 基于文本提示就可自动实现复杂计算机视觉任务?
基于文本提示就可自动实现复杂计算机视觉任务?

本文提出了 VISPROG,一种神经符号方法,用于在给定自然语言指令的情况下解决复杂的组合视觉任务。VISPROG 无需进行任何特定任务的训练。相反,它利用大型语言模型的上下文学习能力来生成类似Python的模块化程序,然后执行这些程序以获得解决方案和全面且可解释的基本原理。
生成的程序的每一行都可以调用几个现成的计算机视觉模型、图像处理子例程或Python函数之一来产生可由程序的后续部分使用的中间输出。我们展示了 VISPROG 在 4 个不同任务上的灵活性 - 组合视觉问答、图像对的零样本推理、事实知识对象标记和语言引导图像编辑。我们相信像 VISPROG 这样的神经符号方法是一个令人兴奋的途径,可以轻松有效地扩展人工智能系统的范围,以服务于人们可能希望执行的复杂任务的长尾。
1 前言
目的:对通用人工智能系统的追求导致了强大的端到端可训练模型的开发,其中许多模型渴望为人工智能提供简单的自然语言界面使用户能与模型进行交互。现有方法:构建这些系统的主要方法是大规模无监督预训练,然后是监督多任务训练。然而,这种方法需要为每个任务提供精心策划的数据集,这使得扩展到我们最终希望这些系统执行的复杂任务变得具有挑战性。此论文工作:在这项工作中,探索使用大型语言模型来解决复杂任务的视觉问题,方法是将自然语言描述的这些任务分解为可以由专门的端到端训练模型或其他程序处理的更简单的步骤。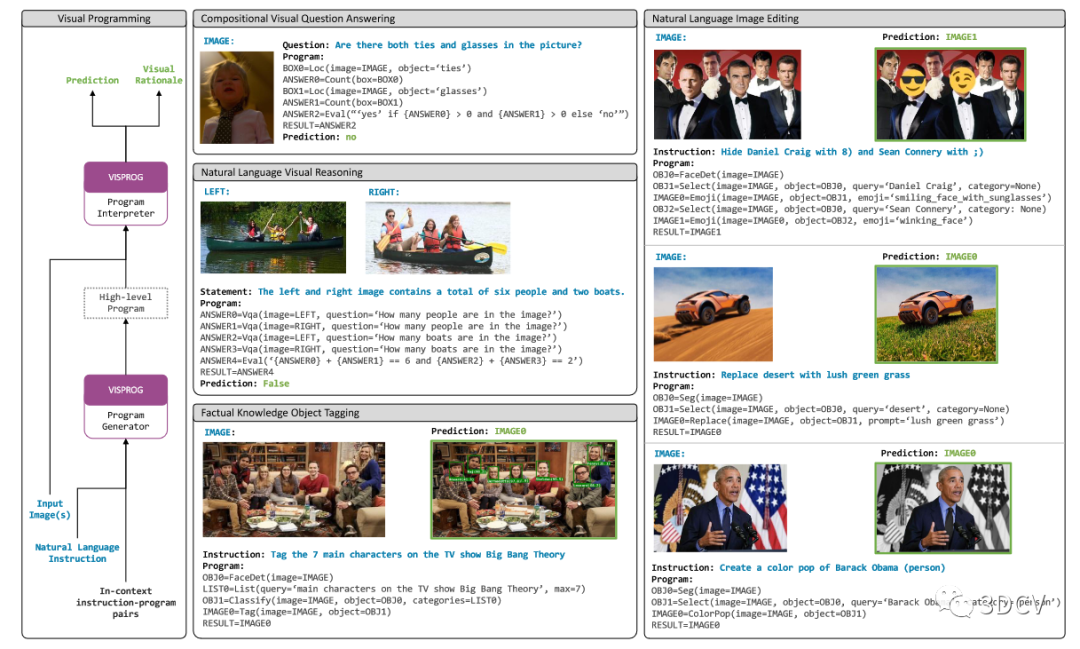
图 1.VISPROG 是一个用于组合视觉推理的模块化且可解释的神经符号系统(左为框架图,右为此系统可实现的四大任务)VISPROG,它输入视觉数据(单个图像或一组图像)以及自然语言指令,生成一系列步骤,如果您愿意,还可以生成可视化程序,然后执行这些步骤以产生所需的输出。可视化程序中的每一行都会调用系统当前支持的各种模块之一。模块可以是现成的计算机视觉模型、语言模型、OpenCV中的图像处理子例程或算术和逻辑运算符。
模块消耗通过执行前面的代码行产生的输入,并输出可被下游消耗的中间结果。在上面的示例中,VISPROG 生成的可视化程序调用人脸检测器、GPT-3 作为知识检索系统,以及 CLIP作为开放词汇图像分类器来生成所需的输出(参见图。1)。VISPROG 改进了以前为视觉应用生成和执行程序的方法。
对于视觉问答(VQA)任务,神经模块网络(NMN)[2,9,10,12]由专门的、可微分的神经模块组成一个特定于问题的、端到端的可训练网络。这些方法要么使用脆弱的、现成的语义解析器来确定性地计算模块的布局,要么通过 REINFORCE [30] 通过弱答案监督来学习布局生成器。相比之下,VISPROG 使用强大的语言模型(GPT-3)以及少量上下文示例,无需任何训练即可创建复杂的程序1。VISPROG 创建的程序还使用比 NMN 更高级别的抽象,并调用经过训练的最先进模型和非神经 Python 子例程(图 2)。
这些优点使 VISPROG 成为易于使用、高性能和模块化的神经符号系统。VISPROG 也具有高度可解释性。首先,VISPROG 生成易于理解的程序,用户可以验证其逻辑正确性。其次,通过将预测分解为简单的步骤,VISPROG 允许用户检查中间步骤的输出以诊断错误,并在需要时干预推理过程。总而言之,具有中间步骤结果(例如文本、边界框、分割掩模、生成的图像等)的执行程序链接在一起以描述信息流,作为预测的视觉原理。
为了展示其灵活性,我们使用 VISPROG 执行 4 个不同的任务,这些任务共享一些通用技能(例如图像解析),同时还需要一定程度的专业推理和视觉操作能力。这些任务是 - 我们强调,语言模型和任何模块都没有以任何方式进行微调。让 VISPROG 适应任何任务非常简单,只需提供一些由自然语言指令和相应程序组成的上下文示例即可。
虽然易于使用,但 VISPROG 在组合 VQA 任务上比基本 VQA 模型提高了 2.7 个点,在 NLVR 上的零样本准确率高达 62.4%,无需对图像对进行训练,并且在知识标记方面取得了令人愉快的定性和定量结果和图像编辑任务。
本文贡献点:(i) VISPROG - 一个使用语言模型的上下文学习能力从自然语言指令生成视觉程序的系统,用于组合视觉任务(第 3 节);(ii) 展示 VISPROG 在复杂视觉任务上的灵活性,例如事实知识对象标记和语言引导图像编辑,这些任务在单一端到端模型中未能实现或取得有限成功;(iii) 为这些任务提供可视化原理,并展示它们在错误分析和用户驱动指令调整方面的实用性,以显着提高 VISPROG 的性能。
2 相关背景
由于大型语言模型 (LLM) 令人难以置信的理解、生成和上下文学习能力,神经符号方法获得了新的发展动力。现在简单说明下以前的视觉任务程序生成和执行方法、最近使用LLMs进行视觉的工作以及语言任务推理方法的进展。视觉任务的程序生成和执行的相关工作。
神经模块网络(NMN开创了视觉问答(VQA)任务的模块化和组合方法。NMN 将神经模块组合成端到端的可微网络。虽然早期的尝试使用现成的解析器 ,但最近的方法使用 REINFORCE和弱答案监督与神经模块联合学习布局生成模型。虽然 VISPROG 与 NMN 的精神相似,但它比 NMN 有几个优势。
首先,VISPROG 生成高级程序,在中间步骤调用经过训练的最先进的神经模型和其他 Python 函数,而不是生成端到端神经网络。这使得合并符号化、不可微分的模块变得很容易。其次,VISPROG 利用LLMs的上下文学习能力,通过使用自然语言指令(或视觉问题或待验证的陈述)以及一些示例来提示LLM(GPT-3)来生成程序类似的指令及其相应的程序,从而无需为每个任务训练专门的程序生成器。
针对视觉任务的LLMs的相关工作。LLMs和情境学习已应用于视觉任务。PICa使用 LLM 来完成基于知识的 VQA任务。PICa 通过标题、对象和属性将图像中的视觉信息表示为文本,并将该文本表示与问题和上下文示例一起提供给 GPT-3,以直接生成答案。苏格拉底模型(SM),由不同模态组成预训练模型,例如语言(BERT、GPT-2)、视觉语言(CLIP)和音频语言(mSLAM),执行许多零样本任务,包括图像字幕、视频到文本检索和机器人规划。
然而,在 SM 中,每个任务的组成都是预先确定和固定的。相比之下,VISPROG 通过根据指令、问题或语句生成程序来确定如何为每个实例构建模型。我们展示了 VISPROG 处理复杂指令的能力,这些指令涉及不同的功能(20 个模块)和不同的输入(文本、图像和图像对)、中间(文本、图像、边界框、分割掩模)和输出模式(文本和图像) 。
与 VISPROG 类似,ProgPrompt 是一项并行工作,展示了LMM从自然语言指令生成类似 python 的机器人动作计划的能力。虽然 ProgPrompt 模块(例如“find”或“grab”)将字符串(通常是对象名称)作为输入,但 VISPROG 程序更为通用。在 VISPROG 程序的每个步骤中,模块可以接受先前步骤生成的多个参数,包括字符串、数字、算术和逻辑表达式或任意 Python 对象(例如包含边界框或分段掩码的 list() 或 dict() 实例) 。
3 方法(Visual Programming)
在过去的几年里,人工智能社区已经为许多视觉和语言任务(例如对象检测、分割、VQA、字幕和文本到图像生成)创建了高性能、特定于任务的模型。虽然这些模型中的每一个都解决了一个定义明确但范围狭窄的问题,但我们通常想要在现实世界中解决的任务往往更广泛且定义松散。为了解决此类实际任务,人们必须收集一个新的特定于任务的数据集,这可能会很昂贵,或者精心编写一个调用多个神经模型、图像处理子例程(例如图像调整大小、裁剪、过滤和色彩空间转换)的程序,以及其他计算(例如数据库查找,或算术和逻辑运算)。
为我们每天遇到的无限长尾的复杂任务手动创建这些程序不仅需要编程专业知识,而且速度慢、劳动强度大,最终不足以覆盖所有任务的空间。如果可以用自然语言描述任务并让人工智能系统生成并执行任务无需任何训练即可对应视觉程序似乎就可以解决问题?
3.1 Large language models for visual programming-用于可视化编程的大型语言模型。
GPT-3 等大型语言模型在上下文中进行了少量输入和输出演示后,已表现出卓越的泛化到新样本的能力。例如,用两个英语到法语的翻译示例和一个新的英语短语来提示 GPT-3产生了法语翻译“bonsoir”。请注意,我们不必微调 GPT-3 来执行第三个短语的翻译任务。VISPROG 使用 GPT-3 的上下文学习能力来输出自然语言指令的视觉程序。
good morning -> bonjourgood day -> bonne journ ́eegood evening ->与上例中的英语和法语翻译对类似,我们用指令对和所需的高级程序提示 GPT-3。图3显示了这样一个图像编辑任务的提示。上下文示例中的程序是手动编写的,通常可以在没有随附图像的情况下构建。VISPROG 程序的每一行或程序步骤均由模块名称、模块的输入参数名称及其值以及输出变量名称组成。
VISPROG 程序通常使用过去步骤的输出变量作为未来步骤的输入。我们使用描述性模块名称(例如“Select”、“ColorPop”、“Replace”)、参数名称(例如“image”、“object”、“query”)和变量名称(例如“IMAGE”、“OBJ”)让GPT-3了解各个模块的输入输出类型以及功能。在执行期间,输出变量可用于存储任意数据类型。例如,“OBJ”是图像中的对象列表,其中包含与每个对象关联的蒙版、边界框和文本(例如类别名称)。
图 3.VISPROG 中的程序生成。这些上下文示例与新的自然语言指令一起被输入到 GPT-3 中。在不观察图像或其内容的情况下,VISPROG 会生成一个程序(图 3 底部),该程序可以在输入图像上执行以执行所描述的任务。
3.2 Modules-模块介绍
VISPROG 目前支持 20 个模块(图 2),用于实现图像理解、图像处理(包括生成)、知识检索以及执行算术和逻辑运算等功能。
在 VISPROG 中,每个模块都实现为一个 Python 类(代码 1),该类具有以下方法:(i) 解析该行以提取输入参数名称和值以及输出变量名称;(ii) 执行可能涉及经过训练的神经模型的必要计算,并使用输出变量名称和值更新程序状态;(iii) 使用 html 直观地总结该步骤的计算(稍后用于创建视觉原理)。
向 VISPROG 添加新模块只需实现并注册一个模块类,而使用该模块的程序的执行则由 VISPROG 解释器自动处理,这将在下面介绍。
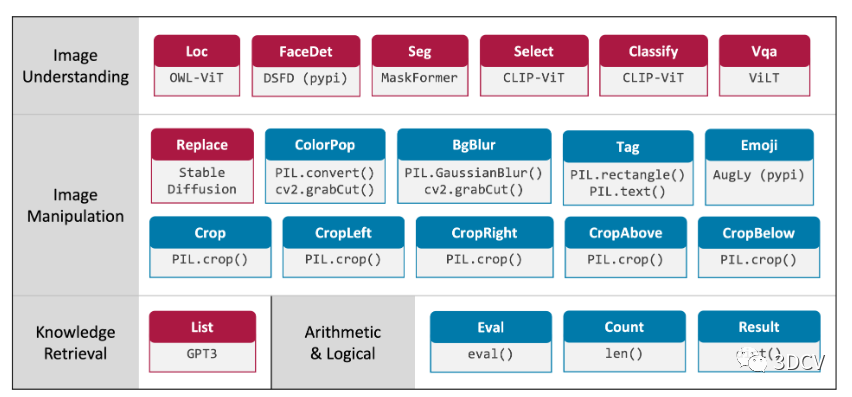
图 2. VISPROG 当前支持的模块。红色模块使用神经模型(OWL-ViT、DSFD、MaskForme、CLIP、ViLT和 Stable Diffusion)。蓝色模块使用图像处理和其他 python 子例程。这些模块在由自然语言指令生成的程序中调用。添加新模块来扩展 VISPROG 的功能非常简单(代码 1)。
classVisProgModule():
def__init__(self):
#loadatrainedmodel;movetoGPU
defhtml(self,inputs:List,output:Any):
#returnanhtmlstringvisualizingstepI/O
defparse(self,step:str):
#parsestepandreturnlistofinputvalues/variablenames
#andoutputvariablename
defexecute(self,step:str,state:Dict):
inputs,input_var_names,output_var_name=self.parse(step)
#getvaluesofinputvariablesfromstate
forvar_nameininput_var_names:
inputs.append(state[var_name])
#performcomputationusingtheloadedmodel
output=some_computation(inputs)
#updatestate
state[output_var_name]=output
#visualsummaryofthestepcomputation
step_html=self.html(inputs,output)
returnoutput,step_html
3.3 Program Execution-程序执行
程序的执行由解释器处理。解释器使用输入初始化程序状态(将变量名称映射到其值的字典),并逐行执行程序,同时使用该行中指定的输入调用正确的模块。执行每个步骤后,程序状态将使用该步骤输出的名称和值进行更新。
3.4 Visual Rationale-视觉原理
除了执行必要的计算之外,每个模块类还实现了一个名为 html() 的方法,以直观地总结 HTML 片段中模块的输入和输出。解释器只需将所有程序步骤的 HTML 摘要拼接成可视化原理(图 4),即可用于分析程序的逻辑正确性以及检查程序的内部结构的中间输出。视觉原理还使用户能够理解失败的原因,并尽可能地调整自然语言指令以提高性能。
图 4. VISPROG 生成的视觉原理。这些基本原理直观地总结了图像编辑(上)和 NLVR 任务(下)推理期间生成的程序中每个计算步骤的输入和输出。
4 Tasks-具体任务应用
VISPROG 提供了一个灵活的框架,可应用于各种复杂的视觉任务。我们在 4 项任务上评估 VISPROG,这些任务需要空间推理、多图像推理、知识检索以及图像生成和操作等能力。图 5 总结了用于这些任务的输入、输出和模块。我们现在描述这些任务、它们的评估设置以及上下文示例的选择。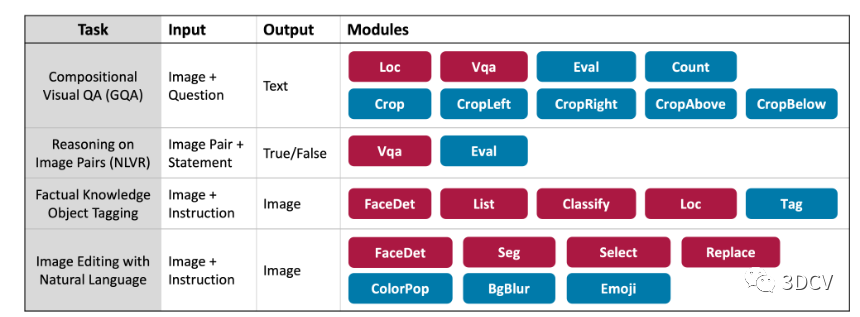
图 5.我们在一组不同的任务上评估 VISPROG。这些任务涵盖各种输入和输出,并尽可能重用模块(Loc、FaceDet、VQA)。
4.1 Compositional Visual Question Answering-组合式视觉问答
VISPROG 是组合式的,这使得它适合组合式、多步骤的视觉问答任务:GQA。GQA 任务的模块包括用于开放词汇本地化的模块、VQA 模块、给定边界框坐标或空间介词(例如上、左等)的裁剪图像区域的函数、计数框的模块以及用于计算框数量的模块。评估 Python 表达式。例如,考虑以下问题:“小卡车是在戴头盔的人的左边还是右边?”。VISPROG 首先定位“戴头盔的人”,裁剪这些人左侧(或右侧)的区域,检查该侧是否有“小卡车”,如果有则返回“左”,否则返回“右”。
VISPROG 使用基于 VILT 的问答模块,但 VISPROG 不是简单地将复杂的原始问题传递给 VILT,而是调用它来执行更简单的任务,例如识别部分图像中的内容。因此,我们生成的 GQA VISPROG 不仅比 VILT 更容易解释,而且更准确(表 1)。或者,我们可以完全消除对 ViLT 等 QA 模型的需求,并使用 CLIP 和对象检测器等其他系统,但我们将其留待未来研究。
评估。为了限制使用 GPT-3 生成程序所花费的资金,我们创建了一个 GQA 子集用于评估。GQA 中的每个问题都标有问题类型。为了评估不同的问题类型集(∼ 100 个详细类型),我们从平衡的 val (k = 5) 和 testdev (k = 20) 集中随机抽取每个问题类型最多 k 个样本。提示。我们使用所需的 VISPROG 程序手动注释平衡训练集中的 31 个随机问题。用程序注释问题很容易,需要写下回答该特定问题所需的推理链。我们向 GPT-3 提供了较小的上下文示例子集,从该列表中随机采样,以减少回答每个 GQA 问题的成本。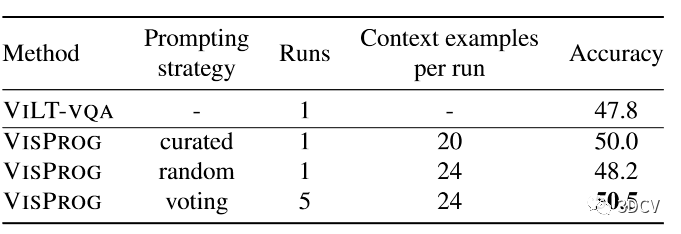
表 1.GQA 测试开发结果。我们报告原始 GQA 测试开发集的一个子集的性能
4.2 Zero-Shot Reasoning on Image Pairs-图像对上的零样本推理
VQA 模型经过训练可以回答有关单个图像的问题。在实践中,人们可能需要一个系统来回答有关图像集合的问题。例如,用户可以要求系统解析他们的假期相册并回答以下问题:“在我们看到埃菲尔铁塔的第二天,我们参观了哪个地标?”。
我们展示了 VISPROG 使用单图像 VQA 系统解决涉及多图像的任务而无需对多图像示例进行训练的能力,而不是采集昂贵的数据集并训练多图像模型。我们在 NLVRV2基准测试中展示了这种能力,其中涉及验证有关图像对的语句。通常,应对 NLVRV2 挑战需要训练自定义架构,将图像对作为 NLVRV2 训练集的输入。
相反,VISPROG 通过将复杂的语句分解为有关单个图像的简单问题和涉及算术和逻辑运算符的 Python 表达式以及图像级问题的答案来实现此目的。VQA模型VILT-VQA用于获取图像级答案,并评估python表达式以验证该语句。评估。我们通过从 NLVRV2 开发集中抽取 250 个随机样本来创建一个小型验证集,以指导提示选择,并在 NLVRV2 的完整公共测试集上测试泛化。
提示。我们针对 NLVRV2 训练集中的 16 个随机语句对 VISPROG 程序进行采样和注释。由于其中一些示例是冗余的(类似的程序结构),我们还通过删除 4 个冗余示例来创建 12 个示例的精选子集。
4.3 Factual Knowledge Object Tagging-事实知识对象标记
我们经常想要识别图像中我们不知道名字的人和物体。例如,我们可能想要识别名人、政治家、电视节目中的人物、国家国旗、公司徽标、流行汽车及其制造商、生物物种等等。解决这个任务不仅需要定位人、面孔和物体,还需要在外部知识库中查找事实知识来构建一组类别进行分类,例如电视节目中角色的名字。我们将此任务简称为事实知识对象标记或知识标记。为了解决知识标签问题,VISPROG 使用 GPT-3 作为隐式知识库,可以通过自然语言提示进行查询,例如“列出电视节目《生活大爆炸》中的主要角色,用逗号分隔。”
然后,CLIP 图像分类模块可以使用生成的类别列表,该模块对定位和人脸检测模块生成的图像区域进行分类。VISPROG 的程序生成器根据自然语言指令中的上下文自动确定是使用面部检测器还是开放词汇定位器。VISPROG 还估计检索到的类别列表的最大大小。
例如,“标记前 5 个德国汽车公司的徽标”会生成一个包含 5 个类别的列表,而“标记德国汽车公司的徽标”则会生成一个由 GPT-3 确定的任意长度的列表,截止值为 20这使得用户可以通过调整指令轻松控制分类过程中的噪声。评估。为了评估 VISPROG 在此任务上的表现,我们在 46 个图像中注释了 100 个标记指令,这些图像需要外部知识来标记 253 个对象实例,包括流行文化、政治、体育和艺术领域的人物,以及各种对象(例如汽车、旗帜、 水果、电器、家具等)。
对于每条指令,我们通过精度(正确预测框的分数)和召回率(正确预测的地面实况对象的分数)来衡量定位和标记性能。标记度量要求预测的边界框和关联的标签或类标签都是正确的,而本地化会忽略标签。为了确定定位的正确性,我们使用 IoU 阈值 0.5。我们通过 F1 分数(指令间平均精度和召回率的调和平均值)总结定位和标记性能。提示。我们为此任务创建了 14 个上下文示例。请注意,这些示例的说明是幻觉的,即没有图像与这些示例相关联。
4.4 Image Editing with Natural Language-使用自然语言进行图像编辑
文本到图像的生成在过去几年中通过 DALL-E、Parti 和 Stable Diffusion等模型取得了令人印象深刻的进步。然而,这些模型仍然无法处理诸如“用 :p 隐藏 Daniel Craig 的脸部”(去识别化或隐私保护)或“创建 Daniel Craig 的流行颜色并模糊背景”之类的提示(对象突出显示),尽管使用面部检测、分割和图像处理模块的组合以编程方式实现这些相对简单。实现复杂的编辑,例如“用戴着墨镜的巴拉克·奥巴马替换巴拉克·奥巴马”(对象替换),首先需要识别感兴趣的对象,生成要替换的对象的掩模,然后调用图像修复模型(我们使用稳定扩散) )与原始图像、指定要替换的像素的掩码以及要在该位置生成的新像素的描述。
当VISPROG配备必要的模块和示例程序时,可以轻松处理非常复杂的指令。评估。为了测试 VISPROG 的去识别、对象突出显示和对象替换的图像编辑指令,我们收集了 65 张图像中的 107 条指令。我们手动对预测的正确性和报告准确性进行评分。请注意,只要生成的图像在语义上正确,我们就不会惩罚使用稳定扩散的对象替换子任务的视觉伪影。提示。与知识标记类似,我们为此任务创建了 10 个没有关联图像的上下文示例。
5 实验与分析
我们的实验评估了提示数量对 GQA 和 NLVR 性能的影响(第 5.1 节),比较各种提示策略的 VISPROG 在四个任务上的泛化(第 5.2 节),分析每个任务的错误来源(图 9),并研究视觉原理在诊断错误和通过指令调整提高 VISPROG 性能方面的实用性(第 5.3 节)。
5.1 提示大小的影响
图 6 显示,随着 GQA 和 NLVR 提示中使用的上下文示例数量的增加,验证性能逐渐提高。每次运行都会根据随机种子随机选择带注释的上下文示例的子集。
我们还发现,对随机种子进行多数投票所带来的性能始终优于运行中的平均性能。这与数学推理问题的思想链推理文献中的发现是一致的。在 NLVR 上,VISPROG 的性能在提示数少于 GQA 的情况下达到饱和。我们认为这是因为 NLVRV2 程序比 GQA 需要更少的模块,因此使用这些模块的演示也更少。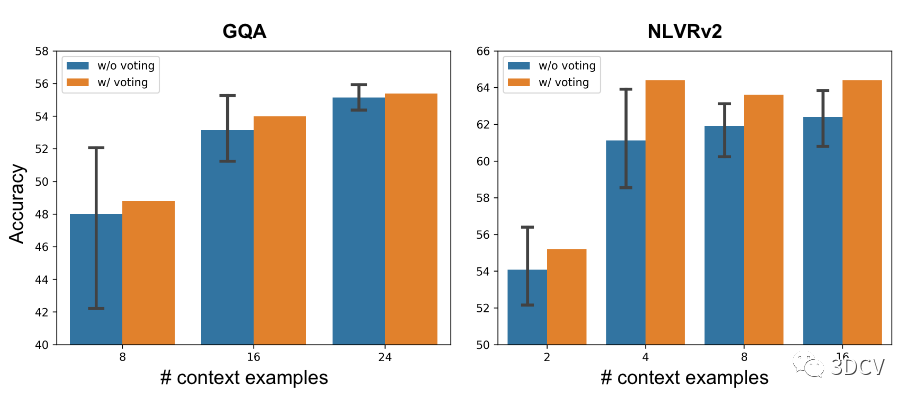
图 6. GQA 和 NLVRV2 验证集上的上下文示例数量提高了性能。误差线代表 5 次运行的 95% 置信区间。来自相同运行的预测用于多数投票。(第 5.1 节)
5.2 概括
GQA。在表1中, 我们在 GQA testdev集上评估不同的提示策略。对于在验证集上评估的最大提示大小(24 个上下文中的示例),我们比较了由 VISPROG 在验证集上的 5 次运行中选择的最佳提示组成的随机策略(每次运行从 31 个带注释的示例中随机采样上下文中的示例) )以及多数投票策略,该策略在 5 次运行中对每个问题进行最大共识预测。虽然“随机”提示仅略微优于 VILT-VQA,但投票带来了 2.7 个百分点的显着收益。这是因为在多次运行中进行投票,每次运行都有一组不同的上下文示例,有效地增加了每个预测看到的上下文示例的总数。
我们还评估了一个手动策划的提示,其中包含 20 个示例,其中 16 个来自 31 个带注释的示例,以及 4 个额外的幻觉示例,旨在更好地覆盖验证集中观察到的失败案例。精心策划的提示的性能与投票策略一样好,同时使用的计算量减少了 5 倍,凸显了提示工程的前景。NLVR。表2 显示了 VISPROG 在 NLVRV2 测试集上的性能,并比较了随机、投票和策划的提示策略与 GQA 的效果。虽然 VISPROG 在无需对图像对进行训练的情况下零样本执行 NLVR 任务,但我们报告了 VILT-NLVR,这是一种在 NLVRV2 上进行微调的 VILT 模型,作为性能上限。
虽然落后上限几个点,但 VISPROG 仅使用单图像 VQA 模型进行图像理解和 LLM 进行推理,显示出强大的零样本性能。请注意,VISPROG 使用 VILT-VQA 作为其 VQA 模块,该模块在 VQAV2 单图像问答任务上进行训练,而不是在 NLVRV2 上进行训练。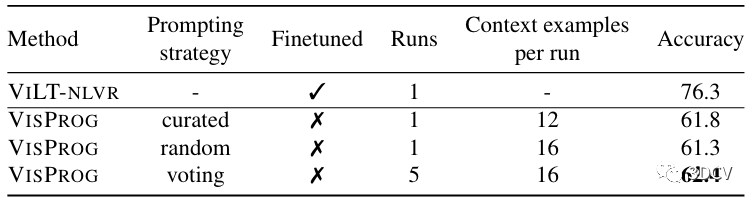
表 2. NLVRV2 测试结果。VISPROG 执行 NLVR 零样本,即无需在图像对上训练任何模块。VILT-NLVR 是在 NLVRV2 上微调的 VILT 模型,用作上限。Knowledge Tagging。表3 显示了知识标记任务的本地化和标记性能。此任务的所有指令不仅需要开放词汇本地化,还需要查询知识库以获取类别来标记本地化对象。
这使得仅靠物体检测器来说这是一项不可能完成的任务。使用原始指令,VISPROG 在标记方面取得了令人印象深刻的 63.7% F1 分数,其中涉及正确本地化和命名对象,仅在本地化方面就取得了 80.6% F1 分数。VISPROG 中的视觉原理允许通过修改指令进一步提高性能。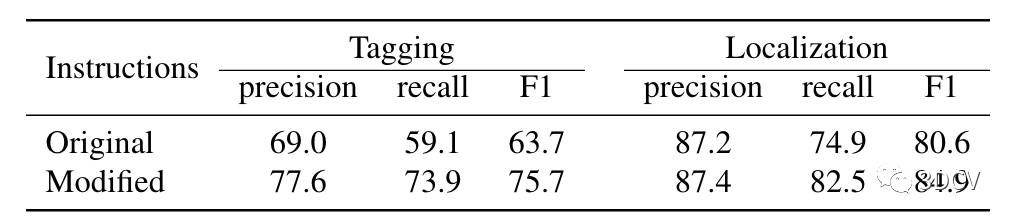
表 3. 知识标记结果。该表显示了原始指令的性能以及在检查视觉原理以了解特定于实例的错误来源后创建的修改指令的性能。Image Editing。
表4 显示了语言引导图像编辑任务的性能。图 7 显示了 VISPROG 中当前模块集可能进行的广泛操作,包括面部操作、通过颜色弹出和背景模糊等风格效果突出显示图像中的一个或多个对象,以及通过替换关键元素来更改场景上下文 在场景中(例如沙漠)。
表 4. 图像编辑结果。我们手动评估每个预测的语义正确性。
图 7. 图像编辑(顶部)和知识标记任务(底部)的定性结果。
5.3. 视觉原理的实用性
误差分析。
VISPROG 的可视化原理可以对故障模式进行彻底分析。在图 9 中,我们检查每个任务约 100 个样本的基本原理,以分解错误来源。此类分析为提高 VISPROG 在各种任务上的性能提供了明确的途径。例如,由于不正确的程序是 GQA 错误的主要来源,影响了 16% 的样本,因此可以通过提供更多类似于失败问题的上下文示例来提高 GQA 的性能。通过将用于实现高错误模块的模型升级为性能更高的模块,也可以提高性能。例如,用更好的 NLVR VQA 模型替换 VILT-VQA 模型可以将性能提高高达 24%(图 9)。同样,改进用于实现“列表”和“选择”模块(知识标记和图像编辑任务的主要错误来源)的模型可以显着减少错误。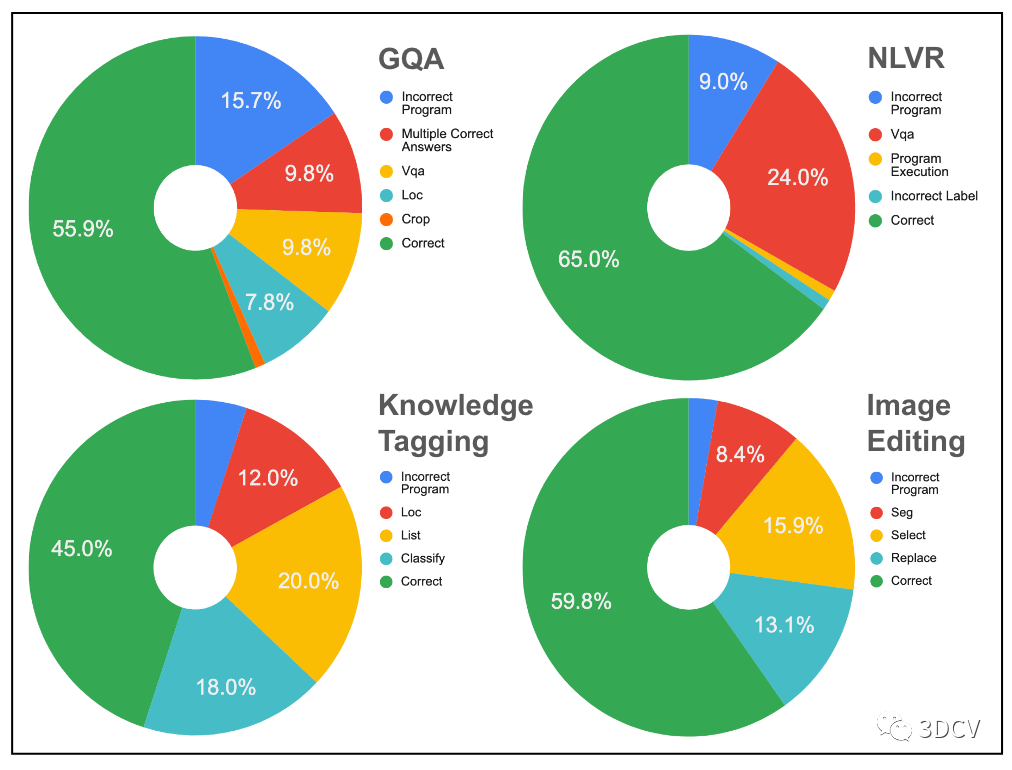
图 9. VISPROG 中的误差源。
指令调整。
为了有用,视觉原理最终必须允许用户提高系统在其任务中的性能。对于知识标记和图像编辑任务,我们研究视觉原理是否可以帮助用户修改或调整指令以实现更好的性能。图 8 显示了通过视觉原理揭示的本地化错误如何使用户能够修改指令,以便更好地查询本地化模块。修改指令的其他方式包括为知识检索提供更好的查询或为选择模块提供类别名称以将搜索限制到属于该类别的分段区域。表 3 和表 4 显示,指令调整可为知识标记和图像编辑任务带来显着收益。
图 8. 使用视觉原理调整指令。通过揭示失败的原因,VISPROG 允许用户修改原始指令以提高性能。
5 总结
VISPROG 提出可视化编程作为一种简单而有效的方式,将LMMs的推理能力用于复杂的视觉任务。VISPROG 展示了强大的性能,同时生成高度可解释的视觉原理。我们相信,研究整合用户反馈以提高 VISPROG 等神经符号系统性能的新方法是构建下一代通用视觉系统的一个令人兴奋的方向。
-
人工智能
+关注
关注
1820文章
50324浏览量
266932 -
可视化
+关注
关注
1文章
1363浏览量
22898 -
计算机视觉
+关注
关注
9文章
1715浏览量
47719
原文标题:基于文本提示就可自动实现复杂计算机视觉任务?
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
什么是计算机视觉?计算机视觉的三种方法






评论