 middlebury数据集是什么
middlebury数据集是什么
Middlebury立体测评网站是计算机视觉领域的重要资源,它为研究人员和工程师提供了一个评估和比较立体视觉算法的标准化平台。无论你是学术界的研究者还是工业界的从业者,通过使用Middlebury立体测评网站,你可以在算法开发中更好地了解和改进立体匹配算法。本文将为你提供关于Middlebury立体测评网站的详细使用指南,帮助你充分利用该平台。
一、middlebury数据集是什么?
Middlebury数据集是用于立体视觉算法评估的一系列标准化数据集,由Middlebury大学维护。立体视觉是计算机视觉领域中的一个重要研究方向,其目标是从不同角度获取的图像中,恢复出场景中物体的三维信息,即深度或视差图。
Middlebury数据集的设计旨在提供一组公共标准,让研究者和开发者能够在相同的基准下比较和评估他们开发的立体视觉算法。这些数据集涵盖了多个任务,包括立体图像重建、立体匹配、光流估计等。
Middlebury数据集是图像计算领域中广为使用的一系列立体和光流图像数据集。它是由Middlebury计算机视觉研究组织创建和维护的,旨在为研究者和开发者提供可靠的图像数据,以评估和比较不同的计算机视觉算法。
其中,立体图像数据集包含由两个或多个摄像机捕获的图像对,用于生成立体深度地图。光流图像数据集则包含了连续帧之间的像素位移信息,用于分析和推断对象在时间上的运动。
Middlebury数据集以其高质量的标注和真实场景的代表性而闻名。这些数据集经过仔细设计和选取,以提供丰富的挑战性问题和复杂的图像场景,以促进对计算机视觉算法的真实性能评估。
对于研究者和开发者来说,Middlebury数据集是一份宝贵的资源,可以用于测试自己的算法、比较不同算法的性能,并为新算法的开发提供可靠的基准。大量的研究论文和学术会议都使用Middlebury数据集作为他们算法的评估标准。
Middlebury数据集可以通过Middlebury计算机视觉研究组织的官方网站免费获取。研究者和开发者可以根据自己的需求和兴趣,在这些数据集上进行各种图像计算任务的研究和实验。
二、middlebury网址是什么?
https://vision.middlebury.edu/

根据 vision.middlebury.edu 网站的介绍,这是一个计算机视觉评估和数据集的存储库。网站包含以下内容:
Middlebury立体视觉页面:用于评估密集的双帧立体视觉算法(详细介绍见IJCV 2002)。
多视图立体页面:用于评估多视图立体视觉算法(CVPR 2006上发布)。
MRF页面:用于评估用于马尔可夫随机场的能量最小化方法(ECCV 2006上发布)。
光流页面:用于评估光流算法(ICCV 2007上发布)。
色彩页面:提供用于评估数字相机色彩处理的数据集(BMVC 2009上发布)
三、middlebury立体测评?
https://vision.middlebury.edu/stereo/
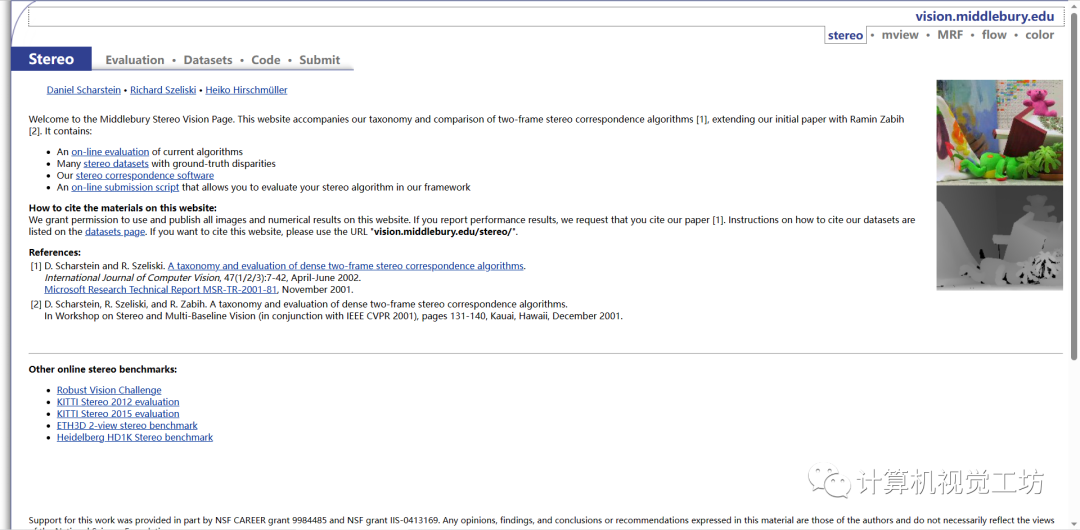
https://vision.middlebury.edu/stereo/ 是Middlebury立体视觉页面的链接,在这个页面上,你可以找到关于立体视觉算法的评估和数据集的详细信息。
Middlebury立体视觉页面是用于评估密集的两帧立体视觉算法的平台。它包括了:
当前算法的在线排名
许多具有地面实况差异的立体数据集
一个离线脚本,评估立体声算法
一个在线提交脚本,评估立体声算法
在这个页面上,你可以找到每个数据集的详细描述,包括数据集的来源、图像数量、分辨率和深度图等。此外,页面还提供了一些参考算法和评价标准,用于帮助评估和比较不同算法的性能。该页面还包含了一些用于可视化和比较算法结果的工具和软件。你可以使用这些工具来直观地呈现立体视觉算法的输出,并与其他算法进行比较。
3.1 当前算法的在线排名
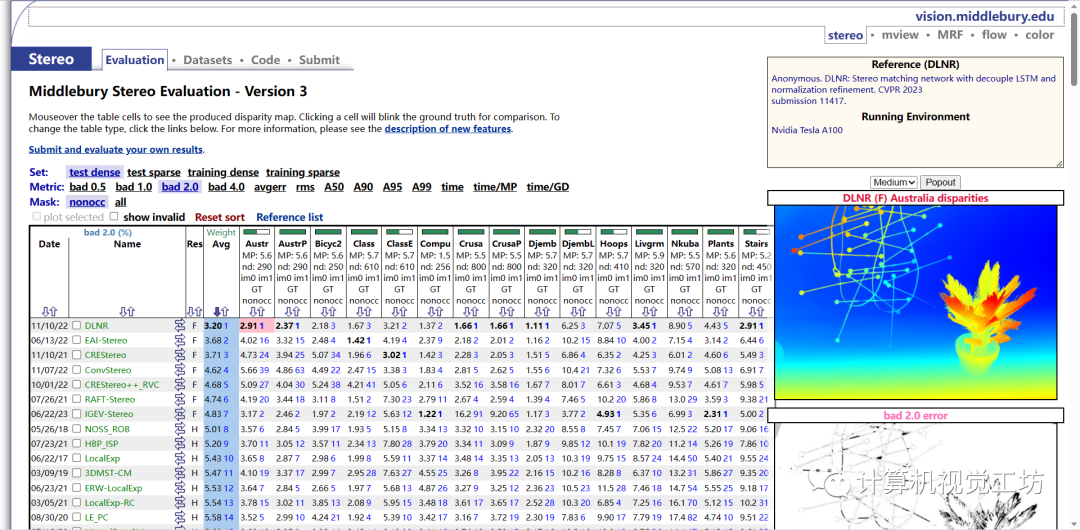
该页面包含了一个交互式的表格,用于展示不同数据集和评估指标的结果。你可以通过鼠标悬停在表格单元格上,查看生成的视差图。同时,点击单元格可以切换显示地面真实值以进行比较。你还可以通过点击页面上的链接,切换表格类型或了解新功能的描述。
Set: 设置或数据集的不同类型。在这种情况下,可能有以下设置/数据集:
test: 测试集
densetest: 密集测试集
sparsetraining: 稀疏训练集
densetraining: 密集训练集
sparse: 稀疏数据
Metric: 表示用于对视差图进行评估的不同指标。在这种情况下,可能有以下指标:
bad 0.5: 视差值误差小于等于0.5的比例
bad 1.0: 视差值误差小于等于1.0的比例
bad 2.0: 视差值误差小于等于2.0的比例
bad 4.0: 视差值误差小于等于4.0的比例
avgerr: 平均误差
rms: 均方根误差
A50: 视差误差小于等于50%的比例
A90: 视差误差小于等于90%的比例
A95: 视差误差小于等于95%的比例
A99: 视差误差小于等于99%的比例
time: 执行时间
time/MP: 每百万像素的执行时间
time/GD: 每个视差的执行时间
Mask: 掩码或遮挡的类型。在这种情况下,可能有以下类型:
nonocc: 非遮挡的区域
all: 所有区域(包括遮挡区域和非遮挡区域)
3.2 许多具有地面实况差异的立体数据集
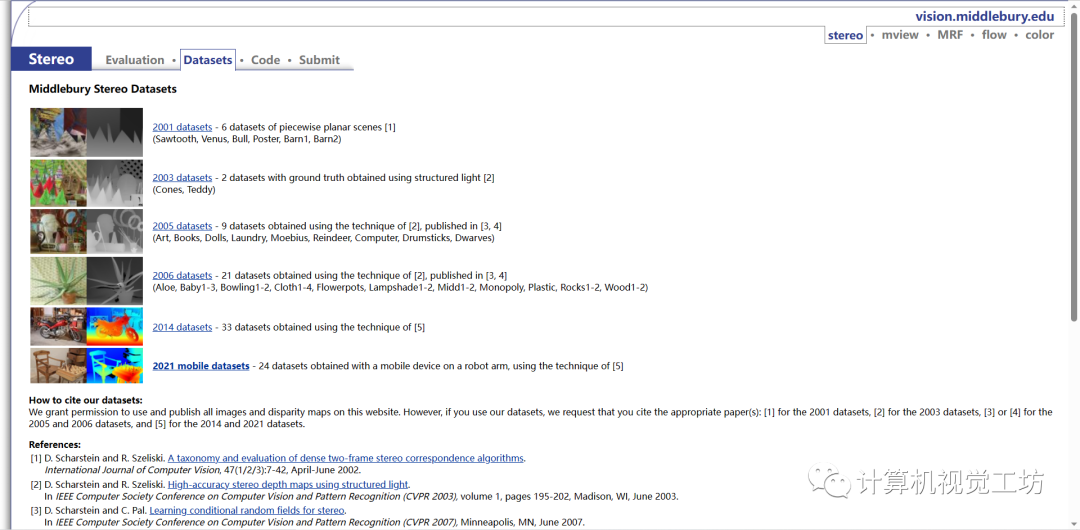
在该页面上,你可以找到middleburry提供的多个立体数据集的详细信息和下载链接。这些数据集包含了成对的左右图像,以及对应的地面真实视差图。这些数据集的制作遵循一定的标准和规范,广泛应用于立体视觉算法的训练和评估。
页面上列出的数据集包括了各种场景和复杂度,并标注了不同数据集的特点和用途。你可以浏览不同数据集的描述,了解其特点以及适用的应用场景。同时,你也可以点击链接下载对应数据集的图像和视差文件。
3.3 一个离线脚本,评估立体声算法
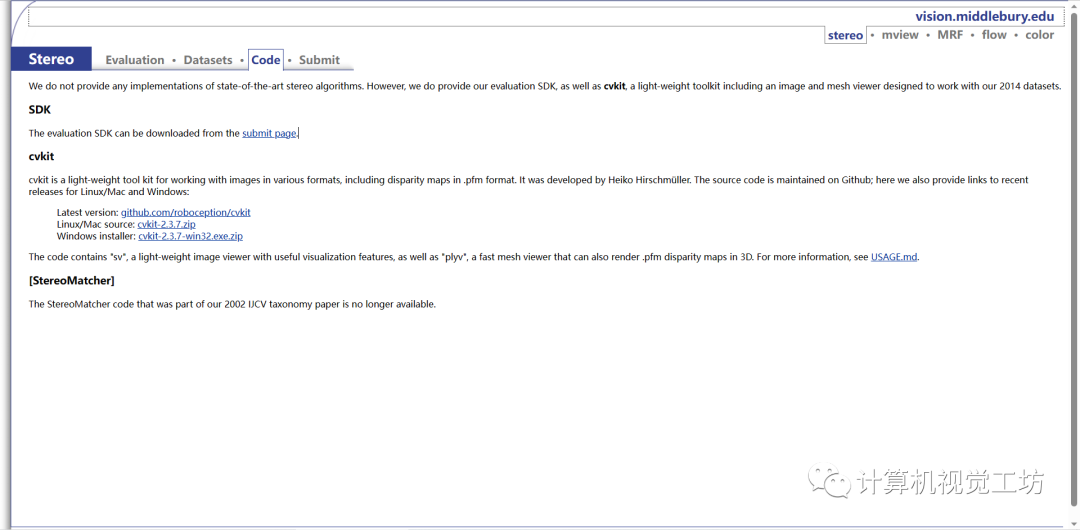
cvkit是一个轻量级的图像处理工具包,可用于处理各种格式的图像,包括.pfm格式的视差图。它由Heiko Hirschmüller开发。源代码在Github上维护;在这里,作者还提供了针对Linux/Mac和Windows最近发布版本的链接:
最新版本:https://github.com/roboception/cvkit
该代码包含了名为"sv"的轻量级图像查看器,具有有用的可视化功能,并且包含了"plyv",一个快速的网格查看器,也可以在3D中呈现.pfm的视差图。有关更多信息,请参阅USAGE.md。这里也推荐「3D视觉工坊」新课程《彻底剖析激光-视觉-IMU-GPS融合SLAM算法:理论推导、代码讲解和实战》
3.4 一个在线提交脚本,评估立体声算法
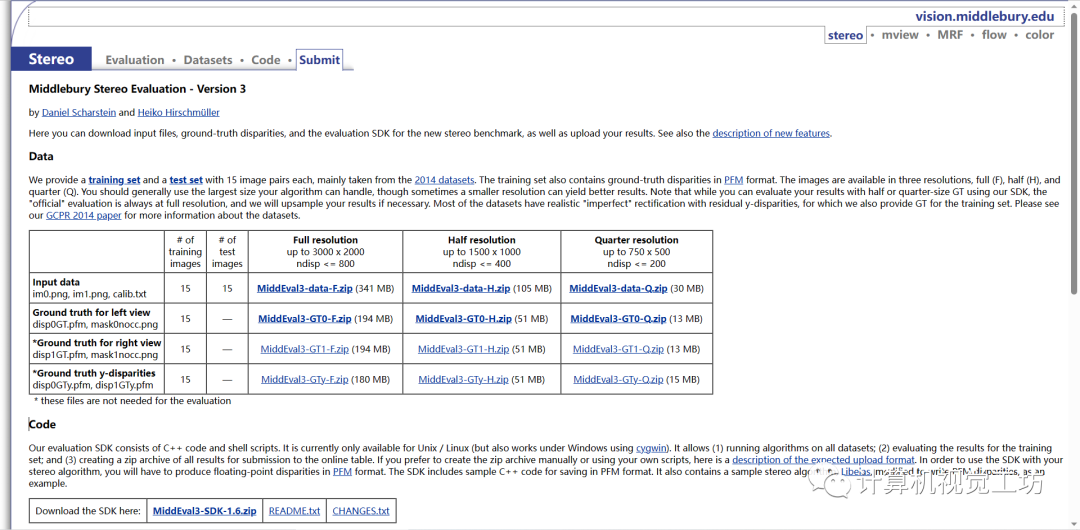
调整 SDK 以运行算法或手动创建 zip 文件后,您可以上传结果。您可以根据需要多次上传和评估训练集上的结果。与之前版本的立体评估一样,您将在临时表中看到您的结果与训练集上所有其他提交的结果的比较情况。获得最终结果集后,您可以将结果上传到训练集和测试集上,并请求发布这两组结果。为了防止拟合测试数据,我们只允许每个方法这样做一次,并且在测试结果发布之前,您将无法看到测试结果。请仅上传“最终”结果(已发表或即将提交给会议或期刊)。请注意,我们只允许表中每个发布有一个结果。如果您有多个算法变体,则可以在训练集上评估它们,但应仅选择并上传一个结果进行发布。
审核编辑:彭菁
-
图像
+关注
关注
2文章
1063浏览量
40041 -
网站
+关注
关注
1文章
256浏览量
22751 -
计算机视觉
+关注
关注
8文章
1600浏览量
45617 -
数据集
+关注
关注
4文章
1179浏览量
24353
原文标题:总结!Middlebury立体测评网站使用指南
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
怎么删除分析中的“Ghost”数据集
几大主流公开遥感数据集
如何利用keras打包制作mnist数据集
基于非对称空间金字塔池化模型的CNN结构

基于非对称空间金字塔池化模型的CNN结构
利用NeRF训练深度立体网络的创新流程






 工商网监
工商网监
评论