 Intel产品调整,Xeon Phi加速卡进入EOL退役阶段
Intel产品调整,Xeon Phi加速卡进入EOL退役阶段

Intel发出产品调整通知,现役仅存的Xeon Phi加速卡(官方称融核处理器)开始进入EOL退役阶段,最后一批货将在2020年7月31日前发出。
现役的Xeon Phi为72x5系列,代号Knights Mills,包括7295、7285和7235,分别是72核(320W)、68核和64核设计,基于14nm工艺,Atom Silvermont架构。
去年7月,代号Knights Landing的上一代产品宣布EOL,今年7月19日前将全部出货完毕。
按照Intel最早的规划,Knights Mills之后本来还有Knights Hills,但已被取消。
Intel解释,Xeon Phi之所以退役是因为客户开始转向其它可替代性的Intel产品。事实上,主要用户高性能计算(HPC)的Xeon Phi加速卡已经不再是Intel部署超算的首选,预计2021年交付美国能源部阿贡实验室的百亿亿次超算“极光”,显卡运算部分基于Intel Xe平台打造。
顺便一提,AMD日前更新了5月份的投资者报告,大家发现官方竟然悄悄删除了第三代锐龙Threadripper处理器,也就是7nm工艺的Ryzen Threadripper 3000系列,很多人还期望能用上64核128线程的“线程撕裂者”呢。虽然还不清楚AMD为何如此变更CPU路线图,不过AMD在5月份的报告中首次确认了Zen 4架构,这是下下下代CPU架构,目前还在设计中。
在本月的投资者报告中,AMD就更新了新一轮的CPU路线图,首次在官方报告中确认了Zen4架构的存在,不过AMD只提到了Zen4架构还在设计中,其他信息欠奉。
考虑到Zen3架构是2020年才能问世的,那Zen4架构至少是2021年的了,距今至少2年时间,届时台积电的5nm EUV工艺也该量产了,那么Zen4架构很可能是基于5nm EUV工艺的。
考虑到英特尔方面的工艺进展,2020年的时候14nm处理器依然会挑大梁,2021年最多还是10nm工艺,传闻中的7nm EUV工艺还没影,在制程工艺上英特尔很有可能要落后两代了。
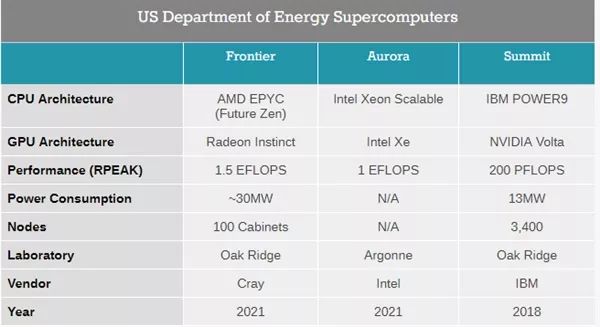
AMD今天宣布联合Cray公司,基于EPYC霄龙处理器(Zen 3或Zen 4架构)、Radeon Instinct加速卡、ROCm开源软件三大平台,为美国能源部橡树岭实验室打造有史以来性能最强的超级计算机“Frontier”,峰值运可达每秒1.5 exaflops(百亿亿次)。
据悉, 每个节点上CPU和GPU的通信为定制化的Infinity Fabric互联技术,可达到高带宽、低时延。
AMD表示,这台超算将于2021年交付,占地两个篮球场,据说价格9位数美元。帮助ORNL的研究人员利用前所未有的计算能力和下一代人工智能技术来搭建、模拟和提高对天气科学、亚原子结构科学、基因组学、物理学和其他重要科学领域现象的理解。
-
intel
+关注
关注
19文章
3510浏览量
191625 -
加速卡
+关注
关注
1文章
75浏览量
11361
原文标题:Intel最后三款融核处理器宣布退役
文章出处:【微信号:kejimx,微信公众号:科技美学】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
选择AMD Alveo V80加速卡的五大理由
AMD Alveo MA35D媒体加速卡的AMA SDK 1.4.0版本发布
FPGA硬件加速卡设计原理图:1-基于Xilinx XCKU115的半高PCIe x8 硬件加速卡 PCIe半高 XCKU115-3-FLVF1924-E芯片

新品 | LLM-8850 Kit,高性能AI加速卡套件 DinMeter v1.1,1/32DIN标准嵌入式开发板

高速信号处理设计方案:413-基于双XCVU9P+C6678的100G光纤加速卡
昆仑芯R200 AI加速卡技术规格解析

深圳光量子工厂启示:PCI 加速卡为何偏向 25MHz 2016 有源晶振?

算力密度翻倍!江原D20加速卡发布,一卡双芯重构AI推理标杆

虚拟电厂加速卡不是噱头!万点规模VPP的性能分水岭
新品 | LLM-8850 Card, AX8850边缘设备AI加速卡

25W 功耗稳跑 104TOPS!H2 加速卡:让智能医疗设备的 AI 分析 “快又稳”
智算加速卡是什么东西?它真能在AI战场上干掉GPU和TPU!


边缘AI运算革新 DeepX DX-M1 AI加速卡结合Rockchip RK3588多路物体检测解决方案

寒武纪基于思元370芯片的MLU370-X8 智能加速卡产品手册详解




评论