 在Alveo加速卡上管理子系统CMC介绍
在Alveo加速卡上管理子系统CMC介绍

Alveo 加速卡除了有我们 ultrascale+系列的芯片以外,还有 TI 的 MSP432,它的作用就是监控板子的状态,比如电流电压温度等信息。主控端可以通过 FPGA,访问 MPS432,然后获取这些信息。那么怎么样简单的获得这些信息呢,为此我们准备了 CMSIP。
系统构架
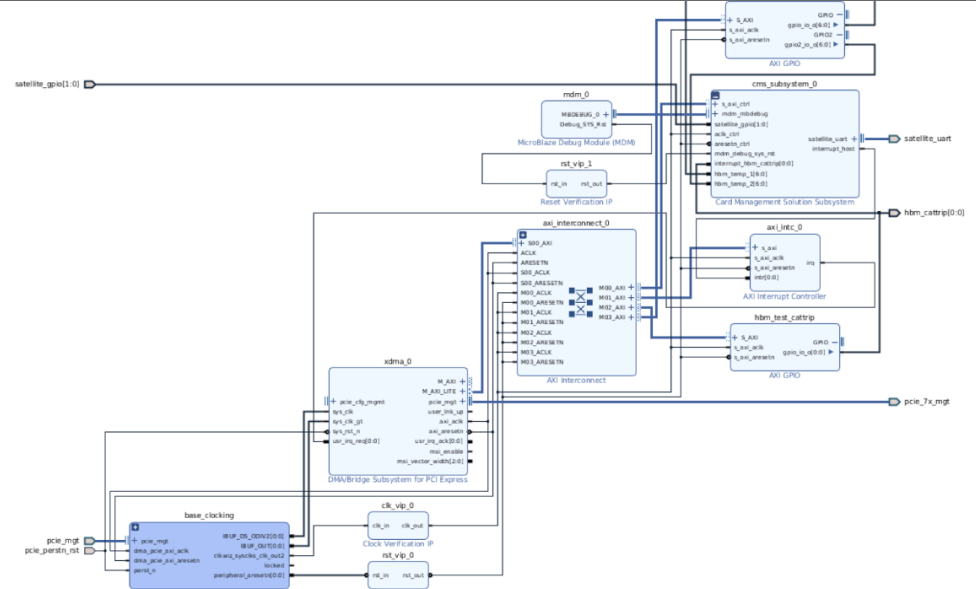
下面这个图就是整个主控与 FPGA 以及 MPS432 的模块图
有几个关键的点简单说一下,
首先图中的红色框可以看到 CMS 和 MSP432 的数据通过 UART 接口。
然后获取的板上的信息都是存储在 BRAM 中(绿色)
Microblaze 是 CMS 的主控模块,控制 UART 接口,以及将获取的数据存储到 BRAM 中。
最后 CMS 本身有 AXI4-Lite 接口可以连接到 XDMA,主控端就可以访问到 BRAM 中的数据了。
CMS example 设计
CMS 的 IP 本身不用配置,而且 example 设计可以直接跑。下面介绍下步骤。
1)。 首先打开 Vivado,选择 board,这里我用 U50 板卡。

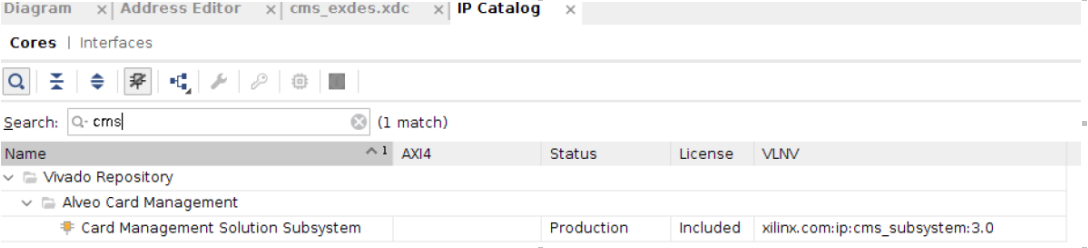
然后在 IP catalog 里找到 CMS IP,选择 IP,然后不用配置,直接生成。
2)。 在 source 窗口右键这个 IP,然后点击 “openexample design”
Vivado 会打开一个新的例子工程。一般例子工程会根据你选择的板卡,做好所有的管脚约束,所以只需要直接点击 generatebitstream。
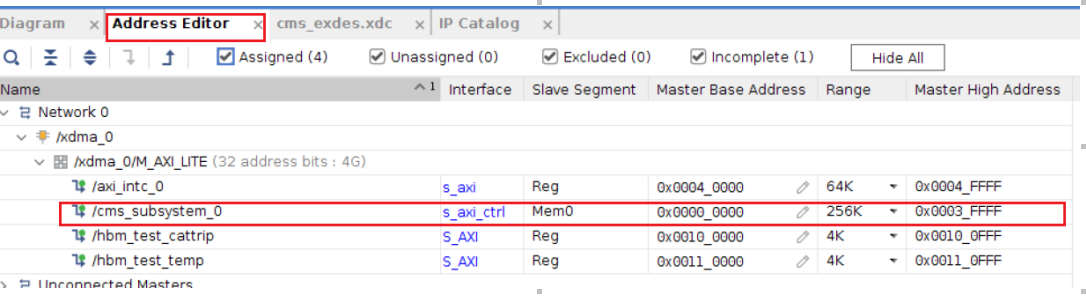
Vivado 会自动给 cms IP 分配一个地址。打开 addresseditor,我们可以看到这个工程里的offset 恰好是 0x00000000,记住这个地址。后面在主机端访问时会用到。
3)。 生成 bit 文件以后,将 U50 板子插在主机 PCIe 槽中,连上 “alveoprogramming cable”,上电,将 bit 文件烧录到 U50 板卡的 FPGA 以后,热启动主机,使其能够再次 scan并发现板卡。如果一切正常,在主机端使用 lspci 命令可以找到板卡。
Lspci-vd 10ee:
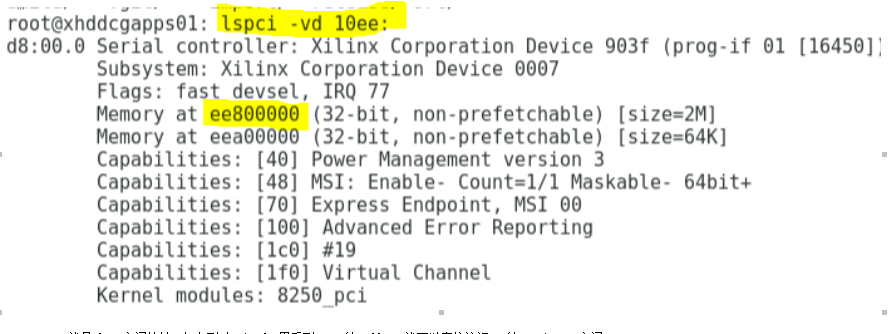
0xee800000 就是 bar 空间地址,加上刚才 vivado 里看到 cms 的 offset 就可以直接访问cms的 register 空间。
CMS 的 register 空间可以在 PG348 里找到。

所有的板卡的电压,电流,功耗以及温度等信息都放在REG_MAP空间里,offset 时0x0280000。
所以如果要访问 CMS 的 REG_MAP 里的某一个寄存器的话,
地址= PCIebar 地址 + CMSoffset 地址 + REG_MAPoffset address+ 特定寄存器地址
简单的方法你可以使用 devmem2 直接访问,这样不需要任何驱动。
不过 CMS 的 microblaze 控制器时 resetactive 状况,所以我们先要解复位。
devmeme2 0xee820000 b 0x1
然后举个例子我们要读取下 12V 的平均功耗。

devmem20xee8282DC w
你就可以在终端看到 12V 电压的平均功耗。
责任编辑:lq6
-
芯片
+关注
关注
463文章
54412浏览量
469177 -
电流
+关注
关注
40文章
7226浏览量
141584 -
电压
+关注
关注
45文章
5790浏览量
122379 -
加速卡
+关注
关注
1文章
75浏览量
11361
发布评论请先 登录
选择AMD Alveo V80加速卡的五大理由
AMD Alveo MA35D媒体加速卡的AMA SDK 1.4.0版本发布
FPGA硬件加速卡设计原理图:1-基于Xilinx XCKU115的半高PCIe x8 硬件加速卡 PCIe半高 XCKU115-3-FLVF1924-E芯片

新品 | LLM-8850 Kit,高性能AI加速卡套件 DinMeter v1.1,1/32DIN标准嵌入式开发板

高速信号处理设计方案:413-基于双XCVU9P+C6678的100G光纤加速卡
AMD Alveo MA35D加速器:开启大规模交互式流媒体新时代
迈向云端算力巅峰:昆仑芯K200 AI加速卡全面解读

深圳光量子工厂启示:PCI 加速卡为何偏向 25MHz 2016 有源晶振?

算力密度翻倍!江原D20加速卡发布,一卡双芯重构AI推理标杆

虚拟电厂加速卡不是噱头!万点规模VPP的性能分水岭
新品 | LLM-8850 Card, AX8850边缘设备AI加速卡

智算加速卡是什么东西?它真能在AI战场上干掉GPU和TPU!


边缘AI运算革新 DeepX DX-M1 AI加速卡结合Rockchip RK3588多路物体检测解决方案

寒武纪基于思元370芯片的MLU370-X8 智能加速卡产品手册详解




评论