 AWS为什么过去和现在要做芯片和硬件自研这些事情
AWS为什么过去和现在要做芯片和硬件自研这些事情

编者按去年的AWS re:Invent 2021有很多跟芯片相关的内容值得展开来说的事情。但网上已经有很多专业的文章了,我就不再班门弄斧一一介绍了。只好另辟蹊径,尝试从整体和发展的角度,和一些“可能存在”的“向左(定制)还是向右(通用)”的权衡,来分析一下AWS为什么过去和现在要做芯片和硬件自研这些事情,以及未来要往何处去。再次强调一下,芯片定制分为两个方面:芯片功能的定制还是通用,是个技术路径的问题;巨头通过定制芯片,满足自身需求,这是一个商业选择的问题。这两者不能混淆。
1 硬件定制
硬件定制可以简单地分为两种模式:-
由外而内。从通用的服务器等硬件出发,进一步优化(裁剪和增强)数据中心各种硬件产品,落地成标准化的硬件和系统设计,再通过规模化的部署,来达到降低成本的目的。例如,OCP倡导的各种OCP兼容的服务器、交换机及其他硬件设计。
-
由内而外。从内在的业务场景需求出发,通过软硬件深层次的协同优化设计,落地到个性化的硬件定制。各家互联网云计算公司,如AWS、微软和阿里云等,主要用于自身业务的各种硬件定制产品。
 (a) AWS定制交换机
(a) AWS定制交换机 (b) AWS定制SDN网卡图1 AWS定制网络设备如果采用标准的商用路由器,出现问题,供应商最快需要花费六个月时间来修复问题。如图1(a),AWS根据自己的软硬件规格定义定制路由器,并且拥有自己的协议开发团队。虽然一开始的诉求主要是降低成本,但实际上最终的结果是,定制的网络设备不仅仅降低了成本,最大的收获是网络可靠性。AWS路由器采用的是AWS和博通(Broadcom)联合定制的具有70亿晶体管规模的ASIC芯片,总的处理带宽为3.2Tbit/s(数据来自AWS Re:Invent 2016)。AWS网络策略的另一个关键部分是SDN,AWS将SDN的其中一部分工作从软件卸载到硬件。如图1(b),通过硬件卸载网络功能,降低了CPU的资源消耗,并且降低了网络延迟以及网络的性能抖动。
(b) AWS定制SDN网卡图1 AWS定制网络设备如果采用标准的商用路由器,出现问题,供应商最快需要花费六个月时间来修复问题。如图1(a),AWS根据自己的软硬件规格定义定制路由器,并且拥有自己的协议开发团队。虽然一开始的诉求主要是降低成本,但实际上最终的结果是,定制的网络设备不仅仅降低了成本,最大的收获是网络可靠性。AWS路由器采用的是AWS和博通(Broadcom)联合定制的具有70亿晶体管规模的ASIC芯片,总的处理带宽为3.2Tbit/s(数据来自AWS Re:Invent 2016)。AWS网络策略的另一个关键部分是SDN,AWS将SDN的其中一部分工作从软件卸载到硬件。如图1(b),通过硬件卸载网络功能,降低了CPU的资源消耗,并且降低了网络延迟以及网络的性能抖动。 (a) AWS定制芯片
(a) AWS定制芯片 (b) AWS定制计算服务器
(b) AWS定制计算服务器 (c) AWS定制存储服务器图2 AWS定制芯片及服务器如图2(a),2015年AWS收购了Annapurna labs公司,之后Annapurna labs设计并生产了AWS定制芯片,可用于AWS各类定制服务器。AWS不仅仅定制硬件(板卡及服务器),也定制自己的芯片。通过芯片定制,可以更好地实现AWS对数据中心的各种创新。如图2(b),AWS定制1U的服务器,因此其在机架上会占满1U的槽位。没有采用更密集的在1U的槽位集成更多的服务器节点的做法,这样做是为了提高热效率和功率效率。如图2(c),AWS自定义的存储服务器在一个42U标准的机架上部署880块磁盘,升级后的存储服务器可以容纳1110块磁盘,存储容量为11 PB(数据来自AWS的Re:Invent 2016)。
(c) AWS定制存储服务器图2 AWS定制芯片及服务器如图2(a),2015年AWS收购了Annapurna labs公司,之后Annapurna labs设计并生产了AWS定制芯片,可用于AWS各类定制服务器。AWS不仅仅定制硬件(板卡及服务器),也定制自己的芯片。通过芯片定制,可以更好地实现AWS对数据中心的各种创新。如图2(b),AWS定制1U的服务器,因此其在机架上会占满1U的槽位。没有采用更密集的在1U的槽位集成更多的服务器节点的做法,这样做是为了提高热效率和功率效率。如图2(c),AWS自定义的存储服务器在一个42U标准的机架上部署880块磁盘,升级后的存储服务器可以容纳1110块磁盘,存储容量为11 PB(数据来自AWS的Re:Invent 2016)。2 虚拟化卸载和Nitro DPU芯片
2.1 AWS EC2虚拟化技术的演进
在介绍虚拟化演进之前,我们先介绍下虚拟化的三种方式:-
完全软件虚拟化(Virt. in Software, VS):支持不需要修改的客户机OS,所有的操作都被软件模拟,但性能消耗高达50%-90%。
-
类虚拟化(Para-Virt., PV):客户机OS通过修改内核和驱动,调用Hypervisor提供的hypercall,客户机和Hypervisor共同合作,让模拟更高效。类虚拟化性能消耗大概为10%-50%。
-
完全硬件虚拟化(Virt. in Hardware, VH):硬件支持虚拟化,性能接近裸机,只有0.1%-1.5%的虚拟化消耗。
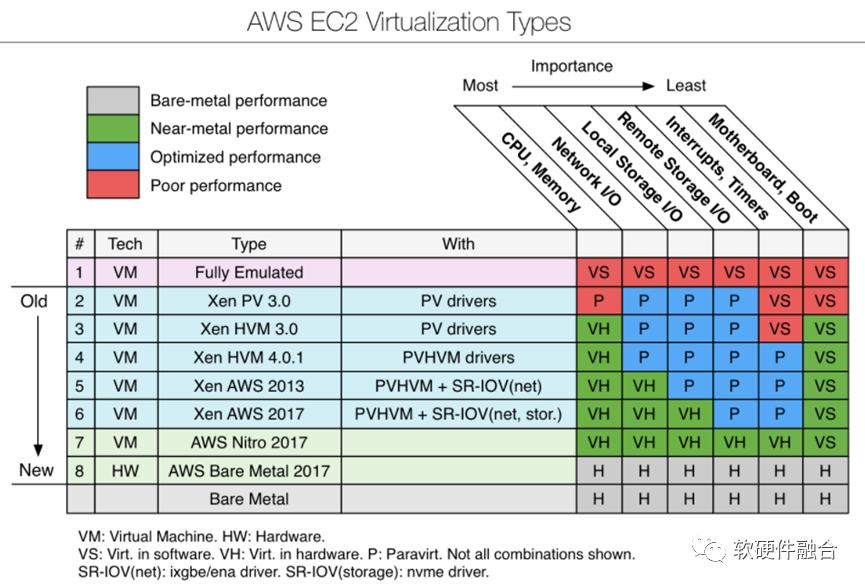 图3 AWS EC2虚拟化技术演进图3是AWS“教科书”般的虚拟化迭代优化的演进示意图。我们只关注与性能最相关的CPU/Mem、网络I/O、本地存储I/O、远程存储I/O四类计算机资源。大致的演进介绍如下:
图3 AWS EC2虚拟化技术演进图3是AWS“教科书”般的虚拟化迭代优化的演进示意图。我们只关注与性能最相关的CPU/Mem、网络I/O、本地存储I/O、远程存储I/O四类计算机资源。大致的演进介绍如下:-
最开始,所有的计算机资源都是纯软件模拟的。
-
Xen PV 3.0引入了PV,部分提升了性能。
-
Xen HVM 3.0引入了CPU和内存的硬件虚拟化(基于Intel VT-x和AMD-v技术),大幅度提升了性能;这一时期,网络和存储I/O对处理带宽的要求还不高,PV的I/O虚拟化还是满足要求的。
-
Xen HVM 4.0.1,没有优化四个主要的资源,性能提升不算明显。
-
Xen AWS 2013,通过PCIe SR-IOV技术,正式引入了网络I/O硬件虚拟化。
-
Xen AWS 2017,通过PCIe SR-IOV技术,正式引入了本地存储I/O硬件虚拟化。
-
2017年,AWS Nitro 2017。Nitro项目正式登场。站在I/O虚拟化的角度,NITRO项目的创新有限。NITRO最有价值的创新在于把Backend的网络和远程存储的Workload卸载到了NITRO卡上。从Nitro开始,云计算架构就走上了业务和基础设施在物理上完全隔离的路子。
-
AWS Bare Metal 2017。裸金属机器和用于EC2虚拟机的Nitro 2017最大的区别在于有没有一层Lite Hypervisor。
2.2 Nitro DPU芯片的演进
严格来说,2017年底AWS宣布的Nitro系统是全球第一家真正商业落地的DPU芯片。AWS引领了DPU的潮流,随后DPU这个方向才逐渐火热了起来。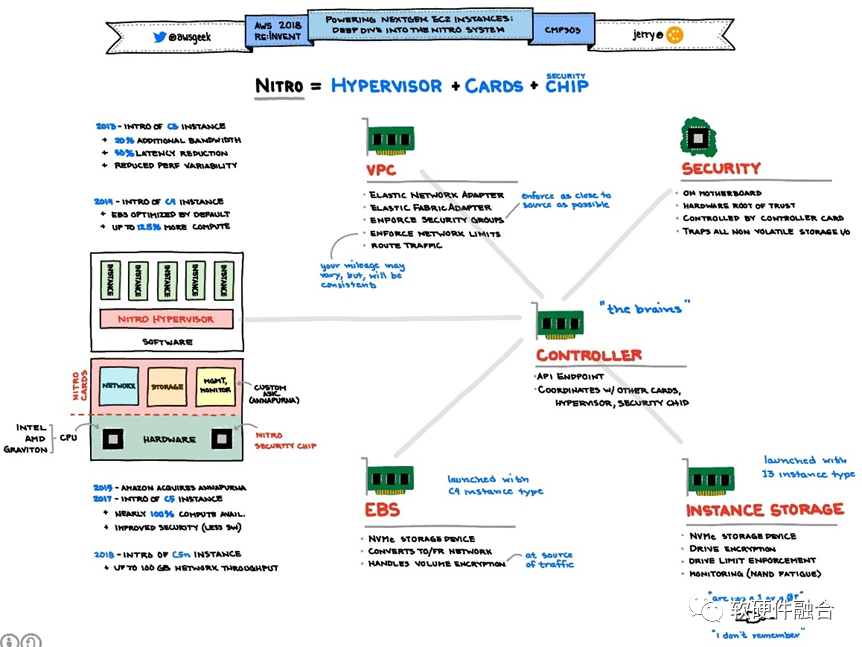 图4 AWS Nitro系统如图4所示,不同的EC2服务器实例类型包括不同的Nitro系统特性,一些服务器类型有许多Nitro系统卡,实现AWS Nitro系统的五大主要特性:
图4 AWS Nitro系统如图4所示,不同的EC2服务器实例类型包括不同的Nitro系统特性,一些服务器类型有许多Nitro系统卡,实现AWS Nitro系统的五大主要特性:-
Nitro VPC(虚拟私有云)卡;
-
Nitro EBS(弹性块存储)卡;
-
Nitro本地存储卡;
-
Nitro控制器卡;
-
Nitro安全芯片。
-
CPU性能弱,一张不够,就多张卡整合到一起完成想要的功能;
-
CPU完全可编程,同样的芯片,同样的板卡,只需要后期运行不同的软件,就可以非常方便的实现不同的功能。
-
做到了把VM的业务和宿主机侧的管理任务完全隔离,这样提供了很多安全方面的好处,并且可以打平虚拟机和物理机环境。业务和管理分离,还有很多其他好处,这里不一一展开了。
-
因为是嵌入式的CPU,所以,可以快速地开发新功能。例如基于Nitro嵌入式CPU,开发了SRD和EFA,为高性能的HPC提供解决方案。快速地为业务提供更强大的功能和服务价值,给客户提供更加快速而积极的功能支持,是云计算的核心竞争力。虽然消耗Nitro卡的资源多一些,但这些可以留待后续持续优化。
2.3 AWS Nitro与NVIDIA DPU的本质区别
看2.2节的内容,很多人可能会认为,Nitro采用CPU设计,AWS的设计水平有限。为什么不像NVIDIA一样,集成各种ASIC的加速引擎呢?还有一个类似的问题,在手机端,集成各种专用硬件加速引擎的手机SOC芯片已经非常成熟,但为什么数据中心的计算平台依然是以CPU为主?原因只有一个:数据中心场景,对软件灵活性的要求,远高于对性能的要求。如果不能提供灵活性(或者说易用性、可编程性),提供再多的性能都是“无本之木”。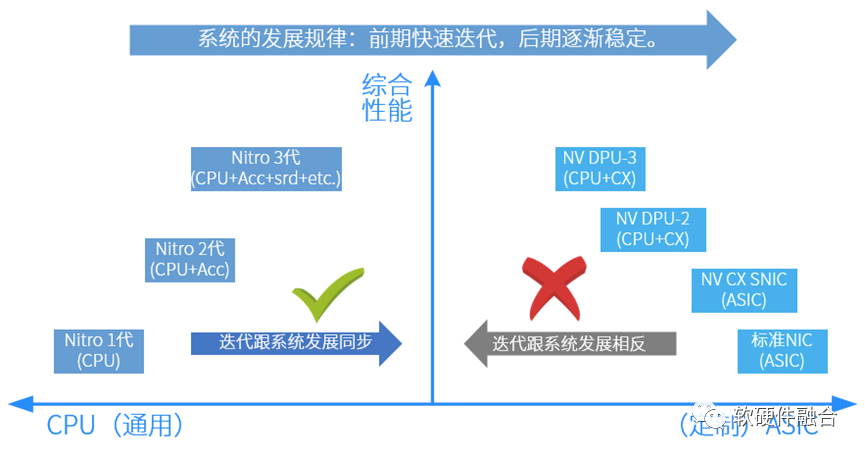 图4 Nitro和NVIDIA DPU的演进对比互联网云计算厂家的上层软件业务逻辑各不相同并且快速迭代,这几乎无法采用定制的ASIC设计。简而言之:定制的ASIC很难适合灵活多变的云场景。如图4所示,芯片公司(NVIDIA)根据自身对业务的理解,做定制ASIC。但这些ASIC实现的加速功能是芯片公司对业务场景的理解,并把业务逻辑固化到定制的设计中,使得云厂家很难基于此硬件平台开发出差异化的创新功能。并且,定制的设计,限制了云厂家的创新能力,并且使得云场景不得不跟硬件平台厂家深度绑定,这些对云厂家来说,并不是一件好事。如图4所示,AWS Nitro和NVIDIA DPU是两种不同方向的演进:
图4 Nitro和NVIDIA DPU的演进对比互联网云计算厂家的上层软件业务逻辑各不相同并且快速迭代,这几乎无法采用定制的ASIC设计。简而言之:定制的ASIC很难适合灵活多变的云场景。如图4所示,芯片公司(NVIDIA)根据自身对业务的理解,做定制ASIC。但这些ASIC实现的加速功能是芯片公司对业务场景的理解,并把业务逻辑固化到定制的设计中,使得云厂家很难基于此硬件平台开发出差异化的创新功能。并且,定制的设计,限制了云厂家的创新能力,并且使得云场景不得不跟硬件平台厂家深度绑定,这些对云厂家来说,并不是一件好事。如图4所示,AWS Nitro和NVIDIA DPU是两种不同方向的演进:-
NVIDIA DPU演进:从硬到软,NIC -> SNIC -> DPU(DPU = SNIC+嵌入式CPU);定制设计,客户无法差异化,与云系统发展规律相悖。
-
AWS Nitro演进:从软到硬,CPU基础上,逐步增加足够弹性的加速引擎;通用的设计,符合云系统发展规律。
3 Graviton CPU,跟Nitro走向不同的方向
3.1 Graviton CPU的演进
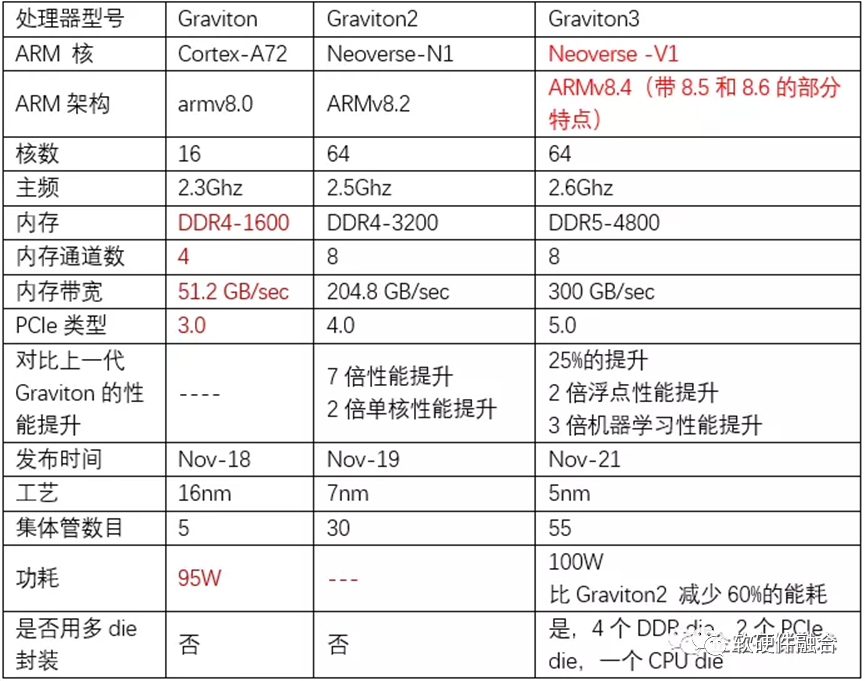 图5 Winnie Shao博士总结的Graviton CPU的3代演进在AWS re:Invent 2021大会上,AWS发布了最新一代的ARM CPU芯片Graviton 3。相比2018年发布的Graviton 1和2019年发布Graviton 2,有了很大的改进。话不多说,直接上图。如图5所示,Winnie Shao博士是CPU领域的专家,她总结的这个表格已经非常完善了,我就不再班门弄斧了。
图5 Winnie Shao博士总结的Graviton CPU的3代演进在AWS re:Invent 2021大会上,AWS发布了最新一代的ARM CPU芯片Graviton 3。相比2018年发布的Graviton 1和2019年发布Graviton 2,有了很大的改进。话不多说,直接上图。如图5所示,Winnie Shao博士是CPU领域的专家,她总结的这个表格已经非常完善了,我就不再班门弄斧了。3.2 Graviton CPU和Nitro DPU的渊源
第一代Nitro是在AWS re:Invent 2017上发布的,初代Nitro本质是一款CPU芯片。随后一年,re:Invent 2018发布了Nitro 2代以及Graviton 1代ARM CPU芯片。我们大约可以推断,Nitro 2主要升级了CPU的性能,Nitro 2代和Graviton CPU 1代是比较接近同一款芯片的设计。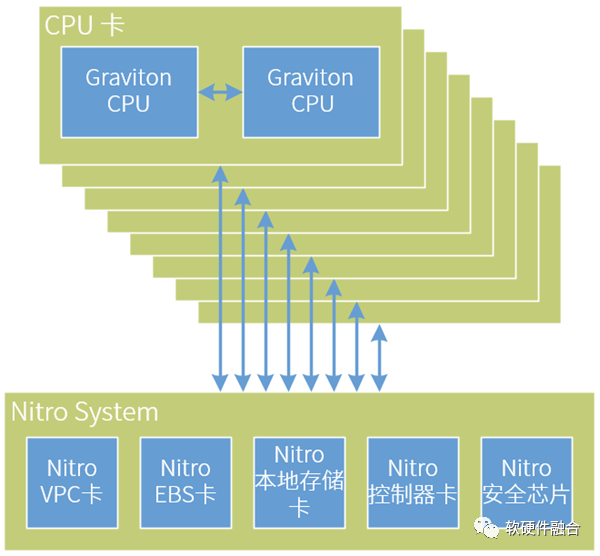 图6 推测的AWS ARM服务器架构示意图由于ARM CPU核的单核性能相比x86 CPU核仍有差距,要想更好地实现降成本的目标,势必需要在ARM服务器的高计算密度方面做文章。如图6所示,这是我们推测的ARM服务器内部架构,也只有这样,Nitro System组成一个平台化的系统,提供Multi-Host的机制给到CPU,可以支持4-8块CPU计算节点。这样,可以在单台服务器规模,最多容纳16颗ARM CPU。更极端的推测,如果Graviton和Nitro是同一颗芯片的话,AWS ARM服务器相当于包含了21颗CPU芯片。
图6 推测的AWS ARM服务器架构示意图由于ARM CPU核的单核性能相比x86 CPU核仍有差距,要想更好地实现降成本的目标,势必需要在ARM服务器的高计算密度方面做文章。如图6所示,这是我们推测的ARM服务器内部架构,也只有这样,Nitro System组成一个平台化的系统,提供Multi-Host的机制给到CPU,可以支持4-8块CPU计算节点。这样,可以在单台服务器规模,最多容纳16颗ARM CPU。更极端的推测,如果Graviton和Nitro是同一颗芯片的话,AWS ARM服务器相当于包含了21颗CPU芯片。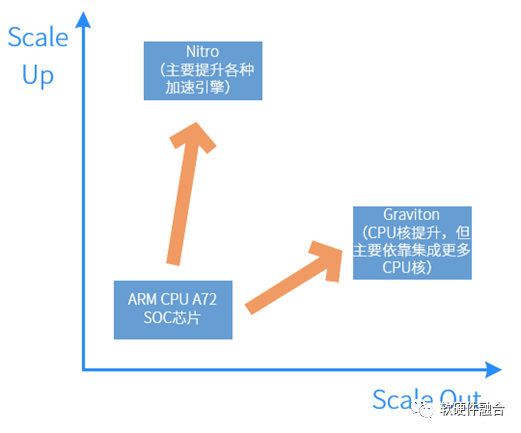 图7 Graviton和Nitro的演进区别如图7所示,Graviton和Nitro可以说“同宗同源,师出同门”,但却因为分工和定位的不同,逐渐走向了两个不同的方向:
图7 Graviton和Nitro的演进区别如图7所示,Graviton和Nitro可以说“同宗同源,师出同门”,但却因为分工和定位的不同,逐渐走向了两个不同的方向:-
Graviton的Scale Out模式。Graviton定位为主CPU。势必需要提供更加强大的单核性能以及提供更高的水平扩展性,也就是说单芯片要集成更多的CPU核,以及要支持多CPU的跨芯片缓冲一致性互联。
-
Nitro的Scale Up模式。Nitro的主要工作是卸载、隔离和加速。只隔离和卸载,不解决本质问题,只有通过硬件加速才真正实现性能提升和成本降低。所以,Nitro的演进,势必走向通过硬件加速,疯狂地提升单芯片的处理性能的路子上。
4 应用加速芯片
4.1 CPU、DPU和GPU/FPGA/DSA
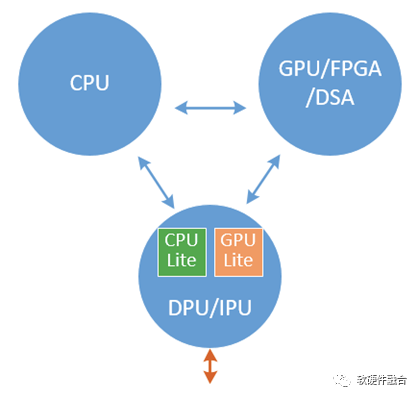 图8 CPU、GPU/FPGA/DSA以及DPU的关系如图CPU、GPU/FPGA/DSA和DPU,三者的关系就像《三体》描述的那样,既相互协作,又相互竞争,最终达到一个相对稳定的状态:
图8 CPU、GPU/FPGA/DSA以及DPU的关系如图CPU、GPU/FPGA/DSA和DPU,三者的关系就像《三体》描述的那样,既相互协作,又相互竞争,最终达到一个相对稳定的状态:-
DPU主要定位基础设施层的加速和处理;
-
GPU/FPGA/DSA主要负责应用层的加速;
-
CPU负责应用层的常规处理。
-
GPU加速的云主机。例如,AWS EC2 P3实例可以提供高性能的计算,可支持高达8个 NVIDIA V100 GPU,可为机器学习、HPC等应用提供高达100Gbps的网络吞吐量。
-
FPGA加速的云主机。例如,AWS EC2 F1实例使用FPGA实现自定义硬件加速交付。
-
DSA/ASIC加速的云主机。例如,AWS EC2 Inf1实例可在云端提供高性能和最低成本的机器学习推理。这些实例具有多达16个AWS Inferentia芯片,这是由AWS设计和打造的高性能机器学习推理芯片。
4.2 为什么要为特定场景定制芯片
AWS发布了Inferentia定制芯片,它不像Graviton这样的通用CPU处理器什么都能干,而是专注于机器学习推理。通用CPU处理器可以支持足够广泛的各种工作负载类别,当然也包括机器学习推理,为什么还要开发特定工作负载的专用处理器?的确,通用CPU处理器多年来一直承担着绝大部分的工作负载,CPU数量非常庞大,因此单位的成本可以做到比较低。低成本的优势可以抵消为特定工作负载芯片定制的优势。当只有少量服务器运行特定工作负载时,很难从经济上证明芯片定制优化是合算的。在计算领域之外,芯片定制在网络领域大放异彩。网络数据包处理是高度专业化的,网络协议很少更改。数量足够大,定制就非常的经济。因此,大多数网络数据包处理是使用ASIC芯片完成的。大多数路由器,无论来源如何,基本都是建立在专门的ASIC之上的。虽然,定制ASIC硬件可以将延迟、性能价格比以及性能功耗比提高高达十倍。但是,这么多年以来,大多数的计算工作负载仍“顽强”地停留在通用CPU处理器上。通常,每个客户服务器数量不多,芯片定制通常意义不大。但是,云计算改变了这一切。在成功且广泛使用的云中,即使是“稀有”工作负载,其数量也可能达到数千甚至数万。过去,作为企业,几乎不可能证明芯片定制,针对特定工作负载的加速处理,是足够经济的。但在云中,有成千上万足够罕见的工作负载。突然之间,不仅可以针对特定工作负载类型进行硬件的优化,而且如果不这样做,反而显得有点“不够积极”。在很多情况下,芯片定制不仅仅可以把成本降低一个数量级,电量消耗减少到1/10,并且这些定制化的方案可以给客户以更低的延迟提供更好的服务。定制的芯片将成为未来服务器端计算的重要组成部分,亚马逊自2015年初以来就有一个专注于AWS的芯片定制团队,在此之前,AWS与合作伙伴合作构建专业化解决方案。在re:Invent 2016大会上,AWS发布了一款安装在所有服务器中的定制芯片(James Hamilton的星期二夜现场,Nitro的前身)。尽管这是一个非常专业的定制芯片,但AWS每年安装的此类定制芯片超过一百万,而且这个数字还在继续增加。在服务器领域,它实际上是一个销量非常大的芯片了。机器学习工作负载需要的服务器资源将比当前所有形式的服务器计算的总和还要多。机器学习的客户价值几乎适用于每个领域,潜在收益非常巨大。机器学习几乎可以立即适用于所有业务,包括客户服务、保险、金融、供暖/制冷以及制造。一项技术很少有像机器学习一样如此广泛的应用,当收益如此之大时,这对大多数企业来说就是一种赛跑。那些最先深入应用机器学习的人或组织可以更有效、更经济地为客户服务。AWS专注于让机器学习的快速部署变得更加容易,同时降低成本,让更多的工作负载可以更经济地使用机器学习。规模和针对特定场景的优化,是Inferentia等工作负载专用加速芯片发展的最本质的驱动力量。未来,在大型数据中心,除了AI训练和推理芯片,也会出现很多面向其他工作负载,如视频图像处理、大数据分析、基因组学、电子设计自动化 (EDA)等,的特定加速芯片。4.3 AI-DSA推理芯片Inferentia
Inferentia是AWS第一款AI推理芯片,而基于Inferentia的Inf1实例针对ML推理进行了优化,与基于GPU的同类EC2实例相比,Inferentia的推理成本下降80%,吞吐量提高2.3倍。使用Inf1实例,客户可以在云端低成本运行大规模ML推理应用程序,例如图像识别、语音识别、自然语言处理、个性化和欺诈检测。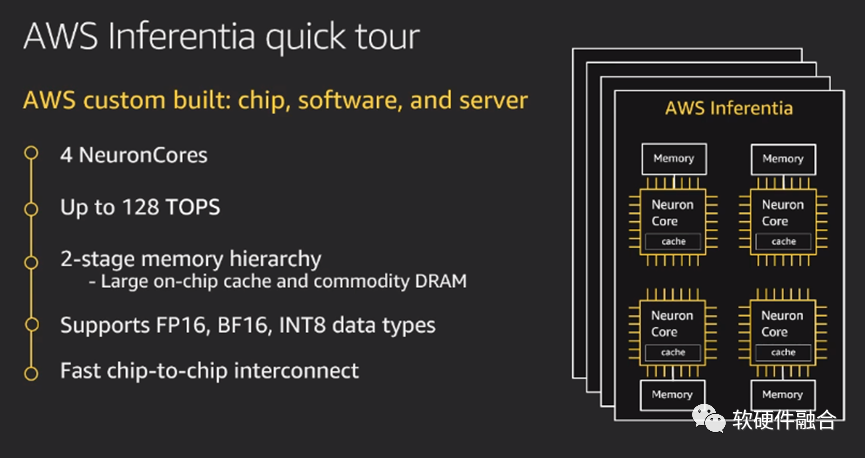 图9 AWS inferentia AI推理芯片Inferentia的高性能。每个芯片具有4个神经元核心,可以执行高达128 TOPS(每秒数万亿次操作)。它支持BF16、INT8和FP16数据类型。并且,Inferentia可以采用32位训练模型,并使用BF16的16位模型的速度运行它。亚马逊推理,低延迟的实时输出。随着ML变得越来越复杂,模型不断增长,将模型传入和传出内存成为最关键的任务,这带来了高延迟并放大了计算问题。Inferentia芯片具有在更大程度上解决延迟问题的能力。多芯片互联:首先可以将模型跨多个内核进行分区,并使用100%的片内内存——通过内核流水线全速传输数据,防止片外内存访问引起的延迟。支持所有框架。机器学习爱好者可以轻松地将几乎所有可用的框架上运行在Inferentia。要运行Inferentia,需要将模型编译为硬件优化表示。可以通过AWS Neuron SDK中提供的命令行工具或通过框架API执行操作。
图9 AWS inferentia AI推理芯片Inferentia的高性能。每个芯片具有4个神经元核心,可以执行高达128 TOPS(每秒数万亿次操作)。它支持BF16、INT8和FP16数据类型。并且,Inferentia可以采用32位训练模型,并使用BF16的16位模型的速度运行它。亚马逊推理,低延迟的实时输出。随着ML变得越来越复杂,模型不断增长,将模型传入和传出内存成为最关键的任务,这带来了高延迟并放大了计算问题。Inferentia芯片具有在更大程度上解决延迟问题的能力。多芯片互联:首先可以将模型跨多个内核进行分区,并使用100%的片内内存——通过内核流水线全速传输数据,防止片外内存访问引起的延迟。支持所有框架。机器学习爱好者可以轻松地将几乎所有可用的框架上运行在Inferentia。要运行Inferentia,需要将模型编译为硬件优化表示。可以通过AWS Neuron SDK中提供的命令行工具或通过框架API执行操作。4.4 AI-DSA训练芯片Trainium
 图10 AWS Trainium AI训练芯片如图10所示,在AWS re:Invent 2020开发者大会上,AWS发布了其设计的主要用于机器学习训练的第二款定制的AI芯片--AWS Trainium。它提供比云端任何竞争对手更高的性能,同时支持TensorFlow、PyTorch和MXNet等。这款定制芯片的主要优势是速度和成本,AWS承诺与标准AWS GPU实例相比,吞吐量提高30%,每次推断的成本降低45%。Trainium芯片还专门针对深度学习训练工作负载进行了优化,包括图像分类、语义搜索、翻译、语音识别、自然语言处理和推荐引擎等。它将以EC2(亚马逊弹性计算云)实例的形式出现在亚马逊的机器学习平台SageMaker中。Trainium与Inferentia有着相同的AWS Neuron SDK,这使得使用Inferentia的开发者可以很容易地开始使用Trainium。因为Neuron SDK集成了流行的机器学习框架,包括TensorFlow、PyTorch和MXNet,开发人员可以轻松地从基于GPU的实例迁移到Trainium,代码更改很少。
图10 AWS Trainium AI训练芯片如图10所示,在AWS re:Invent 2020开发者大会上,AWS发布了其设计的主要用于机器学习训练的第二款定制的AI芯片--AWS Trainium。它提供比云端任何竞争对手更高的性能,同时支持TensorFlow、PyTorch和MXNet等。这款定制芯片的主要优势是速度和成本,AWS承诺与标准AWS GPU实例相比,吞吐量提高30%,每次推断的成本降低45%。Trainium芯片还专门针对深度学习训练工作负载进行了优化,包括图像分类、语义搜索、翻译、语音识别、自然语言处理和推荐引擎等。它将以EC2(亚马逊弹性计算云)实例的形式出现在亚马逊的机器学习平台SageMaker中。Trainium与Inferentia有着相同的AWS Neuron SDK,这使得使用Inferentia的开发者可以很容易地开始使用Trainium。因为Neuron SDK集成了流行的机器学习框架,包括TensorFlow、PyTorch和MXNet,开发人员可以轻松地从基于GPU的实例迁移到Trainium,代码更改很少。5 Nitro SSD
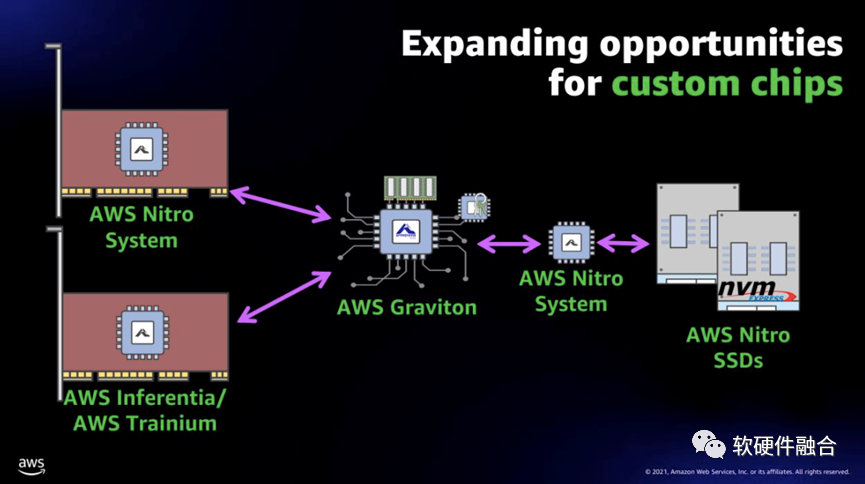 图11 Nitro SSD的位置Nitro SSD是一张独立的SSD盘,使用了专用的SSD控制器芯片,我们姑且称之为Nitro SSD Controller。为什么叫“Nitro” SSD?我理解是因为这个SSD是挂在Nitro卡之下,并且为了整个系统极致的优化,内部的一些协议或算法跟Nitro卡内部有一定的协同,不管是用于本地存储或者是EBS远程存储。AWS Nitro SSD,使AWS能够为客户提供具有大量IOPS、大量吞吐量和 64 TiB 的最大卷大小的EBS卷。Im4gn和Is4gen实例使用第二代AWS Nitro SSD,未来许多新的EC2实例也将使用Nitro SSD。AWS Nitro SSD每个设备内部的固件负责实现许多较低级别的功能。当客户将设备推向极限运行时,客户希望我们能够诊断并解决他们观察到的任何性能不一致问题。构建AWS自己的设备使AWS能够设计操作遥测和诊断,以及使AWS能够以云规模和云速度安装固件更新的机制。更进一步的,AWS开发了自己的代码来管理实例级存储,以进一步提高可靠性和调试能力。在性能方面,对云工作负载的深入了解促使AWS对设备进行设计,以便它们能够在持续的负载下提供最高性能。SSD由快速、密集的闪存构成。由于这种半导体存储器的特性,每个单元只能被写入、擦除和重写有限的次数。为了使设备的使用寿命尽可能长,固件负责一个称为磨损均衡的过程。这个过程涉及一些内务管理(一种垃圾收集形式),在处理大量写入时,各种类型的SSD可能会在不可预测的时间变慢(产生延迟峰值)。AWS还利用数据库的专业知识,在SSD固件中构建了一个非常复杂、断电安全的基于日志的数据库。第二代AWS Nitro SSD旨在避免延迟峰值并在实际工作负载上提供出色的I/O性能。基准测试显示,使用AWS Nitro SSD的实例(例如新的 Im4gn 和 Is4gen)的延迟可变性比I3实例低75%,从而为客户提供更加一致的SSD性能。
图11 Nitro SSD的位置Nitro SSD是一张独立的SSD盘,使用了专用的SSD控制器芯片,我们姑且称之为Nitro SSD Controller。为什么叫“Nitro” SSD?我理解是因为这个SSD是挂在Nitro卡之下,并且为了整个系统极致的优化,内部的一些协议或算法跟Nitro卡内部有一定的协同,不管是用于本地存储或者是EBS远程存储。AWS Nitro SSD,使AWS能够为客户提供具有大量IOPS、大量吞吐量和 64 TiB 的最大卷大小的EBS卷。Im4gn和Is4gen实例使用第二代AWS Nitro SSD,未来许多新的EC2实例也将使用Nitro SSD。AWS Nitro SSD每个设备内部的固件负责实现许多较低级别的功能。当客户将设备推向极限运行时,客户希望我们能够诊断并解决他们观察到的任何性能不一致问题。构建AWS自己的设备使AWS能够设计操作遥测和诊断,以及使AWS能够以云规模和云速度安装固件更新的机制。更进一步的,AWS开发了自己的代码来管理实例级存储,以进一步提高可靠性和调试能力。在性能方面,对云工作负载的深入了解促使AWS对设备进行设计,以便它们能够在持续的负载下提供最高性能。SSD由快速、密集的闪存构成。由于这种半导体存储器的特性,每个单元只能被写入、擦除和重写有限的次数。为了使设备的使用寿命尽可能长,固件负责一个称为磨损均衡的过程。这个过程涉及一些内务管理(一种垃圾收集形式),在处理大量写入时,各种类型的SSD可能会在不可预测的时间变慢(产生延迟峰值)。AWS还利用数据库的专业知识,在SSD固件中构建了一个非常复杂、断电安全的基于日志的数据库。第二代AWS Nitro SSD旨在避免延迟峰值并在实际工作负载上提供出色的I/O性能。基准测试显示,使用AWS Nitro SSD的实例(例如新的 Im4gn 和 Is4gen)的延迟可变性比I3实例低75%,从而为客户提供更加一致的SSD性能。6 综合分析
从定制硬件整机开始,再逐步深入到定制芯片,然后慢慢地把上层的软件、芯片以及硬件整机全方位协同并整合到一起,亚马逊AWS逐渐构筑起自己特有的、最强大的竞争优势。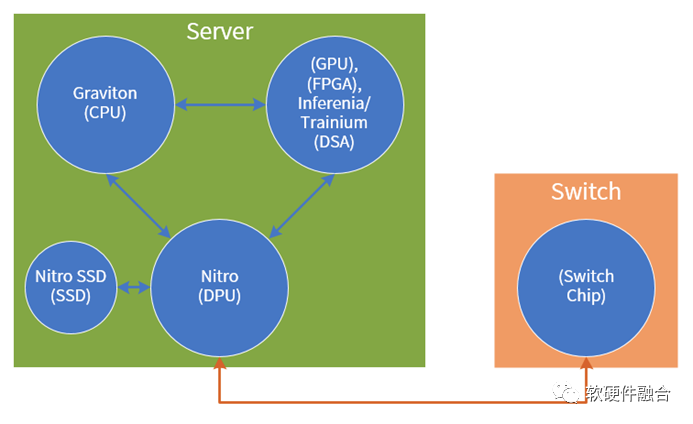 图12 以AWS为例的数据中心核心芯片示意图聚焦到芯片,简单总结一下。如图12所示,整个数据中心核心的芯片有如下类型:CPU、GPU/FPGA/各种DSA加速芯片、DPU、SSD等高性能存储控制芯片以及交换机芯片。未来AWS应该要做的是:数据中心关键芯片还没有的会逐渐补齐,已有的芯片类型后续会持续增强。详细的综合分析如表1所示。表1 AWS芯片自研综合分析
图12 以AWS为例的数据中心核心芯片示意图聚焦到芯片,简单总结一下。如图12所示,整个数据中心核心的芯片有如下类型:CPU、GPU/FPGA/各种DSA加速芯片、DPU、SSD等高性能存储控制芯片以及交换机芯片。未来AWS应该要做的是:数据中心关键芯片还没有的会逐渐补齐,已有的芯片类型后续会持续增强。详细的综合分析如表1所示。表1 AWS芯片自研综合分析| 位置 | 类型 | 子类型 | 代号 | 分析&推测 |
| 服务器侧 | CPU | CPU | Graviton | 重要性:★★★★★CPU是数据中心算力的最核心器件,ARM服务器CPU反响不错,AWS应该会持续重金投入,加大ARM服务器CPU的使用量,提升ARM服务器的整体占比。 |
| 应用加速 | GPU | 无 | 重要性:★★★★★在AI的算法模型还没有稳定之前,GPU都是AI算力的重要承担者,NVIDIA如日中天。AWS因为其上层软件生态的优势,以及云计算的运营模式,有能力抵消其在GPU生态上的劣势。预计未来AWS会自研GPGPU芯片,并加入EC2家族对外提供服务。 | |
| FPGA | 无 | 重要性:★★☆☆☆FPGA作为FaaS平台,对云计算上层服务来说,没有那么直接,需要客户或第三方ISV开发加速硬件和配套的软件。FaaS不是主流的云服务,并且Xilinx和Intel的FPGA都相对成熟稳定,FPGA应该不是AWS发展的重心。 | ||
| DSA-AI-推理 | Inferentia | 重要性:★★★★☆AI推理和训练我们放到一起。AI是应用的王者,并且是算力的吞金兽,必须要做各种定制加速DSA。并且,云计算的模式也可以先天抵消DSA-AI的许多使用门槛。通过云的封装,可以提供各种框架服务甚至SaaS层AI服务,使得AI-DSA芯片能大范围地用起来。对AWS来说,AI相关的定制芯片,是必须要持续投入,持续优化和增强的。 | ||
| DSA-AI-训练 | Trainium | |||
| DSA-其他 | 无 | 重要性:★★★☆☆除了AI,也有很多其他算力需求高的工作任务。随着发展,也会出现新的需要高算力的工作任务,比如元宇宙,就对图形图形处理、网络等提出了更高的要求。GPGPU的效率有所欠缺,并且可见的未来也会像CPU一样达到性能瓶颈。专用的图形GPU或者VPU可能会成为AWS下一个定制的DSA芯片。 | ||
| DPU | DPU | Nitro | 重要性:★★★★★(★)因为软件生态的强大,CPU是数据中心最核心的芯片。但CPU芯片的功能定义已经足够成熟,只需要持续优化升级改进即可。而DPU的挑战在于,DPU是整个云计算服务承载的核心,不仅仅是要提供足够的性能,更是要把现有的许多服务,不仅仅是IaaS层服务,也包括PaaS甚至SaaS的服务,要融入DPU中。可以说,DPU是云计算最战略级的芯片,没有之一。给六颗星,不为过。 | |
| CPU、GPU、DPU的整合 | 无 | 重要性:★★★★★NVIDIA有CPU+GPU的处理器,也有CPU+GPU+DPU的Atlan,未来CPU、GPU、DPU两两整合,或者三者整合成独立的单芯片加速平台是一个越来越明显的趋势。集成大芯片,会在性能和成本方面带来很多的好处。随着数据中心规模的增大,以及一些场景逐渐稳定成熟,把CPU、GPU、GPU重新整合重构,是一个必然的趋势。 | ||
| 存储盘 | SSD | Nitro SSD | 重要性:★★★☆☆存储控制器厂家,很容易“只见树木,不见森林”,导致无法站在数据中心超大规模的全局去思考问题,这也会导致存储卡会成为性能稳定性和数据安全的潜在风险。类似ZNS技术,AWS通过自研Nitro SSD跟Nitro DPU芯片更好地协同,给客户提供更稳定更安全的存储服务。只是,与整个数据中心计算相比,这块相对来说属于“枝叶”,一旦稳定,后期应该不需要投入太多。 | |
| 交换机侧 | Switch | Switch | 无 | 重要性:★★★★★更简单的网络,还是更复杂的网络?网络到底要不要分担计算的压力,足够Smart来处理一些计算的任务?还是提供极致简单且极致性能的网络,把可能的计算都交给用户,让用户掌控一切?上面说的这些话,如何选择都没关系。重要的是,交换机是网络的核心,网络又是云计算的前提。没有网络,计算和存储什么都不是。这一条就够了!交换机侧,AWS这种体量的云计算公司一定不会放过。期待AWS在交换机侧的创新! |
-
AWSInnovationScale,JamesHamilton,Re:Invent2016,https://mvdirona.com/jrh/talksandpapers/ReInvent2016_James%20Hamilton.pdf
-
AWSEC2Virtualization2017:IntroducingNitro,https://www.brendangregg.com/blog/2017-11-29/aws-ec2-virtualization-2017.html
-
AWSNitroSystem,JamesHamilton,https://perspectives.mvdirona.com/2019/02/aws-nitro-system/
-
AWS Graviton3:遵循摩尔定律又有自己节奏,Winnie shao,“企业存储技术”公众号,https://mp.weixin.qq.com/s/IFIIJ5sF4yvyGkrcsTPnLw
-
AWSInferentiaMachineLearningProcessor,JamesHamilton,https://perspectives.mvdirona.com/2018/11/aws-inferentia-machine-learning-processor/
-
DeepdiveintoAmazonInferentia:Acustom-builtchiptoenhanceMLandAI,https://www.cloudmanagementinsider.com/amazon-inferentia-for-machine-learning-and-artificial-intelligence/
-
MacOS上云了!AWS还推出机器学习Trainium芯片:万亿次浮点运算,推理成本再降45%,新智元,https://mp.weixin.qq.com/s/4xkLq4S1ZaZLuqQSNHI0_Q
-
AWSNitroSSD–HighPerformanceStorageforyourI/O-IntensiveApplications,https://aws.amazon.com/cn/blogs/aws/aws-nitro-ssd-high-performance-storage-for-your-i-o-intensive-applications/
审核编辑 :李倩
-
芯片
+关注
关注
462文章
53559浏览量
459326 -
硬件
+关注
关注
11文章
3556浏览量
68750 -
AWS
+关注
关注
0文章
443浏览量
26315
原文标题:亚马逊AWS自研芯片深度分析
文章出处:【微信号:Rocker-IC,微信公众号:路科验证】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
成功点亮并上车!对标Orin X,Momenta自研芯片来了

Arm自研芯片!从高通、英伟达手中抢客户?
传现代汽车解散半导体战略部门!车企自研芯片还可行吗?
AI业界新闻:OpenAI官宣自研首颗芯片 黄仁勋时隔9年再次给马斯克“送货”
江波龙自研UFS4.1主控芯片,顺序读取速率高达4350MB/s,性能对标主流产品

理想自研芯片预计明年量产上车
Arm CEO:公司正在自研芯片
高端芯片自研,服务器芯片传来好消息!
今日看点丨小鹏自研芯片或5月上车;安森美将在重组期间裁员2400人
Arm转型推自研芯片,Meta成首位客户
传DeepSeek自研芯片,厂商们要把AI成本打下来
OpenAI自研AI芯片即将进入试生产阶段
成功量产!德明利实现SATA SSD存储控制芯片关键IP和技术平台全自研






 工商网监
工商网监
评论