 通过移动图形处理单元可以提高性能
通过移动图形处理单元可以提高性能

如果实施得当,移动系统中的 GPU 可以提高性能。但这是一个很大的“如果”。
移动 GPU 或图形处理单元是专用的协处理器,旨在加速智能手机、平板电脑、可穿戴设备和 IoT 设备上的图形应用程序、用户界面和 3D 内容。逼真的 3D 游戏和“实时”图形用户界面 (GUI) 是专为 GPU 设计的工作负载示例。
几年前,GPU 是一个很好的功能,设计用于需要最新技术来保持其旗舰地位的高端消费移动产品。现在,随着图形显示无处不在并用于各种连接设备,GPU 已成为所有移动应用处理器和中/高端 MCU/MPU 产品规格的必要组成部分。GPU 还有助于产品差异化,因此公司可以为其目标应用程序创建引人注目的、以视觉为中心的解决方案。
GPU 设计为单指令多数据 (SIMD) 处理引擎,专为大规模并行工作负载而构建。3D 图形是高吞吐量并行处理的最佳示例之一,因为 GPU 每秒可以处理数十亿个像素/顶点或浮点运算 (GFLOPS)。GPU 的核心是一个或多个着色器(SIMD 单元),它们处理独立的顶点、图元和片段(像素)。着色器是按顶点、按像素或其他基元执行 3D 图形程序的计算元素。
顶点着色器程序修改对象属性以实现对位置、移动、顶点光照和颜色的控制。像素或片段着色器程序计算最终的像素颜色、阴影、对象纹理、照明,并且可以通过编程为场景添加特殊效果,例如模糊、边缘增强或过滤。还有更新类型的着色器程序,包括几何、曲面细分和计算着色器。
像 OpenGL ES 3.1 中的计算着色器对于高级图形渲染非常有用,您可以在其中混合 3D 和 GPU 计算 (GPGPU) 上下文以添加真实效果,如物理处理(游戏中的自然波浪和风运动或生动的爆炸)和全局照明(通过涉及直接和间接光源/光线的计算获得更好的照明和阴影)。GPU 还可以从一个着色器单元有效地扩展到数千个互连的分组着色器单元,以根据从物联网和移动到高性能计算 (HPC) 科学计算的目标应用程序提高性能和并行性。高性能着色器设计可以运行在 1.2 GHz 以上,每个周期执行数十亿条指令,以处理图形、OpenCL、OpenVX(视觉处理)等。
图 1 显示了 CPU 和 GPU 架构之间的一些主要区别。每种设计都有其优势,必须协同工作以实现最优化的解决方案(功率、带宽、资源共享等)。最好的设计使用异构系统架构,根据其优势将工作负载拆分/分配给每个处理核心。随着行业向平台级优化发展,GPU 也正在成为系统的重要组成部分,其中 GPU 用于图形以外的计算密集型应用程序。请注意,在当今的混合设计中,还有其他计算模块,包括 DSP、FPGA 和其他可以与 CPU-GPU 组合一起使用的任务特定内核。

图1
GPU流水线介绍
较新的 GPU 使用“统一”着色器来实现跨不同类型着色器程序的最佳硬件资源管理,以平衡工作负载。统一着色器的第一个版本结合了顶点 (VS) 和像素 (PS) 处理,随着图形 API 的发展,后续版本增加了对几何 (GS)、曲面细分 (TS) 和计算 (CS) 着色器的支持。
对于统一着色器,分配给每个着色器的工作负载可以是基于顶点或基于像素的,允许着色器在任一上下文之间即时切换以保持高水平的着色器利用率。如果您有一个顶点或像素重的图像,这可以最大限度地减少硬件资源瓶颈和停滞。在非统一着色器架构中,有单独的、固定的 VS 和 PS 着色器。例如,如果图像的顶点很重,VS 可能会停止 GPU 管道,因为它需要在 GPU 继续处理图像的其余部分之前完成。这会导致管道泡沫和硬件的低效使用。图 2 显示了一个单独的 VS 和 PS 与一个统一的着色器核心的情况。
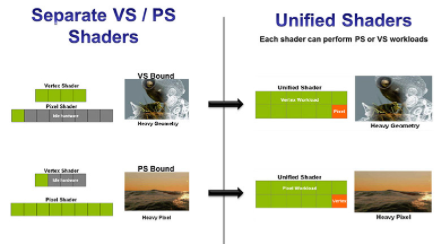
图 2
多年来,GPU 着色器已经超越了图形,包括通用管道,可配置用于图形、计算、图像 (ISP) 协同处理、嵌入式视觉、视频(HEVC 和 H.264 前/后处理等) 。),以及其他并行应用程序。这就是为什么您会听到诸如 GPGPU(通用 GPU)和 GPU 计算之类的术语来描述 GPU 在图形渲染之外的广泛使用。
从高层次上看,移动 GPU 管道由多个关键块组成:
主机接口和(安全)MMU
通过 ACE-Lite/AXI/AHB 接口与 CPU 通信。
处理来自 CPU 的命令并从帧缓冲区或系统内存访问几何数据。
输出发送到下一个阶段(顶点着色器)的顶点流。
管理所有 GPU 事务,包括向着色器发送指令/数据,分配/取消分配资源,并为安全事务和数据压缩提供安全性。
可编程统一着色器
顶点着色器 (VS) 包括顶点变换、光照和插值,可以从简单(线性)到复杂(变形效果)。
像素/片段着色器 (PS) 计算考虑到光照、阴影和其他属性(包括纹理映射)的最终像素值。
几何着色器 (GS) 采用图元(线、点或三角形)并修改、创建(或破坏)顶点以增加对象的细节级别。GS 允许 GPU 管道访问相邻的图元,因此可以将它们作为一个紧密结合的组进行操作,以创建逼真的效果,其中相邻顶点相互交互以创建具有平滑流动运动(头发、衣服等)的效果。GS/VS/PS 组合允许更自主的 GPU 操作在内部处理状态变化(最小化 CPU-GPU 交互),方法是添加算术和动态流控制逻辑来卸载以前在 CPU 上完成的操作。另一个关键特性是 Stream Out,其中 VS/GS 可以将数据直接输出到内存,并且可以由着色器单元或任何其他 GPU 块自动重复访问数据,而无需 CPU 干预。
曲面细分着色器 (TS) 在 TS 管道中包括两个称为 Hull 和域着色器的固定功能单元。TS 采用曲面(矩形或三角形)并将它们转换为具有不同数量的多边形表示(网格/补丁),可以根据质量要求进行更改。较高的计数会创建更多的细节,而较低的计数会在对象上创建较少的细节。镶嵌单元由三部分组成:
外壳着色器 (HS) 是一种可编程着色器,它从基本输入补丁(四边形、三角形或线)生成几何(表面)补丁并计算用于操纵表面的控制点数据。HS 还计算传递给 tessellator 的自适应 tessellation 因子,因此它知道如何细分表面属性。
Tessellator 是一个固定(可配置)功能阶段,它根据来自 HS 的 tessellation 因子将补丁细分为更小的对象(三角形、线或点)。
域着色器 (DS) 是一种可编程着色器,它评估表面并为输出补丁中的每个细分点计算新的顶点位置,并将其发送到 GS 进行额外处理。
计算着色器 (CS) 将 GPGPU/GPU 计算能力添加到图形管道中,因此开发人员可以编写使用此着色器的 GLSL 应用程序代码,并且可以在正常渲染管道之外运行。数据可以在管道阶段和渲染计算上下文之间在内部共享,因此两者都可以并行执行。CS 还可以使用与 OpenGL/OpenGL ES 渲染管道相同的上下文、状态、制服、纹理、图像纹理、原子计数器等,使其更容易和更直接地编程和与渲染管道输出一起使用。
可编程光栅化器
将对象从几何形式转换为像素形式,并剔除(移除)任何背面或隐藏的表面。有许多级别的剔除机制可确保不处理隐藏像素以节省计算周期、带宽和功率。
内存接口
在将像素写入帧缓冲区之前,使用 Z 缓冲区、模板/alpha 测试删除看不见或隐藏的像素。
在此阶段执行包括 Z 和颜色缓冲区的压缩。
即时模式与延迟渲染 GPU
有两种常见的 GPU 架构和渲染图像的方法。两种方法都使用前面描述的相同的通用管道,但它们用于绘制的机制不同。一种方法称为基于 Tile 的延迟渲染 (TBDR),另一种称为即时模式渲染 (IMR)。根据各自的用例,两者都有优点和缺点。
1995 年(在智能手机/平板电脑出现之前),许多图形公司在 PC 和游戏机市场支持这两种方法。TBDR 集团拥有英特尔、微软(Talisman)、Matrox、PowerVR 和 Oak 等公司。IMR 方面有 SGI、S3、Nvidia、ATi 和 3dfx 等名称。快进到 2014 年——PC 和游戏机市场还没有使用 TBDR 架构。所有 PC 和游戏机架构,包括 PS3/PS4、Xbox 360/One 和 Wii,都是基于 IMR。
这种转变的主要原因是因为 IMR 作为对象渲染架构的内在优势,可以处理非常复杂的动态游戏(例如,快速运动、FPS 或场景或视点不断变化的帧到帧的赛车游戏) 。 此外,随着 3D 内容三角形速率的增加,TBDR 无法跟上,因为它们需要不断地将缓存内存溢出到帧缓冲内存,因为它们的架构限制。更高的三角形/多边形数量允许 GPU 渲染丝般光滑和细致(逼真)的表面,而不是出现在传统游戏中的块状曲面。通过在 IMR 中添加曲面细分着色器,三角形/多边形进一步细分的表面渲染使 3D 图形更加接近现实。
今天的移动市场密切反映了 IMR 技术正在取代 TBDR 的 PC 和游戏机市场趋势。在 TBDR 市场上,有两家公司,Imagination 和 ARM,尽管 ARM 正试图转向 IMR,因为他们看到了在移动设备上运行下一代游戏的主要优势。在 IMR 方面,有高通、Vivante、Nvidia、AMD 和英特尔。
使用 IMR 的一大好处是游戏/应用程序开发人员可以重用并轻松地将已经在复杂 GPU(或游戏控制台)上运行的现有游戏资产移植到移动设备上。由于移动设备对功率/散热和芯片面积有严格的限制,因此缩小性能差距并最大限度地减少应用程序移植或重大代码更改的最佳方法是使用与他们开发的架构类似的架构。除了获得等效的高质量 PC 质量渲染之外,IMR 还为开发人员提供了选择,所有这些都封装在比 TBDR 解决方案更小的裸片区域中。随着行业超越 OpenGL ES 3.1 和 DirectX 12 应用程序编程接口 (API),IMR 还提高了内部系统和外部内存带宽。
最后,TBDR 架构针对低三角形/多边形数量的 3D 内容和简单的用户界面进行了优化。IMR 架构在动态用户界面和详细的 3D 内容方面表现出色,可为移动设备带来与 PC 和游戏机相同的用户体验和游戏质量。
多年来的图形 API
领先的移动设备 3D API 基于 Khronos Group 的 OpenGL ES API,可在大多数当前智能手机和平板电脑中找到,适用于包括 Android、iOS 和 Windows 在内的各种操作系统。OpenGL ES 基于 OpenGL 的桌面版本,针对移动设备进行了优化,包括去除冗余和很少使用的特性以及添加移动友好的数据格式。
初始版本 OpenGL ES 1.1 基于固定功能硬件,OpenGL ES 2.0 基于可编程顶点和片段(像素)着色器,同时删除了 1.1 版的固定功能转换和片段管道。OpenGL ES 3.0 通过添加基于 OpenGL 3.3/4.x 的功能并减少对扩展的需求,从而通过对支持的功能提出更严格的要求并减少实现可变性来简化编程,从而进一步推动了行业发展。一些 GLES 3.0 功能包括遮挡查询、MRT、纹理/顶点数组、实例化、变换反馈、更多可编程性、OpenCL 互操作性、更高质量(32 位浮点数/整数)、NPOT 纹理、3D 纹理等。
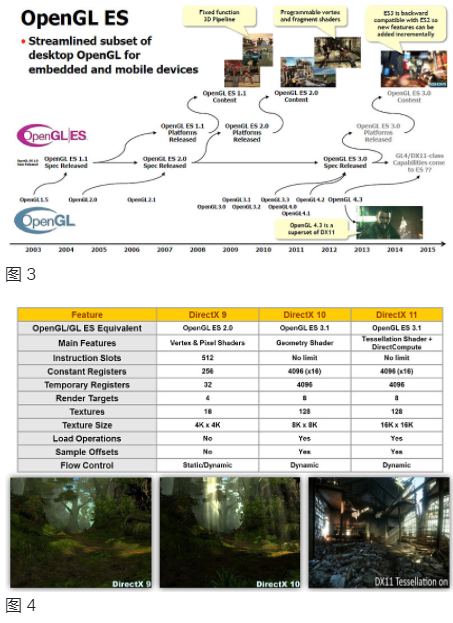
在 2014 年 3 月的游戏开发者大会上,Khronos 发布了 OpenGL ES 3.1,其中包含计算着色器 (CS)、单独的着色器对象、间接绘制命令、增强的纹理和新的 GLSL 语言添加等进步。在 OpenGL ES 3.1 发布的同时,Google 还发布了其 Android L 扩展包 (AEP),它需要移动硬件中的几何 (GS) 和曲面细分 (TS) 着色器功能,以便为 Android 平台带来先进的 3D 功能以镜像 PC 级图形。图 3 显示了 OpenGL 和 OpenGL ES 多年来的进展时间线。Microsoft 的 DirectX (DX) API 的转换和映射如图 4 所示。DX9 映射到 OpenGL ES 2.0,DX10/DX11 映射到 OpenGL ES 3.1。
GPU超越了图形
在过去的几年里,工业和大学的研究人员发现,现代 GPU 的计算资源由于其固有的并行架构而适用于某些并行计算。GPU 上显示的计算速度提升很快得到了认可,并且基于 GPU 的巨大处理能力构建的另一个 HPC 细分市场诞生了。
超越图形的 GPU 可以称为 GPU 计算核心或 GPGPU。OpenCL、HSA、OpenVX 和 Microsoft DirectCompute 等不同的行业标准已经实现,其中任务和指令并行性现在已经过优化,以利用不同的处理内核。在不久的将来,移动设备将通过卸载 CPU、DSP 或自定义内核来更好地利用系统资源,并使用 GPU 来实现最高的计算性能、计算密度、时间节省和整体系统加速。最好的方法是使用混合实现,其中 CPU 和 GPU 紧密交错以达到性能和功耗目标。
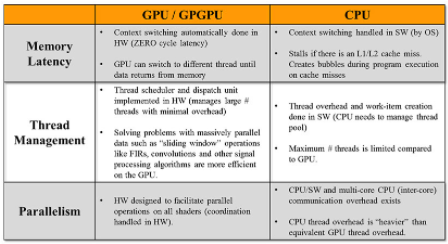
图 5 | 下表在查看内存延迟、线程管理和执行并行性等不同因素时将 CPU 与 GPU 进行了比较。
许多计算问题,如图像处理、视觉处理、分析、数学计算和其他并行算法,都很好地映射到 GPU SIMD 架构。您甚至可以对 GPU 进行编程以使用多 GPU 方法,其中计算任务和/或 3D 渲染帧在 GPU 之间拆分以提高性能和吞吐量。GPU 可以在多上下文模式下工作,以同时执行 3D 和计算线程。例如,GPU 核心 1 和 2 分配给渲染图像,核心 3 和 4 专用于 GPGPU 功能,如粒子效果(烟/水/火)、模拟真实世界运动的游戏物理或自然用户界面(NUI ) 处理手势支持。采用 GPGPU 的其他市场,尤其是在嵌入式/计算机视觉领域,包括:
增强现实:使用 GPU 生成的数据(图像、数据、3D 渲染等)覆盖现实世界环境,这些数据可以从各种传感器(如 Google Glass)输入。AR 可以处理在线(实时和直接)或离线内容流。
特征提取:对许多视觉算法至关重要,因为需要创建图像“兴趣点”和描述符,以便 GPU 知道要处理什么。SURF(加速鲁棒特征)和 SIFT 是可以在 GPU 上有效并行化的算法示例。物体识别和符号识别是这种应用的形式。
点云处理:包括特征提取以创建 3D 图像,以检测杂乱图像中的形状和分割对象。用途可能包括将增强现实添加到街景地图中。
高级驾驶辅助系统 (ADAS):不断实时计算多种安全功能,包括线路检测/车道辅助(Hough 变换、Sobel/Canny 算法)、行人检测(定向梯度直方图或 HOGS)、图像去扭曲、盲点检测等。
安全与监控:包括通过人脸地标定位(Haar 特征分类器)、人脸特征提取和分类以及对象识别的人脸识别。
运动处理:自然的用户界面,如手势识别,将手与背景分离(如颜色空间转换为 HSV 颜色空间),然后对手进行结构分析以处理运动。
视频处理:使用着色器程序和高速整数/浮点计算的 HEVC 视频协同处理。
图像处理:将 GPGPU 与图像信号处理器 (ISP) 相结合,以实现流线型的图像处理管道。
传感器融合:将视觉处理与其他传感器数据(如激光雷达)相结合,以创建具有深度的 3D 空间地图。图形中使用的一个类似概念是光线追踪,您可以射出一条光线并在图像中追踪其路径,并计算所有光线与对象的交点和反弹以生成逼真的 3D 图像。
消费者和行业正在推动移动领域的前沿技术向前发展。因此,GPU 供应商必须不断创新并跟上最新趋势、API 和用例,同时最大限度地提高性能并最大限度地减少高级图形和计算功能的功耗和芯片面积增量。移动 GPU 设计必须从算法层面进行架构设计,并经过深思熟虑,以实现业界最小的集成设计和硬件占用空间。直接取自 PC GPU 的设计无法有效地按比例缩小以实现移动电源效率。秘诀在于配置引擎盖下的内容,以使移动应用程序点击,而不限制功能、稳健性或所需的性能。
审核编辑:郭婷
-
传感器
+关注
关注
2578文章
55835浏览量
795538 -
处理器
+关注
关注
68文章
20381浏览量
255640 -
gpu
+关注
关注
28文章
5324浏览量
136219
发布评论请先 登录
深入解析ADV7802:高性能视频解码与图形数字化芯片
ADV7842:高性能HDMI接收器与图形数字化器的卓越之选
深入解析ADV7604:高性能视频与图形数字化器
ADSP - 21369 SHARC处理器:高性能音频处理的理想之选
ADSP1802 SHARC处理器:高性能音频处理的理想之选
ADP5043:高性能微电源管理单元的全面解析
ADP5042:高性能微电源管理单元的深度解析
【VPX610】基于6U VPX总线架构的高性能实时信号处理平台

深入解析 TVP7002:高性能视频与图形数字化器
TVP70025I:高性能视频与图形数字化器的全面解析
探索THS8136:一款高性能的图形与视频DAC
提高RISC-V在Drystone测试中得分的方法
全志A733:高性能八核AI处理器,智能终端优选
STM32N6高性能微控制器技术解析:AI与图形处理的融合创新

负载减少50%!Arm用AI重新定义移动端图形渲染



评论