 AMD正式推出Instinct MI350P PCIe GPU加速卡
AMD正式推出Instinct MI350P PCIe GPU加速卡

AMD于近日正式推出Instinct MI350P PCIe GPU加速卡,作为四年来首款面向企业级市场的PCIe接口Instinct系列产品,其以“精简架构+极致能效”为核心,专为AI推理任务优化,实现从部署到运行的“开箱即用”体验,重新定义企业级AI加速硬件的性价比与易用性。
技术突破:CDNA 4架构与制程工艺的协同创新
- 架构与制程 :基于全新CDNA 4架构,采用台积电3纳米制程工艺,集成4颗XCD计算芯片(较MI350X的8颗减半),搭配1颗台积电6纳米工艺I/O芯片。这种“计算核心精简+I/O专用化”设计,在保证推理性能的同时,显著降低功耗与成本。
- 性能参数 :单精度浮点性能达100 TFLOPS,整数精度(INT8)性能达400 TOPS,较前代MI300X提升30%。其1500MHz基础频率与2.5GHz睿频能力,支持动态频率调整以适配不同负载场景。
- 内存与带宽 :配备128GB HBM3e内存,带宽达5.12TB/s,较MI350X提升20%,满足大模型推理中的高带宽需求。PCIe 5.0接口支持128GT/s传输速率,实现与CPU的高效数据交互。
应用场景:企业级AI推理的全场景覆盖
- 云服务与数据中心 :在AWS、微软Azure等云平台中,MI350P支持大规模AI推理集群部署,单卡可同时处理200路以上视频流分析,或运行千亿参数大模型的实时推理。
- 边缘计算与工业应用 :在工业质检、智慧城市等边缘场景中,其低功耗特性(TDP 350W)与高可靠性,支持7×24小时稳定运行。在智能制造场景中,可实现0.1秒级缺陷检测与实时反馈。
- 科研与高性能计算 :在基因测序、气候模拟等科研场景中,MI350P的并行计算能力可加速复杂算法执行,提升科研效率。
市场影响:推动企业级AI加速硬件的“易用性革命”
- 部署效率提升 :通过PCIe接口标准化与预集成软件栈(如ROCm 6.0),企业无需定制化开发即可实现快速部署,开发周期缩短50%以上。
- 成本优化 :较MI350X成本降低40%,使AI推理加速硬件从“高端配置”向“标准配置”演进。预计到2028年,全球企业级AI推理加速卡市场规模将突破200亿美元,MI350P有望占据20%以上份额。
- 生态协同 :AMD通过开放硬件接口与软件工具链,支持与NVIDIA CUDA生态的兼容与互操作,降低企业迁移成本。其与英特尔、AMD CPU的协同优化,构建了从硬件到软件的全链条解决方案。
站在AI推理加速的产业前沿,AMD Instinct MI350P不仅解决了传统企业级GPU“部署复杂、成本高昂”的痛点,更通过架构创新与生态协同,为AI推理任务的规模化落地提供了“高性价比、易用性强”的硬件基石。随着生成式AI、大模型推理等场景的普及,该产品将成为企业级AI基础设施的核心组件,推动AI从“实验阶段”向“生产阶段”的范式转变,开启企业级AI加速的新纪元。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
amd
+关注
关注
25文章
5712浏览量
140475 -
gpu
+关注
关注
28文章
5295浏览量
136116 -
硬件
+关注
关注
13文章
3643浏览量
69185 -
PCIe
+关注
关注
16文章
1486浏览量
89009 -
PCIe接口
+关注
关注
0文章
129浏览量
10657
发布评论请先 登录
相关推荐
热点推荐
选择AMD Alveo V80加速卡的五大理由
AMD Alveo V80 加速卡专为需要实时加速的企业数据中心和云服务提供商而设计,它结合了可编程逻辑、片上高带宽内存( HBM )、高速网络核心以及网络直连接口,可实现实时性能。Alveo
AMD Alveo MA35D媒体加速卡的AMA SDK 1.4.0版本发布
我们非常高兴地宣布,面向 AMD Alveo MA35D 媒体加速卡的最新 AMA SDK 1.4.0 版本现已发布。该版本旨在为要求严苛的媒体工作负载提供坚如磐石的稳定性和性能提升。此次更新体现了我们致力于优化平台以适应生产环境的承诺,确保客户能够自信地扩展视频处理能力
伟创力与AMD进一步深化战略合作
近日,伟创力宣布与全球领先的高性能与自适应计算芯片公司 AMD(超威半导体) 进一步深化战略合作,在美国本土制造 AMD Instinct 平台,加速先进 AI 基础设施落地。作为合作
FPGA硬件加速卡设计原理图:1-基于Xilinx XCKU115的半高PCIe x8 硬件加速卡 PCIe半高 XCKU115-3-FLVF1924-E芯片
FPGA硬件加速, PCIe半高卡, XCKU115, 光纤采集卡, 信号计算板, 硬件加速卡

新品 | LLM-8850 Kit,高性能AI加速卡套件 DinMeter v1.1,1/32DIN标准嵌入式开发板
LLM-8850KitLLM-8850Kit是一款面向边缘AI与嵌入式计算场景的高性能AI加速卡套件,由LLM-8850CardAI加速卡与LLM-8850PiHat转接板组成。核心加速卡

高速信号处理设计方案:413-基于双XCVU9P+C6678的100G光纤加速卡
C6678, XCVU9P, ZU19EG开发板,, 高速信号处理, 光纤加速卡, XCVU9P光纤加速卡
昆仑芯R200 AI加速卡技术规格解析
昆仑芯R200加速卡基于7nm XPU-R架构,在150W功耗下提供256 TOPS INT8算力,侧重高性能推理。配备最高32GB GDDR6内存(512GB/s带宽)及108路视频解码能力,支持

深圳光量子工厂启示:PCI 加速卡为何偏向 25MHz 2016 有源晶振?
在 PCI 加速卡项目中,工程师使用SJK 2016 系列有源晶振 25MHZ。原因不仅仅是规格匹配,更在于系统复杂度。

虚拟电厂加速卡不是噱头!万点规模VPP的性能分水岭
。 此时仅靠边缘MPU/CPU的通用算力,可能无法及时处理数据清洗、异常检测、指令下发校验等任务,而加速卡(如 GPU、FPGA 加速卡)的并行计算能力可快速消化数据洪流,避免“小包风暴”导致的系统
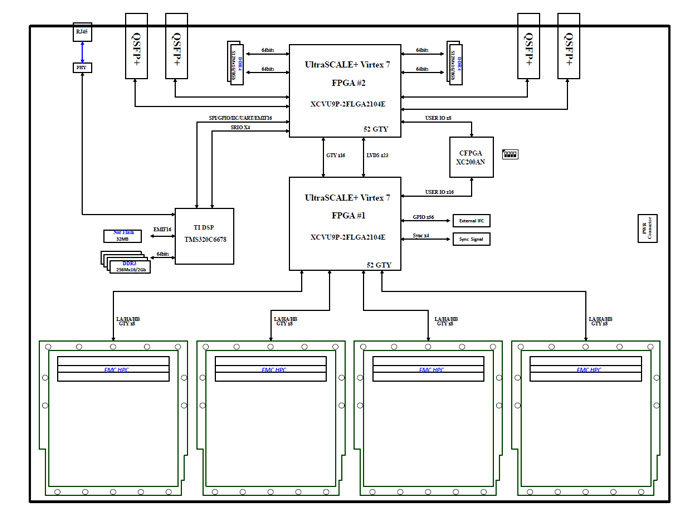
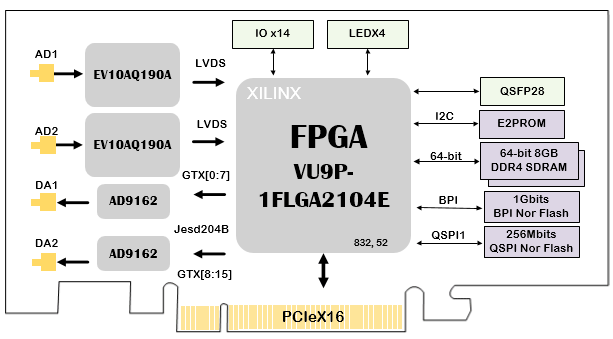
PCIe数据卡设计资料第611篇-基于VU9P的双路5Gsps AD 双路6Gsps DA PCIe数据卡
PCIe数据卡, VU9P, VU9P板卡, VU9P处理板, VU9P核心板
PCIe协议分析仪能测试哪些设备?
训练环境中高效的数据交换。
异构计算集群
测试场景:在包含CPU、GPU、FPGA等多种计算单元的系统中,分析各组件间的PCIe通信模式。
应用价值:优化任务调度和数据流,提升整体计算效率。
扩展卡
发表于 07-25 14:09
aicube的n卡gpu索引该如何添加?
请问有人知道aicube怎样才能读取n卡的gpu索引呢,我已经安装了cuda和cudnn,在全局的py里添加了torch,能够调用gpu,当还是只能看到默认的gpu0,显示不了
发表于 07-25 08:18
重磅!AMD将恢复向中国出口MI308芯片!
电子发烧友网获悉,AMD向中国出口的MI308芯片将恢复出货。AMD方面表示,“我们最近收到特朗普政府的通知,向中国出口MI308产品的许可证申请将被推进至审核流程。我们计划在许可证获
智算加速卡是什么东西?它真能在AI战场上干掉GPU和TPU!
随着AI技术火得一塌糊涂,大家都在谈"大模型"、"AI加速"、"智能计算",可真到了落地环节,算力才是硬通货。你有没有发现,现在越来越多的AI企业不光用GPU,也不怎么迷信TPU了?他们嘴里多了一个新词儿——智算加速卡。





评论