 思科推出新的AI网络芯片,正面硬刚博通、Marvell
思科推出新的AI网络芯片,正面硬刚博通、Marvell

6 月 20日,思科宣布推出专为人工智能超级计算机设计的新型网络芯片,在推出 Cisco Silicon One 三年半之后,思科宣布推出第四代设备,即 Cisco Silicon One G200 和 Cisco Silicon One G202,将与博通和 Marvell Technology 的产品展开直接竞争。
目前几家主要的云供应商已经在测试这些芯片,不过思科没有透露相关公司的名称。根据 Bofa Global Research的数据,主要的云计算参与者包括AWS、微软 Azure 和谷歌云等。
随着ChatGPT等 AI 应用的日益普及,单颗芯片的通信速度变得极其重要。
一次推出两大芯片
最新一代思科以太网交换机 G200 和 G202 的性能是其前代产品的两倍。这些芯片可以将多达 32,000 个图形处理单元 (GPU) 连接在一起,使其非常适合 AI 和机器学习工作负载。
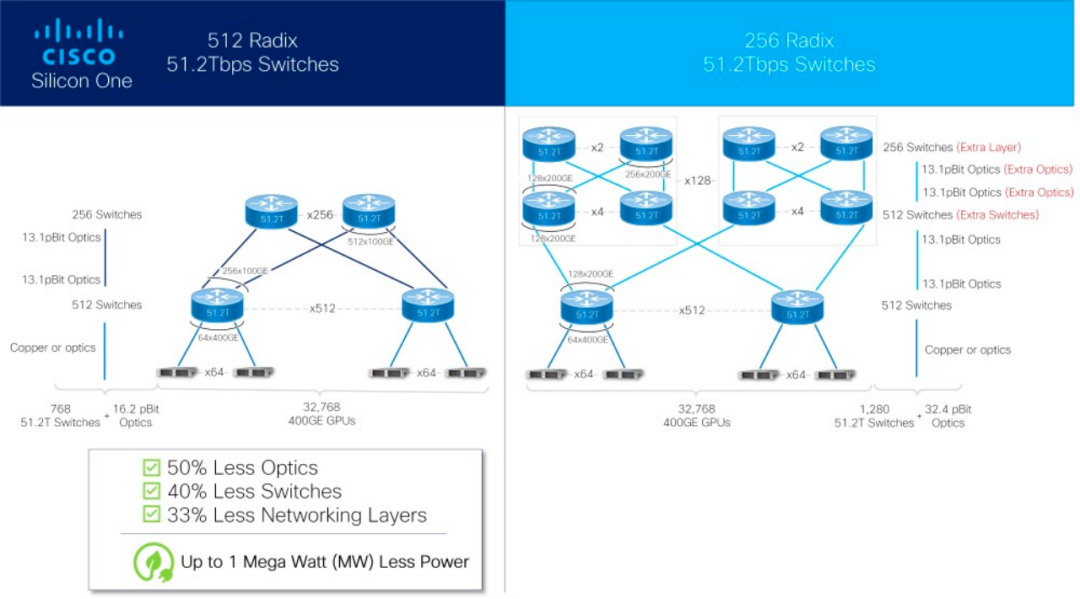
|51.2 Tbps 交换机的优势
思科研究员 Rakesh Chopra 强调,G200 和 G202 芯片将成为市场上最强大的网络芯片,为 AI/ML 任务提供更高的效率。
Cisco Silicon One G200
Cisco Silicon One G200 是一款 5 纳米、51.2 Tbps、512 x 112 Gbps 的SerDes设备,具有可编程、确定性、低延迟等特性,且具备高级可见性和控制能力。Cisco Silicon One G200 提供了统一架构的优势,专注于基于以太网的增强型AI/ML和网络规模主干部署。
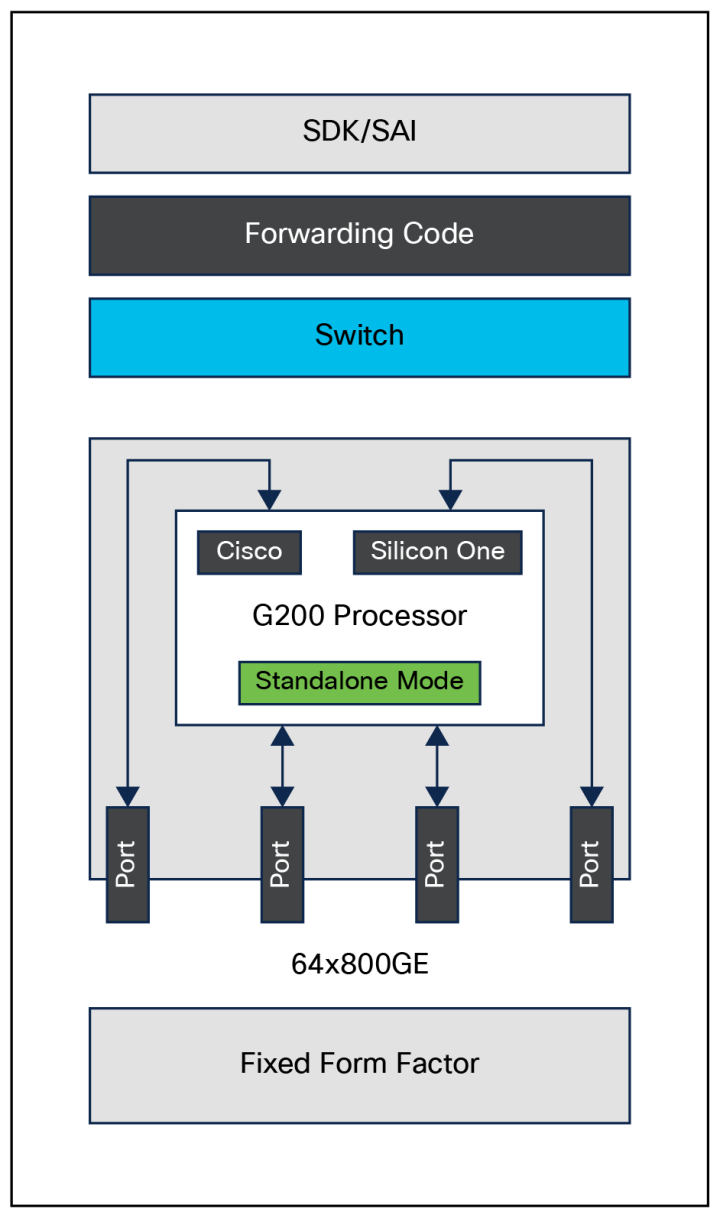
|Cisco Silicon One G200的构成
Cisco Silicon One G200 特性如下:
G200 展示了业界首款完全定制的 P4 可编程并行数据包处理器,每秒能够启动超过 4350 亿次查找。它以全速提供 SRv6 Micro-SID (uSID) 等高级功能,并支持复杂流程的完整运行到完成处理。这种独特的数据包处理架构确保了灵活性以及确定性的低延迟和功耗。
与替代解决方案相比,G200 凭借更高的基数脱颖而出,拥有 512 个以太网 MAC。通过消除不必要的层,显著降低客户网络部署的成本、功耗和延迟。
G200 能够驱动 43 dB 碰撞通道,支持共封装光学器件 (CPO)、线性可插拔对象 (LPO) 以及 4 米 26 AWG 铜缆的使用,超过了最佳机架内连接的 IEEE 标准。
此外,G200具有先进的拥塞感知负载均衡技术,使网络能够避免传统的拥塞事件。还有先进的packet-spraying 技术,最大限度地减少了网络拥塞热点的产生。
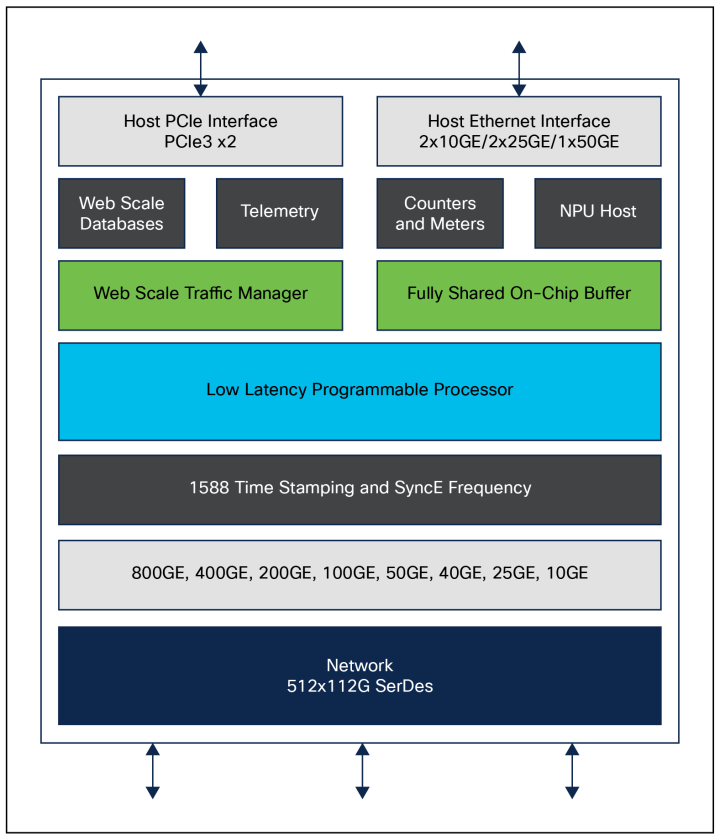
|Cisco Silicon One G200框图
Cisco Silicon One G202
Cisco Silicon One G202 处理器是一款 25.6-Tbps、全双工、独立的交换处理器,可用于构建固定外形规格的交换机,适合利用 50G SerDes 与交换机进行光纤连接的客户,非常适合网络级数据中心脊叶应用和 AI/ML 应用。
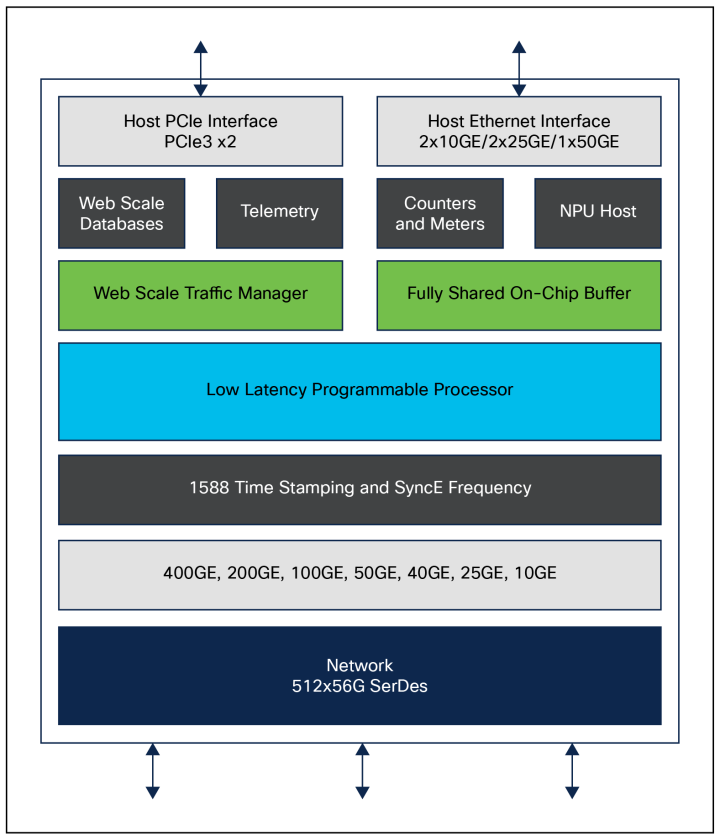
|Cisco Silicon One G202框图
Cisco Silicon One G200 和 G202 可优化 AI/ML 工作负载的实际性能,同时通过重大创新降低网络成本、功耗和延迟。
为了实现 Cisco Silicon One 的愿景,思科七年前开始投资关键技术——高速 SerDes 开发。思科意识到随着速度的提高,行业必须转向基于ADC(模数转换器)的 SerDes。
SerDes 作为高性能计算和 AI 部署的基本网络互连组件,发挥着至关重要的作用。如今,思科的下一代超高性能和低功耗 112 Gbps ADC SerDes 能够支持 4 米直连电缆 (DAC)、传统光学器件、LDO)和CPO,同时最大限度地减少硅晶片面积和功率。
思科押宝网络芯片,扩充网络版图
过去多年里,Facebook 和微软等巨头一直在设计自己的网络硬件,并将生产外包给海外制造商。思科之所以会滋生这个想法,是因为大型科技公司希望可以创建满足其特定需求的定制网络设备,而不是购买思科的传统路由器和交换机。
思科CEO Chuck Robbins在2019年接受媒体外媒的时候曾表示:“向服务提供商(包括电信公司)销售产品,几年来一直是一个艰难的市场。”公司的业绩和股市也在这段时间遭受冲击。这就驱使网络巨头去寻找新的路数。因此,思科希望通过销售专用网络芯片,吸引那些自己制造硬件但仍需要专用芯片的科技巨头。
思科从1999年收购半导体公司StratumOne Communications,之后通过多次收购半导体相关公司,积累了丰富的人才和技术资源。2019年,思科掀开了公司自研芯片的轰轰烈烈新序幕,并于当年12月首次推出了Silicon One芯片架构,当时称其目标是为“未来网络奠定通用基础”。
对外销售公司思科推出的Silicon One芯片就成为了思科的新“救命稻草”。思科也希望通过这种方式带来改变,吸引客户购买思科的新芯片或由他们提供动力的公司新路由器和交换机。思科CEO Chuck Robbin更是自豪地说:“从今天开始,我们将做一些你们中的一些人从未想过我们会做的事情——向我们的一些客户出售我们的芯片并帮助他们构建其产品。”思科在当时也透露,他们正在向包括 Facebook、微软和AT&T在内的少数知名企业销售网络芯片。
近日,思科又带来了用于人工智能超级计算机的网络芯片。思科表示,这些芯片可以帮助执行人工智能和机器学习任务,减少 40% 的交换机和更少的延迟,同时提高能效。
思科正面硬刚,博通、Marvell如何应对?
尽管思科来势汹汹,但早在市场占据领先优势的博通和 Marvell可不是吃素的。
今年3月,Marvell推出了用于 800 Gb/秒交换机的 51.2 Tb/秒 Teralynx 10交换机ASIC。
早在2021年,Marvell就收购了云数据中心商业交换机芯片供应商Innovium。Innovium于 2019 年 9 月推出了 Teralynx 5 芯片,速度范围从 1 Tb/秒到 6.4 Tb/秒,随后推出的Teralynx 7 直接与博通的“Tomahawk 4”StrataXGS对标, 2020 年 5 月,Innovium推出了 Teralynx 8 交换芯片,针对超大规模器和云构建器的叶、脊和数据中心互连 (DCI) 用例,使用 100 Gb/秒 PAM-4 编码跨 8 Tb/秒到 25.6 Tb/秒在给定带宽下创建以太网端口。
据Marvell介绍,Teralynx 10 是更大、更胖(fat)的交换机 ASIC,它也基于采用 PAM-4 编码的 100 Gb/秒 SerDes,是一款专为 800GbE 时代设计的 51.2T 可编程 5nm交换机芯片,旨在解决运营商带宽爆炸的问题,同时满足严格的功耗和成本要求。它可适用于下一代数据中心网络中的 leaf 和 spine 应用,以及 AI / ML 和高性能计算 (HPC) 结构。
据介绍,一个 Teralynx 10 相当于 12 个 12.8 Tbps 一代芯片,由此可以在同等容量下减少 80% 的功耗。Teralynx 10 具有 512 个长距离 (LR) 112G SerDes,有了它,交换机系统可以开发出更全面的交换机配置,例如 32 x 1.6T、 64 x 800G 和 128 x 400G 链路。
4 月,博通也发布了新的 Jericho3-AI 芯片,可以将多达 32,000 个 GPU 芯片连接在一起。
在交换机芯片部分,博通有三个系列的交换芯片,Tomahawk系统芯片是高带宽交换机平台芯片;Trident系列芯片是多功能的平台芯片;Jericho系列芯片则主打较低带宽,但有多缓冲和可编程性平台芯片;博通Jericho3-AI是Jericho系列中的最新成员。
Jericho3-AI结构的主要特点是负载平衡,以保持链路不拥挤,结构调度,零影响故障切换,以及具有高以太网径向。
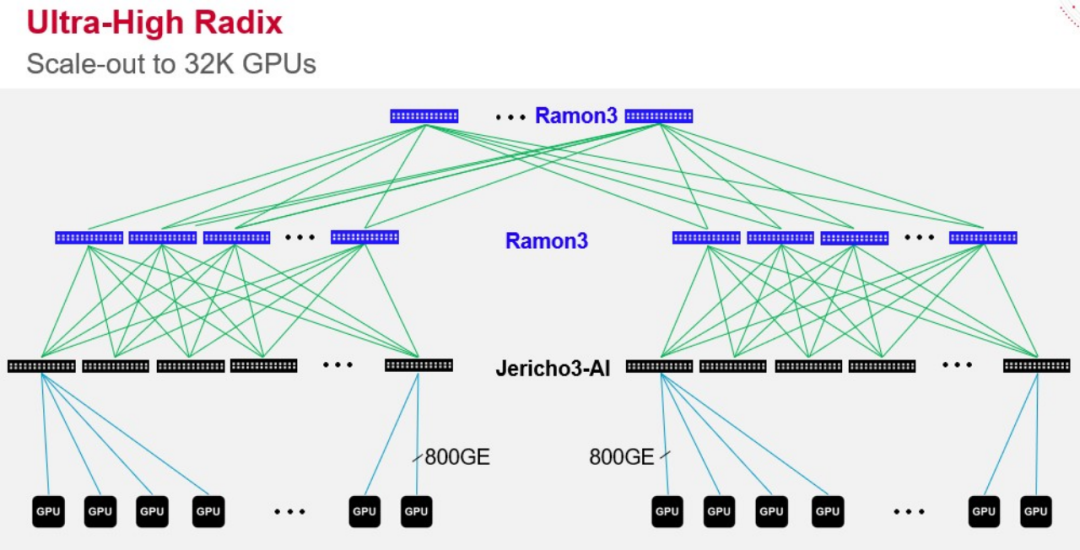
据介绍,Jericho3-AI 的最高吞吐量为 28.8Tb/s。它有 144 个以 106Gbps PAM4 运行的 SerDes 通道,支持多达 18 个 800GbE/36 个 400GbE/72 个 200GbE 网络端口。Jericho3-AI 还具有比上一代改进的负载平衡功能,以确保最大的网络利用率和无拥塞操作。
网络芯片在人工智能应用中的意义
ChatGPT 等人工智能应用严重依赖 GPU 等专用芯片。这些芯片之间的高效通信对于确保最佳性能至关重要。思科网络芯片的推出旨在满足这一需求并为 AI 超级计算机提供增强的连接性。
650 Group在最近的一篇博客中指出,思科在不断增长的人工智能网络市场占据了一席之地,该市场的其他玩家还包括博通、Marvell和Arista 等。预计到 2027 年人工智能网络市场的规模将达到 100亿美元。
过去两年,人工智能网络蓬勃发展。未来AI/ML 将成为网络领域的巨大机遇,并且将成为数据中心网络增长的主要驱动力之一。650 Group表示:“未来 10 年,许多垂直行业将因人工智能而经历多次变化。”
审核编辑:刘清
-
人工智能
+关注
关注
1820文章
50325浏览量
266967 -
机器学习
+关注
关注
67文章
8565浏览量
137226 -
AI芯片
+关注
关注
17文章
2164浏览量
36869
原文标题:思科推出新的AI网络芯片,正面硬刚博通、Marvell
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
新思科技首届Converge大会隆重举行
正面硬刚Meta!千问AI眼镜MWC首秀,与全球巨头对垒

AI芯片大单!Anthropic从博通采购100万颗TPU v7p芯片
思科Cisco 8223:51.2Tbps P200芯片助力AI数据中心

4000+ 单核里程碑!天玑9500正面硬刚 A19 Pro

【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片到AGI芯片
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片的需求和挑战
SiMa.ai与新思科技达成战略合作
OpenAI将与博通合作量产自研AI芯片 博通第四财季AI芯片收入展望超预期
环旭电子即将推出新一代1.6T光模组产品
新思科技携手是德科技推出AI驱动的射频设计迁移流程
新思科技携手微软借助AI技术加速芯片设计
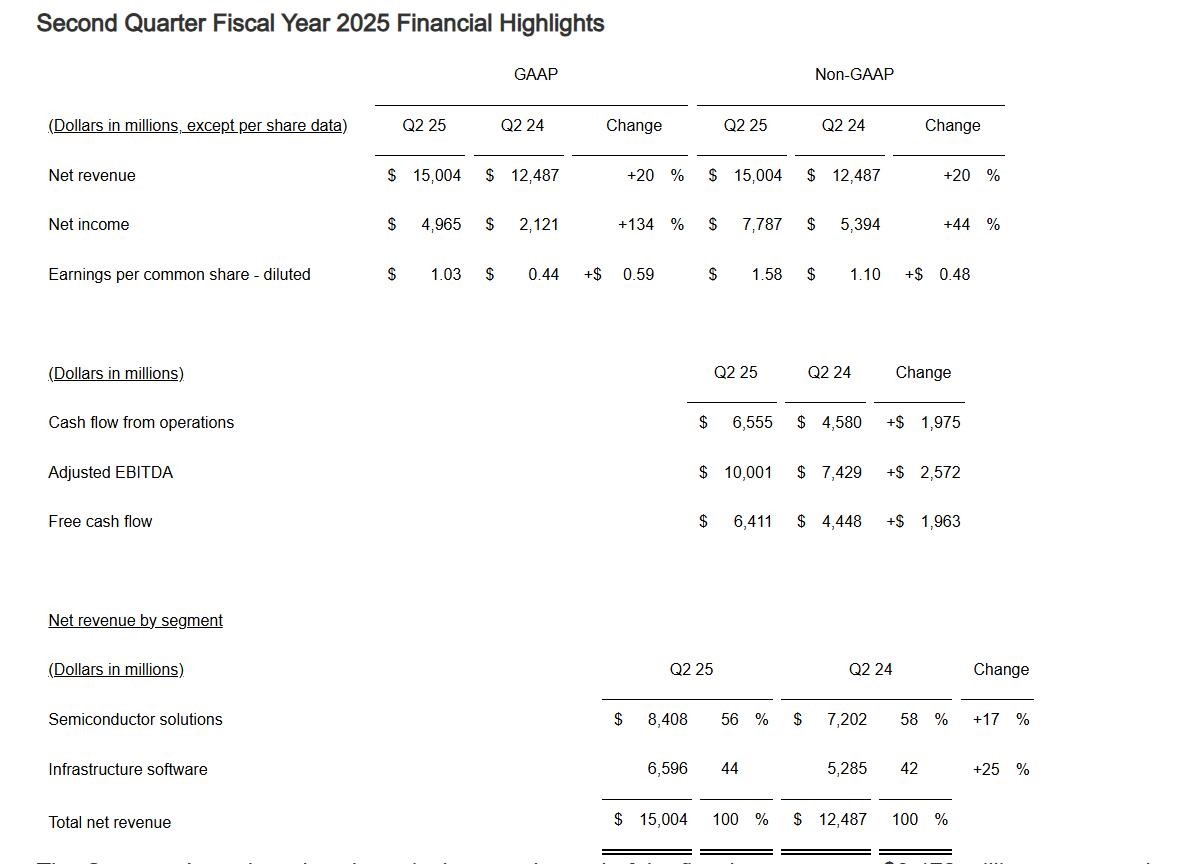
AI芯片大赚44亿美元!博通Q2营收创新高,净利润大增134%



评论