 XCVU9P光纤加速卡设计方案第410篇:基于XCVU9P+ C6678的100G光纤的加速卡
XCVU9P光纤加速卡设计方案第410篇:基于XCVU9P+ C6678的100G光纤的加速卡

|
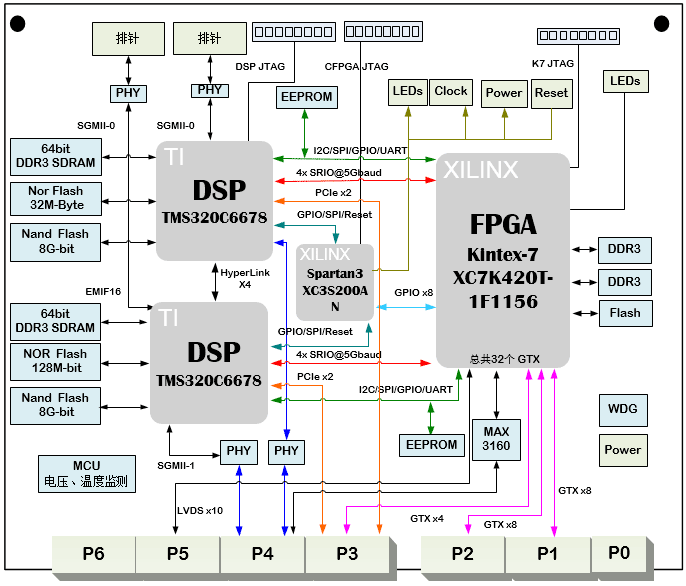
一、板卡概述 二、技术指标 •板卡为自定义结构,板卡大小332mmx260mm; •FPGA采用XilinxVirtexUltralSCALE+系列芯片XCVU9P; •FPGA挂载4组FMCHPC连接器; •板载4路QSPF+,每路数据速率100Gb/s; •DSP处理器采用TI8核处理器TMS320C6678; •DSP外挂一组64-bitDDR3颗粒,总容量1GB,数据速率1333Mb/s; •DSP采用EMIF16NorFlash加载模式,NorFlash容量32MB; •DSP外挂一路千兆以太网1000BASE-T; •FPGA与DSP之间通过RapidIOx4互联。 三、软件 •CFPGA加载测试代码; •CFPGA对电源、时钟、复位等控制测试代码; •CFPGA部分SPI/GPIO等接口测试代码; •DSP部分Flash加载测试代码; •DSP部分DDR3接口测试代码; •DSP网口部分测试代码; •DSP与FPGA之间SRIO测试代码; •DSP部分SPI/IIC/GPIO接口测试代码; •XCVU9P部分BPI加载测试代码; •XCVU9P部分QSFP+测试代码; •XCVU9P部分FMC搭配子卡测试代码; 四、物理特性: •工作温度:商业级0℃~+55℃,工业级-40℃~+85℃; •工作湿度:10%~80%; 五、供电要求: •直流电源供电,整板大功耗100W; •供电电压:12V/10A; •电源纹波:≤10%; 六、应用领域 高速数据采集,无线通信。 |
XCVU9P光纤加速卡, 高速数据采集, 无线通信, C6678板卡
审核编辑黄宇
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
光纤
+关注
关注
20文章
4502浏览量
81365 -
数据采集
+关注
关注
42文章
8409浏览量
121399
发布评论请先 登录
相关推荐
热点推荐
AMD正式推出Instinct MI350P PCIe GPU加速卡
AMD于2026年5月8日正式推出Instinct MI350P PCIe GPU加速卡,作为四年来首款面向企业级市场的PCIe接口Instinct系列产品,其以“精简架构+极致能效”为核心,专为AI推理任务优化,实现从部署到运行的“开箱即用”体验,重新定义企业级AI
瀚博半导体载天VA16加速卡成功适配DeepSeek-V4大模型
4月24日,深度求索正式开源全新系列模型DeepSeek-V4。瀚博半导体第一时间完成载天VA16加速卡的FP4+FP8 混合精度适配,加速大模型高并发、低成本落地。
选择AMD Alveo V80加速卡的五大理由
AMD Alveo V80 加速卡专为需要实时加速的企业数据中心和云服务提供商而设计,它结合了可编程逻辑、片上高带宽内存( HBM )、高速网络核心以及网络直连接口,可实现实时性能。Alveo
综合图像处理硬件平台设计资料:2-基于6U VPX的双TMS320C6678+Xilinx FPGA K7 XC7K420T的图像信号处理板
FPGA光纤, XCVU9P板卡, 高速图像采集, 基带信号处理, 加速计算卡, 无线仿真平台, 图像信号处理板
FPGA硬件加速卡设计原理图:1-基于Xilinx XCKU115的半高PCIe x8 硬件加速卡 PCIe半高 XCKU115-3-FLVF1924-E芯片
FPGA硬件加速, PCIe半高卡, XCKU115, 光纤采集卡, 信号计算板, 硬件加速卡

新品 | LLM-8850 Kit,高性能AI加速卡套件 DinMeter v1.1,1/32DIN标准嵌入式开发板
LLM-8850KitLLM-8850Kit是一款面向边缘AI与嵌入式计算场景的高性能AI加速卡套件,由LLM-8850CardAI加速卡与LLM-8850PiHat转接板组成。核心加速卡

高速信号处理设计方案:413-基于双XCVU9P+C6678的100G光纤加速卡
C6678, XCVU9P, ZU19EG开发板,, 高速信号处理, 光纤加速卡, XCVU9P光纤
3U VPX板卡设计原理图:821-基于RFSOC的8路5G ADC和8路9G的DAC 3U VPX卡
3uvpx板卡, DA输出核心板, RFSOC, XCVU9P芯片, 信号输出播放, 硬件加速卡, 3U VPX板卡

专为边缘而生:深度解析昆仑芯K100 AI加速卡,释放128 TOPS极致能效
昆仑芯K100边缘AI加速卡以75W超低功耗实现128 TOPS的INT8算力,重新定义边缘推理能效标准。其半高半长设计搭载8GB HBM内存与256GB/s带宽,支持INT8至FP32多精度计算

深圳光量子工厂启示:PCI 加速卡为何偏向 25MHz 2016 有源晶振?
在 PCI 加速卡项目中,工程师使用SJK 2016 系列有源晶振 25MHZ。原因不仅仅是规格匹配,更在于系统复杂度。

【TES818 】青翼凌云科技基于 VU13P FPGA+ZYNQ SOC 的 8 路 100G 光纤通道处理平台
TES818是一款基于VU13PFPGA+XC7Z100SOC的8路100G光纤通道处理平台,该平台采用一片Xilinx的VirtexUltraScale+系列FPGA(XCVU13P

设计资料:基于PCIe3.0X16的的100G光纤采集存储设备
光纤数据采集存储板, 光纤采集存储设备, 医疗影像, VU3P板卡, 高速光纤采集卡, 光纤采集

虚拟电厂加速卡不是噱头!万点规模VPP的性能分水岭
。 此时仅靠边缘MPU/CPU的通用算力,可能无法及时处理数据清洗、异常检测、指令下发校验等任务,而加速卡(如 GPU、FPGA 加速卡)的并行计算能力可快速消化数据洪流,避免“小包风暴”导致的系统卡顿。 虚拟电厂对AG
智算加速卡是什么东西?它真能在AI战场上干掉GPU和TPU!
随着AI技术火得一塌糊涂,大家都在谈"大模型"、"AI加速"、"智能计算",可真到了落地环节,算力才是硬通货。你有没有发现,现在越来越多的AI企业不光用GPU,也不怎么迷信TPU了?他们嘴里多了一个新词儿——智算加速卡。

设计原理图:U200E 基于VU9P的4路QSFP28光纤PCIeX16收发卡
基于XCVU9P的4路QSFP28光纤PCIeX16收发卡。该板卡要求符合PCIe 3.0标准,包含一片XCVU9P-2FLGA2014I、4组64-bit/8GB DDR4;4路QSFP28 4X



评论