理的问题,如果机器人遇到了非常相似但实际不同的结....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 09-20 15:15
•1716次阅读

VoxelMap++的流程如图1所示,LiDAR原始点预处理方法和基于迭代误差状态卡尔曼滤波器的状态....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 09-11 17:02
•2088次阅读
Middlebury立体测评网站是计算机视觉领域的重要资源,它为研究人员和工程师提供了一个评估和比较....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 09-10 11:29
•3472次阅读

本文的网络将给定一个具有帧的动态场景的单目视频(I1, I2,…,, IN ) 和已知的相机参数 (....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 09-10 10:08
•4884次阅读

基于单张RGB图像在3D场景空间中定位行人对于各种下游应用至关重要。目前的单目定位方法要么利用行人的....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 09-08 09:29
•1612次阅读