 oracle数据恢复—存储掉盘导致Oracle数据库文件大小变为0kb的数据恢复案例
oracle数据恢复—存储掉盘导致Oracle数据库文件大小变为0kb的数据恢复案例

Oracle数据库故障:
存储掉盘超过上限,lun无法识别。管理员重组存储的位图信息并导出lun,发现linux操作系统上部署的oracle数据库中有上百个数据文件的大小变为0kb。数据库的大小缩水了80%以上。
取出&并分析oracle数据库的控制文件。重组存储位图信息,重新导出控制文件中记录的数据文件,发现这些文件的大小依然为0kb。
Oracle数据库数据恢复过程:
1、重组存储位图信息,重新导出这些大小变为0kb的数据文件,这些文件的大小依然是0kb。
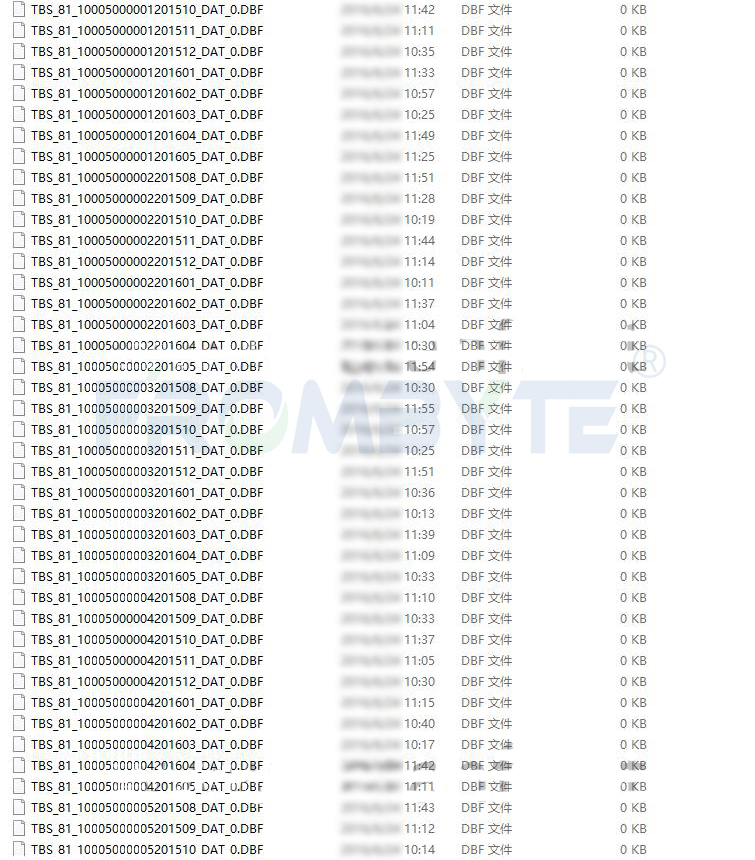
北亚企安数据恢复—oracle数据恢复
2、分析oracle数据库的控制文件,找出这些大小变为0kb的文件对应的文件号(相对文件号)。
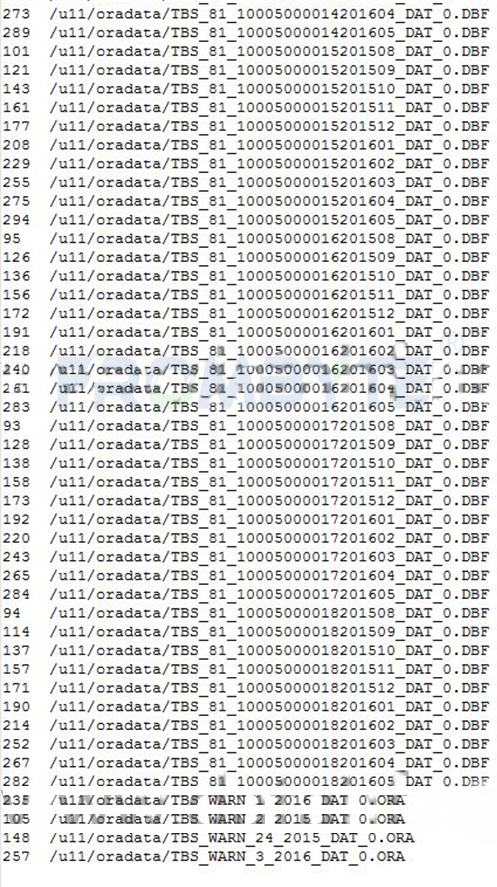
北亚企安数据恢复—oracle数据恢复
3、使用北亚企安自主开发的工具扫描数据库碎片。

北亚企安数据恢复—oracle数据恢复
4、根据文件号拼那些大小变为0kb的数据库数据文件。
5、底层解析这些数据文件,按照用户将这些数据文件导入到新的数据库环境中。
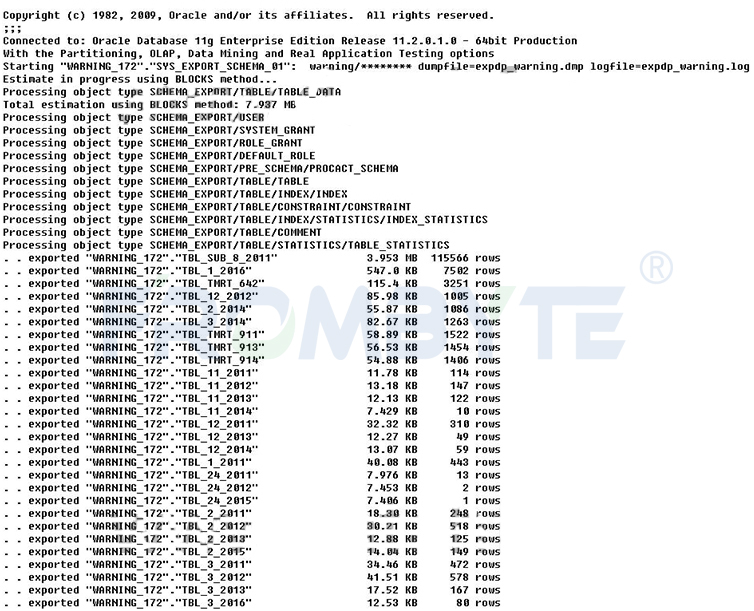
北亚企安数据恢复—oracle数据恢复
6、经过用户方的检测,确认所有数据完全恢复。
审核编辑 黄宇
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
存储
+关注
关注
13文章
4935浏览量
90394 -
数据恢复
+关注
关注
10文章
734浏览量
19077 -
数据库
+关注
关注
7文章
4092浏览量
68682
发布评论请先 登录
相关推荐
热点推荐
数据库数据恢复—北京某国企Oracle数据库Truncate数据丢失恢复案例
北京某国企客户在业务运维过程中,误执行TRUNCATE TABLE CM_CHECK_ITEM_HIS操作,导致该表数据被清空,业务查询该表时出现报错。同时客户发现现有数据库备份不可用,无法通过常规备份方式

MySQL数据库备份恢复方式对比
备份是数据库运维中最重要也最容易被忽视的环节。"重要"体现在数据丢失时备份是唯一的救命稻草,"忽视"体现在很多团队有备份脚本但从未做过恢复演练,等到真正需要恢复时才发现备份
Oracle数据库ASM实例无法挂载的数据恢复案例
一个Oracle数据库故障表现为ASM磁盘组掉线,ASM实例无法挂载(mount)。数据库管理员自行进行简单修复,未能成功,随后联系北亚数据恢复

Netapp数据恢复—误删NetApp卷数据:从崩溃到恢复的实战复盘
NetApp存储数据恢复环境:
NetApp某型号存储存储上有96块SAS接口硬盘,硬盘扇区大小是520字节。所有lun映射到小型机使用,
服务器数据恢复—EqualLogic存储上raid5磁盘阵列数据恢复案例
服务器存储数据恢复环境&故障:
某品牌EqualLogic PS6100存储阵列上有一组由16块硬盘组建的raid5磁盘阵列。磁盘阵列上层划分多个
服务器数据恢复—硬盘指示灯亮黄灯,RAID5崩溃数据这样恢复
服务器存储数据恢复环境:
某单位一台某品牌DS5300存储,1个机头+4个扩展柜,50块的硬盘组建了两组RAID5阵列。一组raid5阵列有27块硬盘,存放
mysql数据恢复—mysql数据库表被truncate的数据恢复案例
某云ECS网站服务器,linux操作系统,部署了mysql数据库。工作人员在执行数据库版本更新测试时,错误地将本应在测试库执行的sql脚本在生产库上执行了,

服务器数据恢复—服务器存储黄灯预警,数据恢复“大作战”
某单位的一台某品牌存储设备,该系统由1个机头+4个扩展柜组成,一共有50块硬盘组建了两组RAID5阵列。上层划分了11个卷。
一组RAID崩溃,该组RAID由27块硬盘组建,存放的是Oracle数据库文件。
服务器不可用,已
数据库数据恢复—服务器异常断电导致Oracle数据库故障的数据恢复案例
备份,仅有一些断断续续的归档日志。
Oracle数据库恢复流程:
1、检测数据库故障情况;
2、尝试挂起并修复数据库;
3、解析
Oracle数据恢复—格式化分区导致Oracle数据库报错的数据恢复案例
完成后将所有硬盘按照原样还原到原服务器中,后续的数据分析和数据恢复操作基于镜像文件进行,避免对原始磁盘数据造成二次破坏。基于镜像

服务器数据恢复—raid5阵列多块硬盘离线导致raid崩溃的数据恢复
一台服务器中有5块硬盘,其中的4块组建了一组RAID5阵列,剩下一块盘作为热备盘(Hot-Spare)使用。服务器操作系统为linux,应用系统为构架于oracle数据库的一个oa。

数据库数据恢复—MongoDB数据库文件丢失的数据恢复案例
将MongoDB数据库文件拷贝到其他分区,数据复制完成后将MongoDB数据库原先所在的分区进行了格式化操作。
结果发现拷贝过去的数据无法使用。管理员又将
数据库数据恢复—SQL Server数据库被加密如何恢复数据?
SQL Server数据库故障:
SQL Server数据库被加密,无法使用。
数据库MDF、LDF、log日志文件名字被篡改。

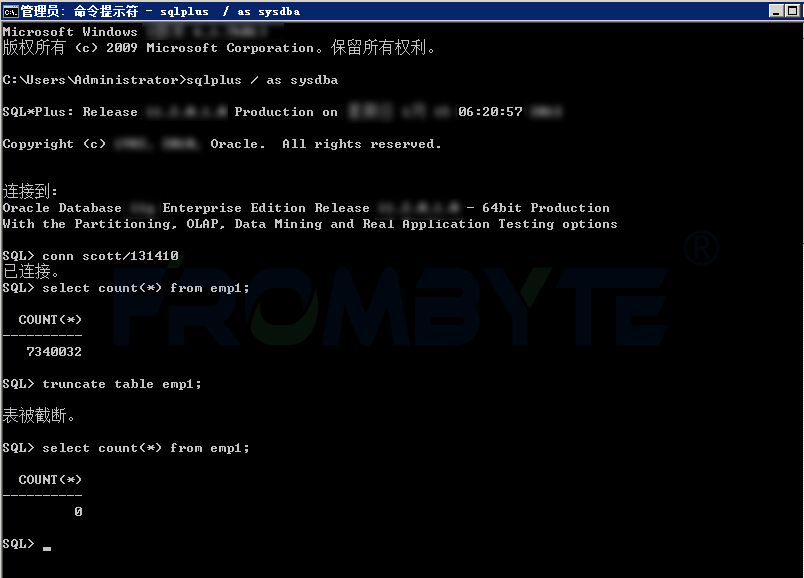
oracle数据恢复—oracle数据库误执行错误truncate命令如何恢复数据?
oracle数据库误执行truncate命令导致数据丢失是一种常见情况。通常情况下,oracle数据库



评论