 算力密度翻倍!江原D20加速卡发布,一卡双芯重构AI推理标杆
算力密度翻倍!江原D20加速卡发布,一卡双芯重构AI推理标杆

电子发烧友网报道(文/莫婷婷)随着AI技术迅猛发展,大模型的参数规模已突破千亿级别,AI推理需求呈现出爆发式增长。然而,在大模型加速落地的浪潮中,高效、稳定且安全的推理能力日益凸显为制约产业发展的关键技术瓶颈。
在此背景下,江原科技推出采用自研AI芯片的AI加速卡江原D10,并在今年5月实现量产交付。在大算力AI芯片全流程国产化产业链实现首次突破后,11月11日,江原科技再次发布新一代全国产AI加速卡——江原D20,成为中国AI芯片产业迈向自主可控的关键一步。

市场需求驱动下的国产替代加速:从D10到D20的跨越式发展
当前全球AI技术正从“训练为王”转向“推理主导”,预计在2024年推理业务占比为65%,到了2028年将达到73%。国际市场调研机构IDC预测,生成式AI成为IT增长的核心驱动力引擎,预计到2028年,GenAI服务器占比将高达37.7%。
但在技术上,全球半导体供应链面临严峻挑战:由于美国实施出口管制,英伟达等国际企业禁止向中国市场出售高端GPU产品,导致国内企业难以获取高性能算力。与此同时,国内AI应用落地需求持续升温,对本地化、安全可控的AI算力平台需求日益迫切。
正是在这样的背景下,江原科技选择进入国产AI推理芯片赛道,依托本土完整的产业链资源,实现了从芯片设计、制造到封装测试的全流程国产化,为客户提供高性价比、高可靠性的国产替代方案。
江原科技成立于2022年11月,在这三年时间里,江原科技完成了产业链协同、研发规划与制造工艺上的系统性布局,快速完成产品迭代。
2025年5月,江原D10加速卡正式量产交付,其核心搭载的是江原科技自研的AI芯片。7月,品高股份发布了搭载D10加速卡的“品原AI一体机”,加速D10的商业化落地。在此基础上,江原科技迅速迭代出D20加速卡。
江原科技CEO李瑛在接受采访时表示:“我们在产品发布前就完成了整体规划,所有研发进程都按照既定路线稳步推进,确保了从D10到D20的快速迭代。”
江原科技联合创始人、CTO王永栋指出,当前行业有两大技术趋势,一是国内私有化部署需求迅猛增长,对数据安全隐私的高度重视;二是随着百亿乃至千亿参数大模型成为主流,单卡已难以承载其部署需求,多卡分布式计算已成为常规方案。
与此同时,存储性能已超越算力,成为影响系统综合性能的关键因素,在这里面,云端和边缘端的关注点也有不同,云端更关注存储带宽以支撑高并发,边缘侧则更侧重存储容量。因此,提升单机的算力密度与存储密度,不仅能降低整机成本,还能支持更大规模模型部署,显著提升性价比。这也正是江原科技研发全新国产AI加速卡D20的核心动因,王永栋表示。
D20加速卡:一卡双芯、320 TOPS,重构算力密度新标杆
江原D20加速卡采用“一卡双芯”架构,在单张PCIE插槽内集成两颗江原全国产AI芯片,通过先进的PCIe Bifurcation技术,共享一个16-lane PCIe 5.0接口,实现双芯片直连通信,省去了传统多卡系统中昂贵的PCIe Switch芯片,大幅降低了成本与功耗。
一卡双芯的架构带来两大优势:一是算力密度翻倍:相比D10,D20的INT8算力提升至320 TOPS;二是存储密度升级:最大支持256GB LPDDR5显存,单台服务器最多可达4T,满足大模型推理对高容量显存的需求。
此外,在功耗控制方面,D20整卡功耗仅为145W,提供主动散热与被动散热两种模式,同时,其多媒体处理能力同样出色,支持256路高清视频解码、20路高清编码。

王永栋表示,“一卡双芯”类产品比较少主要是受限于软件生态,因为单卡与多卡在软件层面、执行方式都不相同,所以很难做到单卡和多卡同时运行。但在大模型时代,分布式计算框架已成为行业标配。
如今,江原科技已经构建了完备的软件生态体系。从底层驱动、中间件编程模型,到高性能计算库、通信库,再到主流框架的无缝接入,有效解决了软件生态瓶颈。从GPU迁移到D10只需修改一行代码,而从D10升级至D20则无需任何改动,做到全栈软件无缝支持,极大降低了迁移门槛。
从服务器到液冷AI PC,全场景产品矩阵
基于D20加速卡,江原科技升级了服务器产品,推出江原D20 4U16卡智算服务器,并推出全新产品桌面型AI PC,构建起覆盖云端、边缘侧和桌面端的完整算力生态。
江原D20 4U16卡智算服务器搭载16张D20加速卡,集成32颗全国产AI芯片,整机INT8算力达5POPS,LPDDR5显存高达4TB,支持PCIe 5.0 x16互联,具备强大的集群扩展能力。得益于D20的低功耗设计,为数据中心客户提供极具性价比的算力解决方案。
D20桌面型AI PC系列采用全液冷静音设计,推理运行噪音≤30dB,仅为风冷的八分之一;推理运行温度控制在50℃以下,比风冷方案降低了35%。

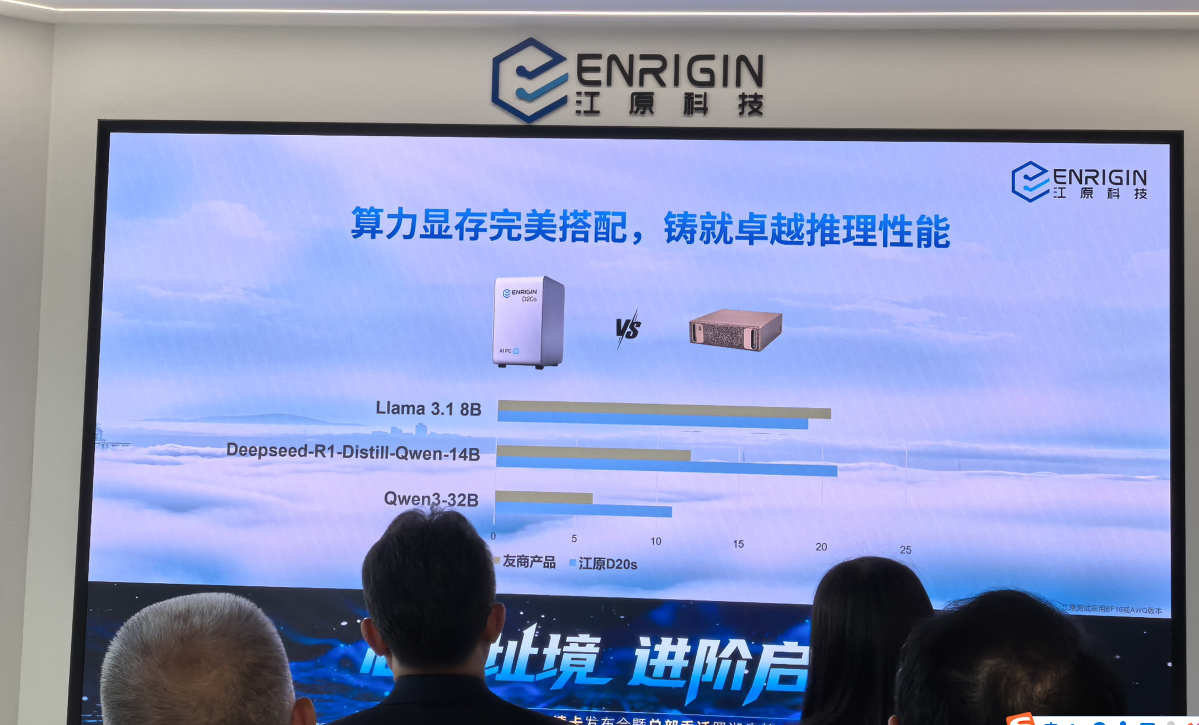
在算力方面,与海外高端GPU产品在桌面端部署场景下的推理表现进行性能对比的结果显示,在8B小模型上,双方性能基本持平;而在14B和32B大模型中,江原AIPC展现出显著优势,推理性能优于竞品。
通过高密度算力和大容量LPDDR5显存的协同设计,江原D20实现了在算力与显存之间的完美匹配,有效弥补了国产AI芯片与海外高端GPU产品工艺制程上的差距。
针对行业客户与个人用户,江原科技推出三款液冷静音AI PC:D20s基础版:搭载1块D20,配备Intel i5 CPU与128GB显存;D20d升级版:双D20配置,搭配AMD 7960X CPU;D20q信创版:采用海光CPU+四张D20,支持Qwen系列480B及DeepSeek-R1-Distill系列671B满血版部署。
李瑛表示,江原科技的产品不仅支持纯国产信创环境,也面向医疗等对生态兼容性有特定需求的行业客户,公司正在积极适配国内外主流操作系统和服务器平台,确保在多样化应用场景下的广泛兼容与灵活部署。
江原科技已开放测试平台,累计导入100+客户进行业务测试,涵盖云服务、医疗、能源、传媒、高校、公安等20多个行业。
在D20加速卡发布会上,江原科技宣布与中国电子技术标准化研究院、上海新相微电子、黑龙江振宁科技等战略伙伴签署合作协议。通过技术共研、生态共建、场景共创,江原科技正在加速推动国产AI从底层芯片到行业应用的深度融合与规模化落地。例如,在与新相微的合作方面,双方将联合研发核心硬件,重点提升在视觉计算领域的适配能力;另一方面,双方共同开发加速卡与传感模组的一体化解决方案,聚焦智能安防、工业视觉等细分场景落地。
按照产品规划,江原科技的旗舰级芯片T800将在明年量产。从D10到D20,再到即将面世的T800,江原科技在短短三年内,江原科技实现了从产品研发到商业落地的跨越式转变。在这个过程中,国产AI推理芯片企业不再是简单复制国外产品,而是结合中国市场需求特点,开发出真正有价值的差异化解决方案。
在此背景下,江原科技推出采用自研AI芯片的AI加速卡江原D10,并在今年5月实现量产交付。在大算力AI芯片全流程国产化产业链实现首次突破后,11月11日,江原科技再次发布新一代全国产AI加速卡——江原D20,成为中国AI芯片产业迈向自主可控的关键一步。
市场需求驱动下的国产替代加速:从D10到D20的跨越式发展
当前全球AI技术正从“训练为王”转向“推理主导”,预计在2024年推理业务占比为65%,到了2028年将达到73%。国际市场调研机构IDC预测,生成式AI成为IT增长的核心驱动力引擎,预计到2028年,GenAI服务器占比将高达37.7%。
但在技术上,全球半导体供应链面临严峻挑战:由于美国实施出口管制,英伟达等国际企业禁止向中国市场出售高端GPU产品,导致国内企业难以获取高性能算力。与此同时,国内AI应用落地需求持续升温,对本地化、安全可控的AI算力平台需求日益迫切。
正是在这样的背景下,江原科技选择进入国产AI推理芯片赛道,依托本土完整的产业链资源,实现了从芯片设计、制造到封装测试的全流程国产化,为客户提供高性价比、高可靠性的国产替代方案。
江原科技成立于2022年11月,在这三年时间里,江原科技完成了产业链协同、研发规划与制造工艺上的系统性布局,快速完成产品迭代。
2025年5月,江原D10加速卡正式量产交付,其核心搭载的是江原科技自研的AI芯片。7月,品高股份发布了搭载D10加速卡的“品原AI一体机”,加速D10的商业化落地。在此基础上,江原科技迅速迭代出D20加速卡。
江原科技CEO李瑛在接受采访时表示:“我们在产品发布前就完成了整体规划,所有研发进程都按照既定路线稳步推进,确保了从D10到D20的快速迭代。”
江原科技联合创始人、CTO王永栋指出,当前行业有两大技术趋势,一是国内私有化部署需求迅猛增长,对数据安全隐私的高度重视;二是随着百亿乃至千亿参数大模型成为主流,单卡已难以承载其部署需求,多卡分布式计算已成为常规方案。
与此同时,存储性能已超越算力,成为影响系统综合性能的关键因素,在这里面,云端和边缘端的关注点也有不同,云端更关注存储带宽以支撑高并发,边缘侧则更侧重存储容量。因此,提升单机的算力密度与存储密度,不仅能降低整机成本,还能支持更大规模模型部署,显著提升性价比。这也正是江原科技研发全新国产AI加速卡D20的核心动因,王永栋表示。
D20加速卡:一卡双芯、320 TOPS,重构算力密度新标杆
江原D20加速卡采用“一卡双芯”架构,在单张PCIE插槽内集成两颗江原全国产AI芯片,通过先进的PCIe Bifurcation技术,共享一个16-lane PCIe 5.0接口,实现双芯片直连通信,省去了传统多卡系统中昂贵的PCIe Switch芯片,大幅降低了成本与功耗。
一卡双芯的架构带来两大优势:一是算力密度翻倍:相比D10,D20的INT8算力提升至320 TOPS;二是存储密度升级:最大支持256GB LPDDR5显存,单台服务器最多可达4T,满足大模型推理对高容量显存的需求。
此外,在功耗控制方面,D20整卡功耗仅为145W,提供主动散热与被动散热两种模式,同时,其多媒体处理能力同样出色,支持256路高清视频解码、20路高清编码。
王永栋表示,“一卡双芯”类产品比较少主要是受限于软件生态,因为单卡与多卡在软件层面、执行方式都不相同,所以很难做到单卡和多卡同时运行。但在大模型时代,分布式计算框架已成为行业标配。
如今,江原科技已经构建了完备的软件生态体系。从底层驱动、中间件编程模型,到高性能计算库、通信库,再到主流框架的无缝接入,有效解决了软件生态瓶颈。从GPU迁移到D10只需修改一行代码,而从D10升级至D20则无需任何改动,做到全栈软件无缝支持,极大降低了迁移门槛。
从服务器到液冷AI PC,全场景产品矩阵
基于D20加速卡,江原科技升级了服务器产品,推出江原D20 4U16卡智算服务器,并推出全新产品桌面型AI PC,构建起覆盖云端、边缘侧和桌面端的完整算力生态。
江原D20 4U16卡智算服务器搭载16张D20加速卡,集成32颗全国产AI芯片,整机INT8算力达5POPS,LPDDR5显存高达4TB,支持PCIe 5.0 x16互联,具备强大的集群扩展能力。得益于D20的低功耗设计,为数据中心客户提供极具性价比的算力解决方案。
D20桌面型AI PC系列采用全液冷静音设计,推理运行噪音≤30dB,仅为风冷的八分之一;推理运行温度控制在50℃以下,比风冷方案降低了35%。
在算力方面,与海外高端GPU产品在桌面端部署场景下的推理表现进行性能对比的结果显示,在8B小模型上,双方性能基本持平;而在14B和32B大模型中,江原AIPC展现出显著优势,推理性能优于竞品。
通过高密度算力和大容量LPDDR5显存的协同设计,江原D20实现了在算力与显存之间的完美匹配,有效弥补了国产AI芯片与海外高端GPU产品工艺制程上的差距。
针对行业客户与个人用户,江原科技推出三款液冷静音AI PC:D20s基础版:搭载1块D20,配备Intel i5 CPU与128GB显存;D20d升级版:双D20配置,搭配AMD 7960X CPU;D20q信创版:采用海光CPU+四张D20,支持Qwen系列480B及DeepSeek-R1-Distill系列671B满血版部署。
李瑛表示,江原科技的产品不仅支持纯国产信创环境,也面向医疗等对生态兼容性有特定需求的行业客户,公司正在积极适配国内外主流操作系统和服务器平台,确保在多样化应用场景下的广泛兼容与灵活部署。
江原科技已开放测试平台,累计导入100+客户进行业务测试,涵盖云服务、医疗、能源、传媒、高校、公安等20多个行业。
在D20加速卡发布会上,江原科技宣布与中国电子技术标准化研究院、上海新相微电子、黑龙江振宁科技等战略伙伴签署合作协议。通过技术共研、生态共建、场景共创,江原科技正在加速推动国产AI从底层芯片到行业应用的深度融合与规模化落地。例如,在与新相微的合作方面,双方将联合研发核心硬件,重点提升在视觉计算领域的适配能力;另一方面,双方共同开发加速卡与传感模组的一体化解决方案,聚焦智能安防、工业视觉等细分场景落地。
按照产品规划,江原科技的旗舰级芯片T800将在明年量产。从D10到D20,再到即将面世的T800,江原科技在短短三年内,江原科技实现了从产品研发到商业落地的跨越式转变。在这个过程中,国产AI推理芯片企业不再是简单复制国外产品,而是结合中国市场需求特点,开发出真正有价值的差异化解决方案。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
AI芯片
+关注
关注
17文章
2185浏览量
36889
发布评论请先 登录
相关推荐
热点推荐
新华三发布S8000超节点系列,单机柜最高128卡可扩展至16384卡
近日,紫光股份旗下新华三集团正式发布S8000超节点系列智算解决方案。该方案单机柜最高可部署128张AI加速卡,通过柜间互联最大可扩展至16384卡
DEEPX算力卡,功耗不到3W!搭载RK3588实测,25TOPS加持,助力AI视觉升级!
在智能机器人、工业视觉等边缘计算场景中,如何在高算力与低功耗之间找到最佳平衡点,一直是行业痛点。创龙科技基于瑞芯微RK3588高性能工业评估板,已成功适配DEEPX DX-M1

国内首个国产AI推理千卡集群落地,采用云天励飞全自研AI推理芯片
3 月 12 日,云天励飞中标湛江市AI渗透支撑新质生产力基础设施建设项目,中标金额4.2亿元。项目将基于云天励飞自研的国产AI推理加速卡,
发表于 03-12 11:10
•1375次阅读
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
310P芯片的底层架构,深度剖析这款产品的技术细节、算力门槛及其在实际产业落地中的真实价值。
一、176TOPS的产业门槛:为何这是边缘算力
发表于 03-10 14:19
Hailo-8算力卡 + RK3588实测!26TOPS加持,助力AI视觉升级!
推理、低功耗运行”的硬核实力,为边缘AI视觉部署提供了可靠高效的算力支持。 我们收到Hailo-8 AI

新品 | LLM-8850 Kit,高性能AI加速卡套件 DinMeter v1.1,1/32DIN标准嵌入式开发板
LLM-8850KitLLM-8850Kit是一款面向边缘AI与嵌入式计算场景的高性能AI加速卡套件,由LLM-8850CardAI加速卡与

墨芯人工智能千卡集群正式签约入驻新疆算力中心
,通过构建“西部训练、东部推理”的协同范式,推动算力资源在全国范围内的优化配置。 当下,我国算力格局正向西部进行战略性迁移。墨
昆仑芯R200 AI加速卡技术规格解析
昆仑芯R200加速卡基于7nm XPU-R架构,在150W功耗下提供256 TOPS INT8算力,侧重高性能推理。配备最高32GB GDD

迈向云端算力巅峰:昆仑芯K200 AI加速卡全面解读
昆仑芯K200作为云端AI加速卡,在K100架构基础上全面升级。其INT8算力达256 TOPS,配备16GB HBM内存与512GB/s带

专为边缘而生:深度解析昆仑芯K100 AI加速卡,释放128 TOPS极致能效
昆仑芯K100边缘AI加速卡以75W超低功耗实现128 TOPS的INT8算力,重新定义边缘推理

芯无址境 进阶启新——江原科技D20加速卡发布暨总部乔迁庆典圆满落幕
11月11日,江原科技以“芯无址境,进阶启新”为主题,在城建云启大厦同步举行D20 AI加速卡发布
新品 | LLM-8850 Card, AX8850边缘设备AI加速卡
LLM‑8850 Card是一款面向边缘设备的M.2M-KEY2242 AI加速卡,把42 mm的袖珍体积与AxeraAX8850 SoC的24 TOPS @ INT8算

国芯科技推出可信AI推理卡CCAT200T
长期以来,国芯科技在信息安全以及可信计算领域具有深厚的技术积累和丰富的产品积累。面对人工智能(AI)带来的安全挑战,国芯科技积极投入研发力量,经过研发人员的不懈努力,于近日基于参股公司江


智算加速卡是什么东西?它真能在AI战场上干掉GPU和TPU!
随着AI技术火得一塌糊涂,大家都在谈"大模型"、"AI加速"、"智能计算",可真到了落地环节,算力




评论