 基于AX650N+CLIP的以文搜图展示
基于AX650N+CLIP的以文搜图展示

一
背景
元气满满的10月份就结束了,时间不长,却产出了上千张照片,找到自己想要的照片有点难度。希望有一种精确的以文搜图的方法,快速定位到某一类图片(例如:金色头发的小姐姐……)。
之前大家熟悉的计算机视觉模型(CV)基本上是采用监督学习的方式,基于某一类数据集进行有限类别的任务学习。这种严格的监督训练方式限制了模型的泛化性和实用性,需要额外的标注数据来完成训练时未曾见过的视觉“概念”。
能否有一种“识别万物”的图像识别大模型呢?今天就借此机会,通过实操来重温下由OpenAI在2021年初发布的Zero-Shot视觉分类模型CLIP,并移植到爱芯派Pro上实现简单的以图搜文示例。
二
CLIP
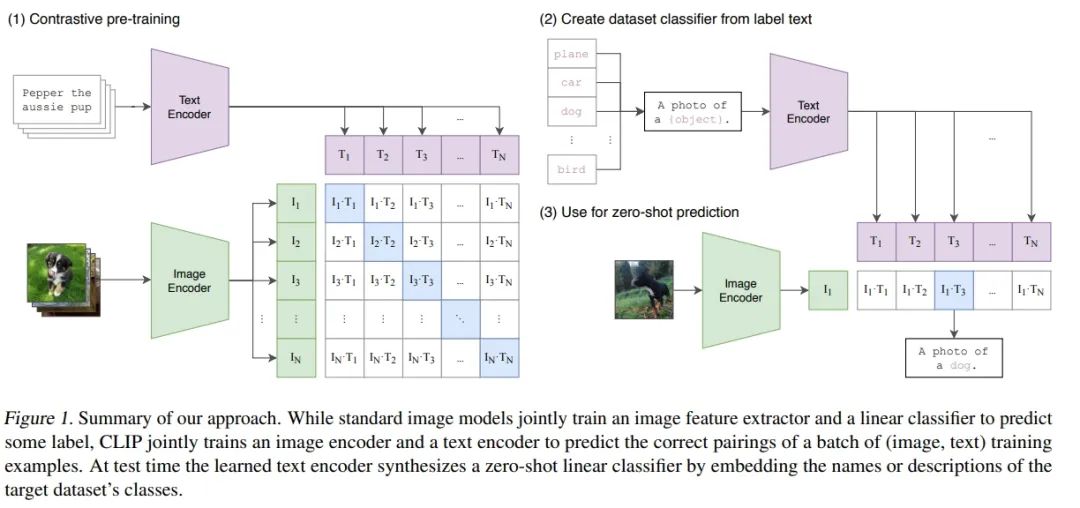
Summary of our approach
2021年初由OpenAI发布的Zero-shot的视觉分类模型CLIP(Contrastive Language–Image Pre-training),该预训练的模型在没有微调的情况下在下游任务上取得了很好的迁移效果。作者在30多个数据集上做了测试,涵盖了OCR、视频中的动作检测、坐标定位等任务。作者特意强调了CLIP的效果:没有在ImageNet上做微调的CLIP,竟然能和已经在ImageNet上训练好的ResNet 50打成平手,简直不可思议。
● CLIP网站:
https://openai.com/research/clip
● CLIP论文:
https://arxiv.org/abs/2103.00020
深度学习在CV领域很成功,但是现在大家使用最多的强监督学习方案总体而言存在以下问题:
● CV数据集标注劳动密集,成本高昂
● 模型只能胜任一个任务,迁移到新任务上非常困难
● 模型泛化能力较差
2.1 预训练
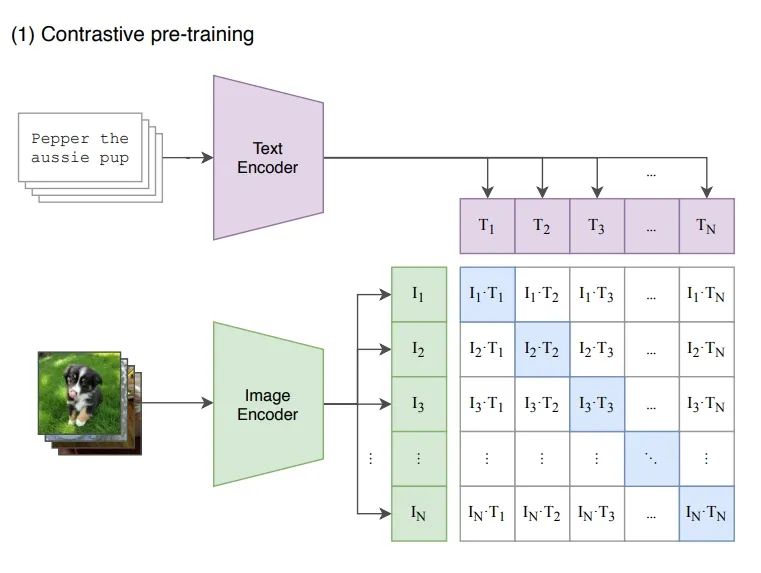
OpenAI的这项工作CLIP可以解决上述问题,思路看起来很简单,看下图就知道了,简单来说CLIP是使用Text Encoder从文本中提取的语义特征和Image Encoder从图像中提取的语义特征进行匹配训练:
pre training
2.2 推理
接下来是Zero-Shot的推理过程。给定一张图片,如何利用预训练好的网络去做分类呢?这里作者很巧妙地设置了一道“多项选择”。具体来说,我给网络一堆分类标签,比如cat, dog, bird,利用文本编码器得到向量表示。然后分别计算这些标签与图片的余弦相似度;最终相似度最高的标签即是预测的分类结果。
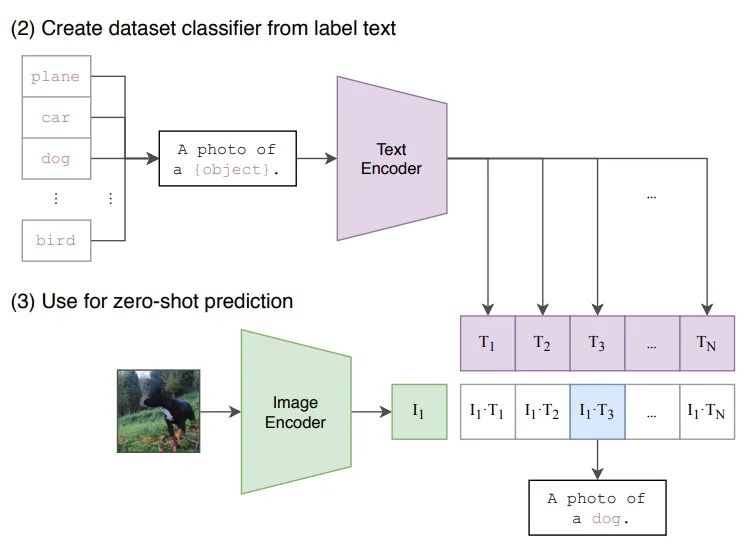
Zero-Shot prediction
从论文中公开的效果非常不错,CLIP的Zero-Shot迁移能力非常强。在ImageNet各种系列分类任务上,CLIP无需ImageNet标注数据训练,通过Zero-Shot分类效果就可以达到ResNet监督训练结果,并且泛化性和鲁棒性更好。
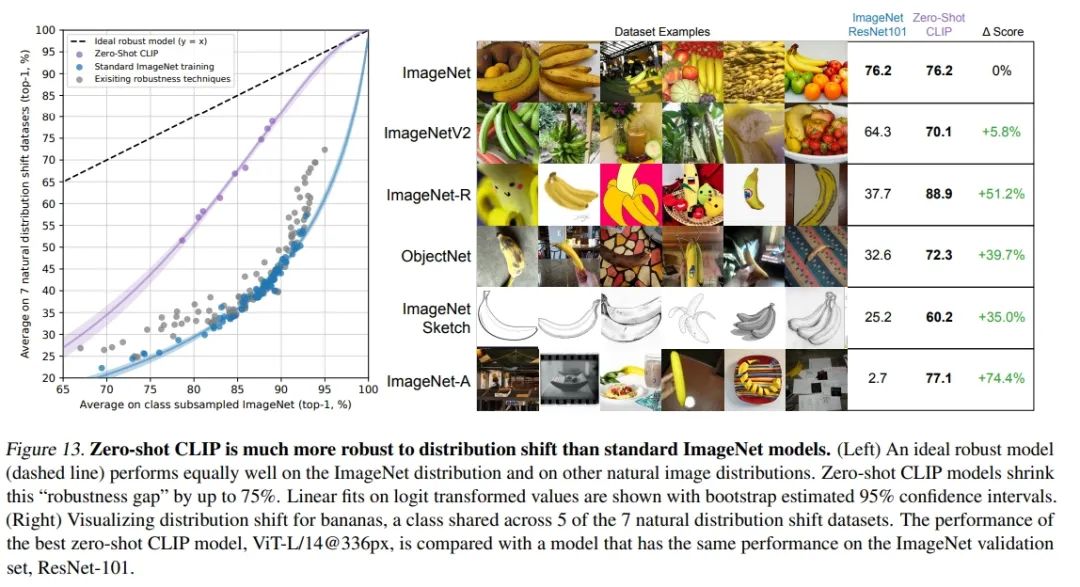
CLIP on ImageNet
三
爱芯派Pro(AX650N)
搭载爱芯元智第三代高能效比智能视觉芯片AX650N。集成了八核Cortex-A55 CPU,10.8TOPs@INT8 NPU,支持8K@30fps的ISP,以及H.264、H.265编解码的VPU。接口方面,AX650N支持64bit LPDDR4x,多路MIPI输入,千兆EtherNet、USB、以及HDMI 2.0b输出,并支持32路1080p@30fps解码内置高算力和超强编解码能力,满足行业对高性能边缘智能计算的需求。通过内置多种深度学习算法,实现视觉结构化、行为分析、状态检测等应用,高效率支持Transformer模型和视觉大模型。提供丰富的开发文档,方便用户进行二次开发。

爱芯派Pro(AX650N inside)
四
上板示例
为了方便大家快速体验CLIP的效果,我们在Github上开源了对应的DEMO以及相关预编译好的NPU模型,方便大家快速体验。
● Github链接:
https://github.com/AXERA-TECH/CLIP-ONNX-AX650-CPP
提供的DEMO包内容说明
|
文件名 |
描述 |
|
main |
DEMO执行程序 |
|
image_encoder.axmodel |
图像编码模型(AX650N NPU) |
|
image_encoder.onnx |
图像编码模型(CPU) |
|
images |
测试图片集 |
|
text_encoder.onnx |
文本编码模型 |
|
text.txt |
文本输入序列 |
|
vocab.txt |
文本词集 |
|
feature_matmul.onnx |
特征比对模型 |
4.1 耗时统计
CLIP image encoder的模型,我们采用精度更好的基于ViT-B的Backbone
|
Backbone |
输入尺寸 |
参数量 |
计算量 |
|
ViT-B/32 |
1,3,224,224 |
86M |
4.4G MACs |
单独运行的耗时分析如下:
root@maixbox:~/qtang/CLIP# /opt/bin/ax_run_model -m image_encoder.axmodel -w 3 -r 10
Run AxModel:
model: image_encoder.axmodel
type: NPU3
vnpu: Disable
affinity: 0b001
repeat: 10
warmup: 3
batch: 1
pulsar2 ver: 1.8-patch1 6fa8d395
engine ver: [Axera version]: libax_engine.so V1.27.0_P3_20230627143603 Jun 27 2023 14:58:22 JK 1.1.0
tool ver: 1.0.0
cmm size: 93238580 Bytes
------------------------------------------------------
min = 4.158 ms max = 4.220 ms avg = 4.198 ms
------------------------------------------------------
从上面可以看出,使用AX650N上的NPU运行image encoder,最快可以达到238 images/秒的特征提取速度,也就是说只需短短的4.2秒就能完成前面提及到的1000张照片的特征提取。
4.2 测试一
使用5张图片,简单来展示下CLIP具体的效果

5张测试图片
测试结果
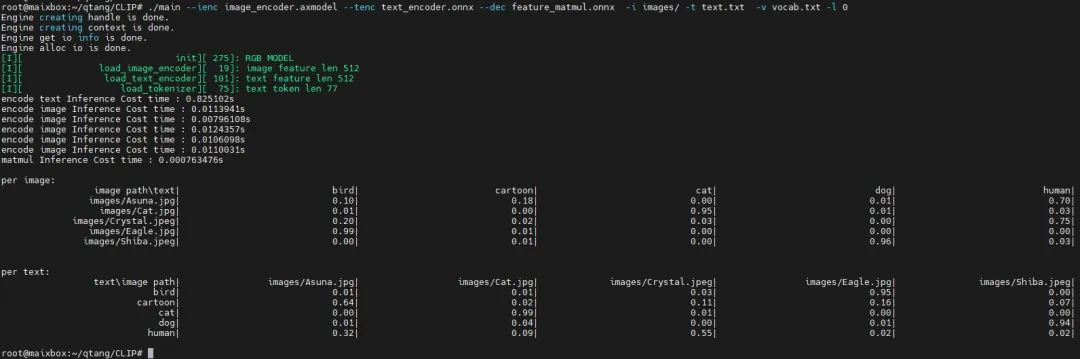
批量测试
从实际上板运行log可以看出,最后的特征匹配“matmul Inference”耗时<0.0008s,也就是不到1毫秒就能从1000张图片中搜索到与文本对应的置信度最高的图片。
4.3 测试二
下面是AX650N上CLIP DEMO的Pipeline分别使用CPU后端和NPU后端运行image encoder模型的耗时&CPU负载对比:
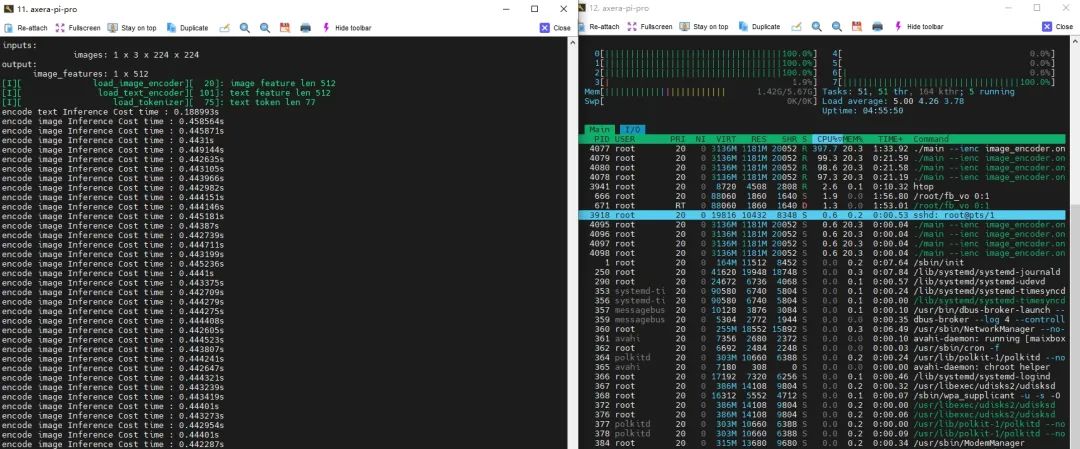
CPU版本
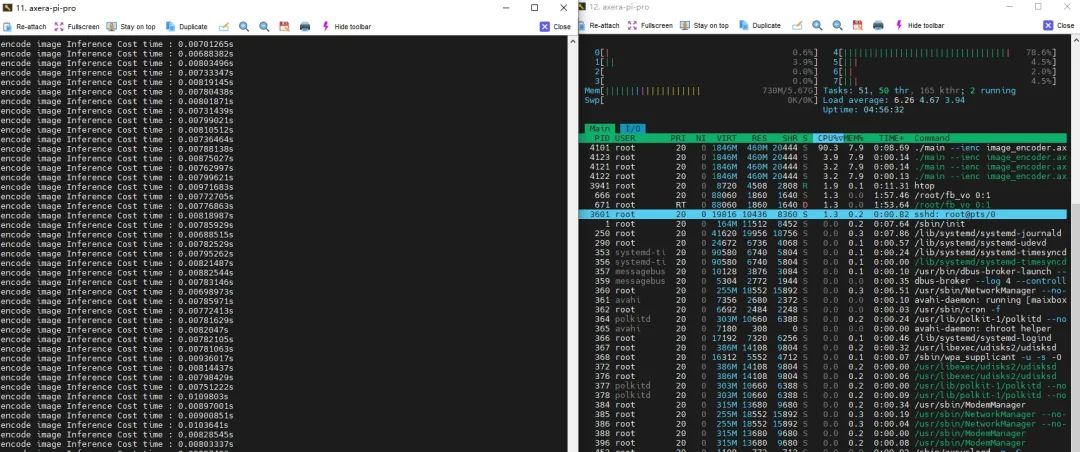
NPU版本
|
Pipeline各模块统计 |
CPU |
NPU |
|
耗时 |
440 ms |
7 ms |
|
CPU负载 (满载800%) |
397% |
90% |
|
内存占用 |
1181 MiB |
460 MiB |
4.3 测试三
前面介绍的是Meta开源的英文语料的CLIP模型,当然也有社区大佬提供了中文语料微调模型:
输入图片集:

input images
输入文本:“金色头发的小姐姐”
输出结果:
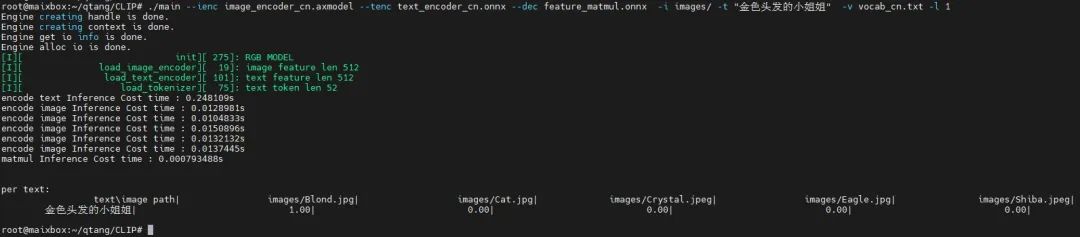
CLIP中文示例
五
交互示例
我们最近还更新了基于爱芯派Pro的交互式以文搜图示例,更加直观的展现其功能。
● Demo安装步骤可参考
https://github.com/AXERA-TECH/CLIP-ONNX-AX650-CPP/releases
六
结束语
随着Vision Transformer网络模型的快速发展,越来越多有趣的AI应用将逐渐从云端服务迁移到边缘侧设备和端侧设备。例如基于本文提及到的CLIP模型,在端侧可以实现以下场景应用:
●事件抓拍相机,实时抓拍监控场景下各种突发事件
●事件快速回溯,从海量的视频数据中快速找到某一特点人物和事件
●智能NAS,家用私有网盘不再担心找不到照片
同时为了降低社区开发者Transformer模型在边缘侧移植的研究门槛,业界优秀的开源智能硬件公司矽速科技推出的基于AX650N的社区开发板爱芯派Pro(MAIX-IV)已经正式上架,欢迎关注。
-
图像识别
+关注
关注
9文章
534浏览量
40186 -
计算机视觉
+关注
关注
9文章
1715浏览量
47723 -
数据集
+关注
关注
4文章
1240浏览量
26261
原文标题:爱芯分享 | 基于AX650N+CLIP的以文搜图展示
文章出处:【微信号:爱芯元智AXERA,微信公众号:爱芯元智AXERA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
安森美 NVMFD5C650NL 双 N 沟道 MOSFET 深度剖析
1688图搜接口选品的好帮手
onsemi NTP095N65S3HF 650V N沟道MOSFET深度解析
深入剖析NTD360N65S3H:高性能650V N沟道MOSFET
探索 onsemi NTH4LN040N65S3H 650V N 沟道功率 MOSFET
onsemi FCB070N65S3:650V N沟道功率MOSFET的卓越性能与应用
深入解析FCPF650N80Z N沟道SuperFET® II MOSFET
探究 onsemi FCP190N65S3 650V N 沟道 MOSFET 特性与应用
京东图片搜索API深度解析:以图搜货赋能电商全场景
TE Connectivity CROWN CLIP Sr. 420A电源连接器技术解析与应用指南
格灵深瞳多模态大模型Glint-ME让图文互搜更精准

1688 多模态搜索从 0 到 1:逆向接口解析与 CLIP 特征匹配实践
Immich智能相册在树莓派5上的高效部署与优化



评论