 AI推理芯片,比你想象难!
AI推理芯片,比你想象难!

来源:内容由半导体行业观察(ID:icbank)编译自semianalysis
AI 行业讨论最多的部分是追求只能由大型科技公司开发的更大的语言模型。虽然训练这些模型的成本很高,但在某些方面部署它们更加困难。事实上,OpenAI 的 GPT-4 非常庞大且计算密集,仅运行推理就需要多台价值约 250,000 美元的服务器,每台服务器配备 8 个 GPU、大量内存和大量高速网络。谷歌对其全尺寸PaLM 模型采用了类似的方法,该模型需要 64 个 TPU 和 16 个 CPU 才能运行。Meta 2021 年最大推荐模型需要 128 个 GPU 来服务用户。越来越强大的模型世界将继续激增,尤其是在以 AI 为中心的云和 ML Ops 公司(如 MosaicML 协助企业开发和部署 LLM)的情况。
但更大并不总是更好。人工智能行业有一个完全不同的领域,它试图拒绝大型计算机。围绕可以在客户端设备上运行的小型模型展开的开源运动可能是业界讨论最多的第二部分。虽然 GPT-4 或完整 PaLM 规模的模型永远不可能在笔记本电脑和智能手机上运行,但由于内存墙,即使硬件进步了 5 年以上,也有一个面向设备端的模型开发的系统推理。在本文中,我们将在笔记本电脑和手机等客户端设备上讨论这些较小的模型。本次讨论将重点关注推理性能的门控因素、模型大小的基本限制,以及未来的硬件开发将如何在此建立开发边界。为什么需要本地模型
设备上人工智能的潜在用例广泛多样。人们希望摆脱拥有所有数据的科技巨头。Google、Meta、百度和字节跳动,AI 5 大领导者中的 4 家,其目前的全部盈利能力基本上都基于使用用户数据来定向广告。只要看看整个 IDFA 混战,就可以看出缺乏隐私对这些公司来说有多重要。设备上的 AI 可以帮助解决这个问题,同时还可以通过针对每个用户的独特对齐和调整来增强功能。
为较小的语言模型提供上 一代大型模型的性能th是 AI 在过去几个月中最重要的发展之一。
一个简单、容易解决的例子是设备上的语音到文本。这是相当糟糕的,即使是目前一流的谷歌 Pixel 智能手机也是如此。转到基于云的模型的延迟对于自然使用来说也非常刺耳,并且在很大程度上取决于良好的互联网连接。随着OpenAI Whisper等模型在移动设备上运行,设备上语音转文本的世界正在迅速变化。(谷歌 IO 还表明这些功能可能很快就会得到大规模升级。)
一个更大的例子是 Siri、Alexa 等,作为个人助理非常糟糕。在自然语音合成 AI 的帮助下,大型语言模型可以解锁更多可以为您的生活提供帮助的人类和智能 AI 助手。从创建日历事件到总结对话再到搜索,每台设备上都会有一个基于多模态语言模型的个人助理。这些模型已经比 Siri、Google Assistant、Alexa、Bixby 等功能强大得多,但我们仍处于早期阶段。
在某些方面,生成式人工智能正迅速成为一种双峰分布,具有大量的基础模型和可以在客户端设备上运行的小得多的模型,获得了大部分投资,并且两者之间存在巨大鸿沟。设备上推理的基本限制
虽然设备上人工智能的前景无疑是诱人的,但有一些基本的限制使得本地推理比大多数人预期的更具挑战性。绝大多数客户端设备没有也永远不会有专用 GPU,因此所有这些挑战都必须在 SoC 上解决。主要问题之一是 GPT 样式模型所需的大量内存占用和计算能力。计算要求虽然很高,但在未来 5 年内将通过更专业的架构、摩尔定律扩展到 3nm/2nm 以及芯片的 3D 堆叠来迅速解决。
由于英特尔、AMD、苹果、谷歌、三星、高通和联发科等公司正在进行的架构创新,最高端的客户端移动设备将配备约 500 亿个晶体管和超过足够的 TFLOP/s 用于设备上的人工智能,需要明确的是,他们现有的客户端 AI 加速器中没有一个非常适合 Transformer,但这将在几年内改变。芯片数字逻辑方面的这些进步将解决计算问题,但它们无法解决内存墙和数据重用的真正根本问题。
GPT 风格的模型被训练为在给定先前标记的情况下预测下一个标记(~= 单词)。要用它们生成文本,你需要给它提示,然后让它预测下一个标记,然后将生成的标记附加到提示中,然后让它预测下一个标记,然后继续。为此,您必须在每次预测下一个标记时将所有参数从 RAM 发送到处理器。第一个问题是您必须将所有这些参数存储在尽可能靠近计算的地方。另一个问题是您必须能够在需要时准确地将这些参数从计算加载到芯片上。
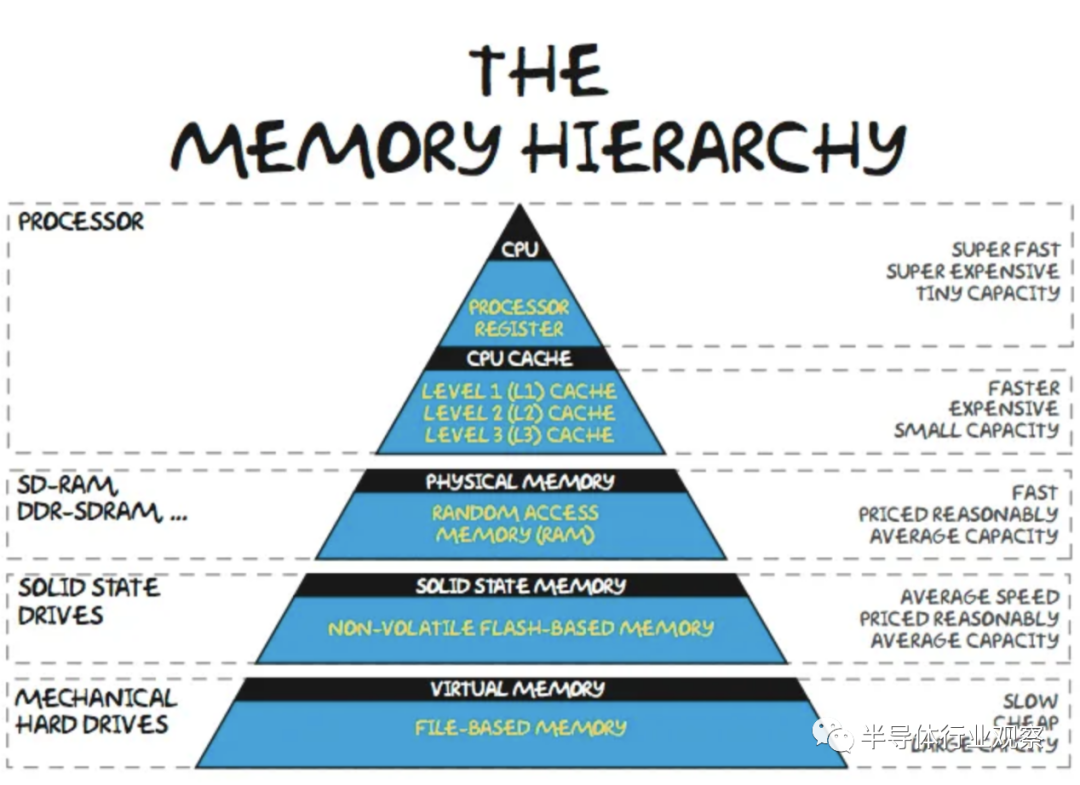
在内存层次结构中,在芯片上缓存频繁访问的数据在大多数工作负载中很常见。对于设备上的 LLM,这种方法的问题在于参数占用的内存空间太大而无法缓存。以 FP16 或 BF16 等 16 位数字格式存储的参数为 2 个字节。即使是最小的“体面”通用大型语言模型也是 LLAMA,至少有 70 亿个参数。较大的版本质量明显更高。要简单地运行此模型,需要至少 14GB 的内存(16 位精度)。虽然有多种技术可以减少内存容量,例如迁移学习、稀疏化和量化,但这些技术并不是免费的,而且会影响模型的准确性。
此外,这 14GB 忽略了其他应用程序、操作系统以及与激活/kv 缓存相关的其他开销。这直接限制了开发人员可以用来部署设备上 AI 的模型大小,即使他们可以假设客户端端点具有所需的计算能力。在客户端处理器上存储 14GB 的参数在物理上是不可能的。最常见的片上存储器类型是 SRAM,即使在 TSMC 3nm 上,每 100mm^2 也只有约 0.6GB.
作为参考,这与即将推出的 iPhone 15 Pro 的 A17 芯片尺寸大致相同,比即将推出的 M3 小约 25%。此外,该图没有来自辅助电路、阵列低效、NOC 等的开销。大量本地 SRAM 将无法用于客户端推理。诸如 FeRAM 和 MRAM 之类的新兴存储器确实为隧道尽头的曙光带来了一些希望,但它们距离千兆字节规模的产品化还有很长的路要走。
层次结构的下一层是 DRAM。最高端的 iPhone 14 Pro Max 有 6GB 内存,但常用 iPhone 有 3GB 内存。虽然高端 PC 将拥有 16GB+,但大多数新销售的 RAM 为 8GB。典型的客户端设备无法运行量化为 FP16 的 70 亿参数模型!
这就提出了问题。为什么我们不能在层次结构中再往下一层?我们能否在基于 NAND 的 SSD 而不是 RAM 上运行这些模型?
不幸的是,这太慢了。FP16 的 70 亿参数模型需要 14GB/s 的 IO 才能将权重流式传输以生成 1 个token(~4 个字符)!最快的 PC 存储驱动器最多为 6GB/s,但大多数手机和 PC 都低于 1GB/s。在 1GB/s 的情况下,在 4 位量化下,可以运行的最大模型仍将仅在约 20 亿个参数的范围内,这是在不考虑任何其他用途的情况下将 SSD 固定在最大值上仅用于 1 个应用案例。
除非你想在普通设备上等待 7 秒才能吐出半个字,否则将参数存储在存储器中不是一种选择。它们必须在 RAM 中。
模型尺寸限制
一般人每分钟阅读约 250 个单词。作为良好用户体验的下限,设备上的 AI 必须每秒生成 8.33 个tokens,或每 120 毫秒生成一次。熟练的速度读者可以达到每分钟 1,000 个单词,因此对于上限,设备上的 AI 必须能够每秒生成 33.3 个tokens,或每 30 毫秒一次。下表假定平均阅读速度的下限,而不是速读。
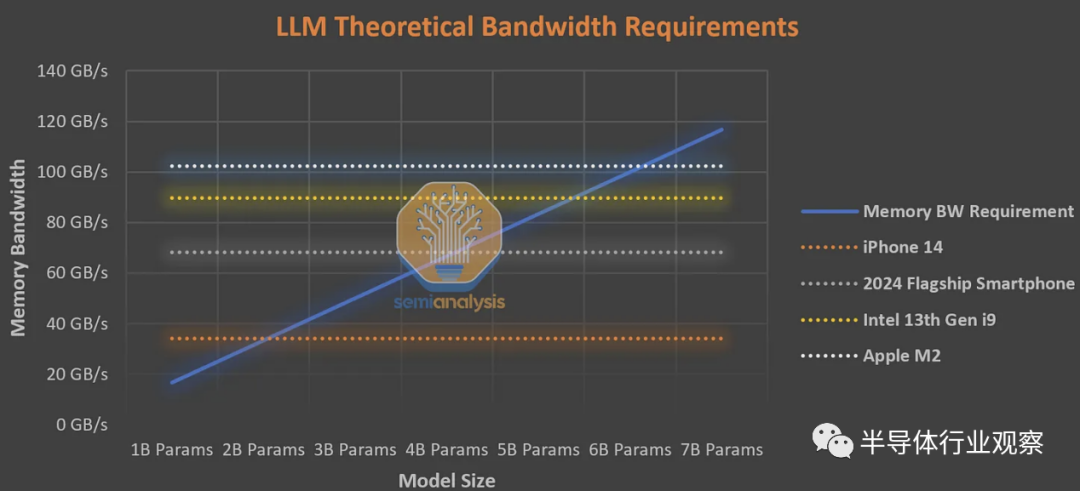
如果我们保守地假设正常的非 AI 应用程序以及激活/kv 缓存消耗所有带宽的一半,那么 iPhone 14 上最大的可行模型大小是约 10 亿个 FP16 参数,或约 40 亿个 int4 参数。这是基于智能手机的 LLM 的基本限制。任何更大的产品都会排除很大一部分安装基础,以至于无法采用。
这是对本地 AI 可以变得多大和强大的基本限制。或许像苹果这样的公司可以利用它来追加销售更新、更昂贵、配备更先进人工智能的手机,但这还有一段时间。根据与上述相同的假设,在 PC 上,英特尔的顶级第 13 代CPU 和苹果的 M2 的上限约为 30 到 40 亿个参数。
一般来说,这些只是消费设备的下限。重复一遍,我们忽略了多个因素,包括使用理论 IO 速度(这是从未达到过的)或为简单起见激活/kv 缓存。这些只会进一步提高带宽要求,并进一步限制模型尺寸。我们将在下面详细讨论明年将出现的创新硬件平台,这些平台可以帮助重塑格局,但内存墙限制了大多数当前和未来的设备。为什么服务器端 AI 获胜
由于极端的内存容量和带宽要求,生成式 AI比之前的任何其他应用程序更受内存墙的影响。在客户端推理中,对于生成文本模型,批量大小(batch size)几乎始终为 1。每个后续标记都需要输入先前的标记/提示,这意味着每次从内存中将参数加载到芯片上时,您只需摊销成本仅为 1 个生成的token加载参数。没有其他用户可以传播这个瓶颈。内存墙也存在于服务器端计算中,但每次加载参数时,它都可以分摊到为多个用户生成的多个tokens(批量大小:batch size)。
我们的数据显示,HBM 内存的制造成本几乎是服务器级 AI 芯片(如 H100 或 TPUv5)的一半。虽然客户端计算确实可以使用便宜得多的 DDR 和 LPDDR 内存(每 GB 约 4 倍),但内存成本无法通过多个并发推理进行分摊。批量大小不能无限大,因为这会引入另一个难题,即任何单个token都必须等待所有其他token处理完毕,然后才能附加其结果并开始生成新token。
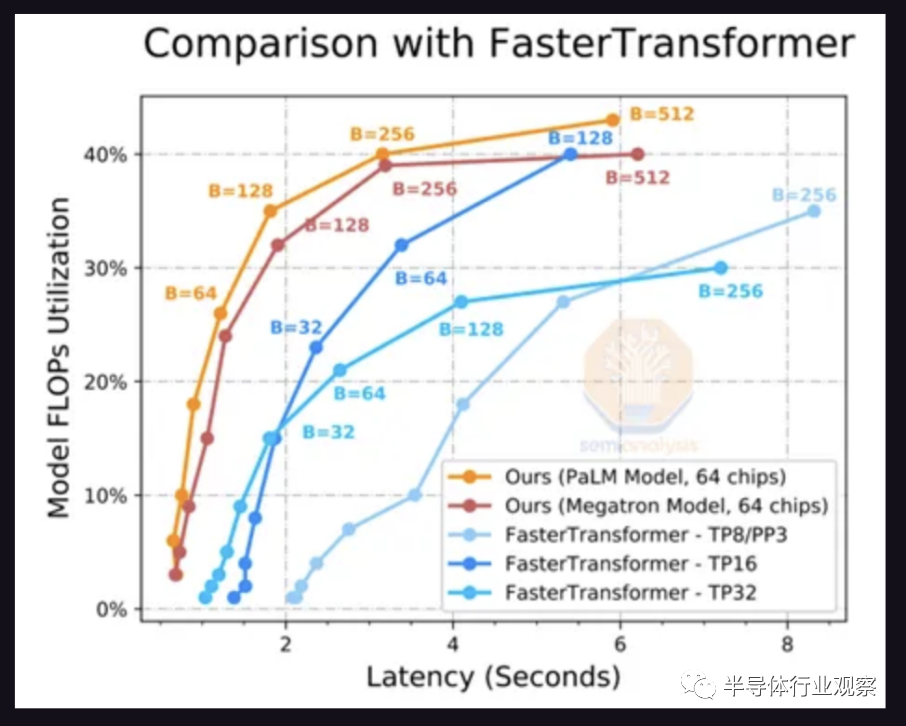
这是通过将模型拆分到多个芯片来解决的。上图是生成 20 个token的延迟。方便的是,PaLM 模型达到每秒 6.67 个标记,或每分钟约 200 个单词的最小可行目标,其中 64 个芯片以 256 的批大小运行推理。这意味着每次加载参数时,它会用于 256 个不同的推论。
FLOPS 利用率随着批处理大小的增加而提高,因为FLOPS ,内存墙正在得到缓解。只有将工作分配到更多芯片上,才能将延迟降低到一个合理的水平。即便如此,也只有 40% 的 FLOPS 被使用。谷歌展示了 76% 的 FLOPS 利用率,PaLM 推理的延迟为 85.2 秒,因此 so 内存墙显然仍然是一个重要因素。
所以服务器端的效率要高得多,但是本地模型可以扩展到什么程度呢?
-
芯片
+关注
关注
463文章
54375浏览量
468986 -
AI
+关注
关注
91文章
40926浏览量
302511
发布评论请先 登录
高通挑战英伟达,发布768GB内存AI推理芯片,“出征”AI数据中心

高通挑战英伟达!发布768GB内存AI推理芯片,“出征”AI数据中心

国内首个国产AI推理千卡集群落地,采用云天励飞全自研AI推理芯片
把大模型“刻进”芯片,AI芯片推理速度17000 tokens/秒

AI推理芯片需求爆发,OpenAI欲寻求新合作伙伴
使用NORDIC AI的好处
欧洲之光!5nm,3200 TFLOPS AI推理芯片即将量产

AI推理需求爆发!高通首秀重磅产品,国产GPU的自主牌怎么打?

什么是AI模型的推理能力
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片到AGI芯片
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI的科学应用
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片的需求和挑战
华为亮相2025金融AI推理应用落地与发展论坛
AI推理芯片赛道猛将,200亿市值AI芯片企业赴港IPO



评论