 如何基于Kahn处理网络定义AI引擎图形编程模型
如何基于Kahn处理网络定义AI引擎图形编程模型

本白皮书探讨了如何基于 Kahn 处理网络( KPN )定义 AI 引擎图形编程模型。KPN 模型有助于实现数据流并行化,进而提高系统的整体性能。AI 引擎阵列编程需要深入了解待实现的算法、AI 引擎的功能以及各个功能单元之间的整体数据流。AI 引擎内核是在 AI 引擎上运行的功能,并构成了数据流图规范的基本构建块。数据流图是具有确定性行为的 KPN。本白皮书还包括一个示例设计,展示了具有四个 AI 引擎内核的数据流图,而这些内核构成了数据流图规范的基本构建块。此外,该示例还演示了设计中的数据流停滞,并提供了解决方案。
KPN 被广泛用作分布式编程模型,能够在各种可能的情况下并行运行任务。本白皮书介绍了 AI引擎如何使用 KPN 模型进行图形编程。基于不同的目标架构,如中央处理器( CPU )、图形处理单元( GPU )、FPGA、AI 引擎编程等,计算模型的种类也多种多样。下图显示了按照序列模型、并发模型和功能模型分类的计算模型。
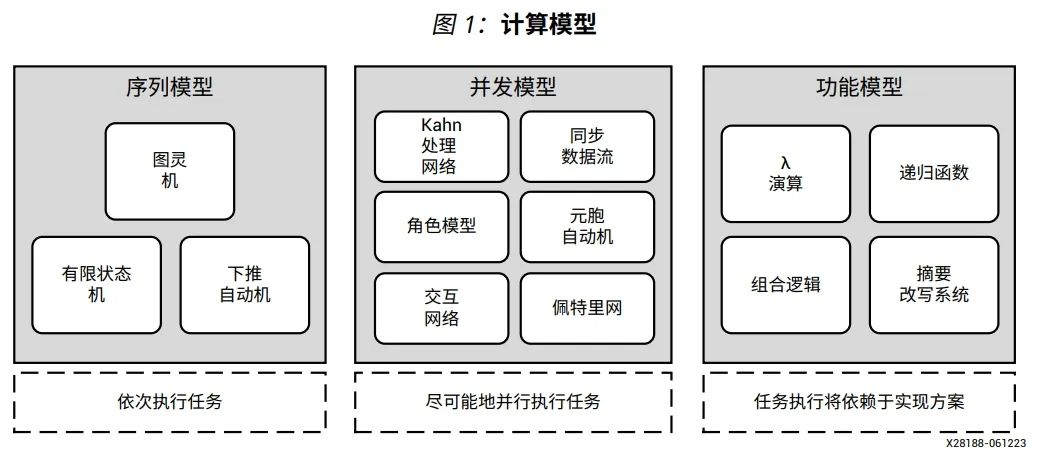
在序列模型中,任务是一个接一个地或按顺序执行。在并发模型中,任务是尽可能地并行执行。在功能模型中,任务执行依赖于实现方案,例如针对特定的架构(如 GPU 或 FPGA 中的可编程逻辑)。本白皮书重点探讨 AI 引擎编程的计算模型。该模型可用于指导程序员编写针对 AI 引擎架构的程序,其目标是通过了解其编程模型来充分发挥 AI 引擎的算力。随着计算任务的复杂性日益增加,实践证明,标准处理器已不足以有效地执行这些任务。为了应对这种情况,CPU、GPU 以及专用处理器等各种计算架构经过演进发展,已经能够解决这个不足之处。
Kahn 处理网络
KPN 是由 Gilles Kahn 在 1974 年提出的一种分布式计算模型,其作为针对并行编程开发的通用方案,为数据流模型奠定了重要基础。在 KPN 中,组件表示函数(或内核),连接表示数据流,如下图所示。
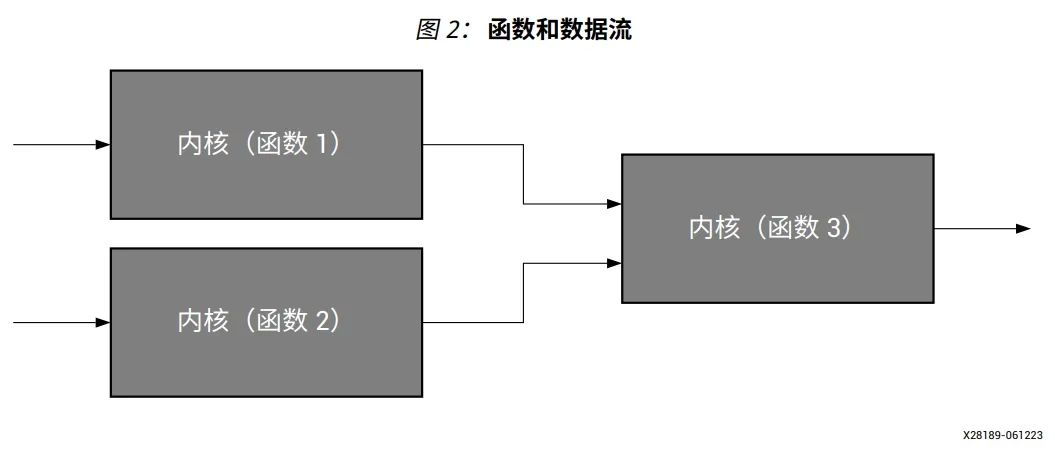
内核(函数 3 )从其它两个内核(函数 1 和函数 2 )读取数据。如果其中的任何一个内核都没有可用的数据,那么读取会停止该进程,从而阻塞内核(函数 3 )。只有当足够多的数据(令牌)可用时,该进程才能继续。将数据(函数 1 和函数 2 )写入进程(函数 3 )是非阻塞的,这意味着写入进程总是成功的,并且不会出现停滞。由于这些特点,数据流网络在本质上是具有确定性的。这是通过先进先出( FIFO )通道进行的确定性进程通信。经过验证,该模型可用于嵌入式系统、信号处理系统、高性能计算、数据流编程语言和其它计算任务的建模。
信号处理系统使用 KPN 进行建模,其中通过以顺序或并行执行形式(基于给定任务)来处理无限数据流。
AI 引擎——自适应数据流编程
本节介绍了数据流编程如何适用于 AI 引擎。节点(或角色)表示某种类型的操作。节点或内核在 AI 引擎中实现,其可执行操作,但并不严格地作为单个运算符,如图 8:数据流 编程中所示。AI 引擎可以包含许多能够执行多种操作的内核。
KPN 边缘表示数据往返于角色或端口的路径。边缘被实现为 I/O 流、级联 I/O 流、流或直接内存访问( DMA )FIFO,以及 AI 引擎块架构中的本地块内存缓冲区。
在 AI 引擎设计中,KPN 节点( AI 引擎内核)之间的连接通过 C++ 自适应数据流( ADF )图程序来实现。这段代码可建立 KPN 节点( AI 引擎内核)之间的数据流图连接,并确定这些节点所需的任何大内存缓冲区以及该图形的任何 I/O。
执行计划由该图形以及输入数据和输出资源的可用性决定:
没有指令指针来触发 AI 引擎。只要所有输入数据可用,每个块都会触发并执行其内核函数,就像在 KPN 中一样。
基于器件,AI 引擎提供众多可用的执行单元(按 10 或 100 为单位)。根据数据流图中的互联特性,这些引擎的执行方式可能包括部分、无、或者全部并行执行。
所有 AI 引擎都在计算或等待输入数据,就像在 KPN 中一样。
AI 引擎编译器接受输入(数据流图和内核),并生成用于在 AI 引擎器件上运行的可执行应用。AI 引擎编译器对锁定、内存缓冲区、DMA 通道和描述符等必要资源进行分配,并生成用于将图形映射到 AI 引擎阵列的路由信息。它为每个核综合一个主程序,用于调度该核上的所有内核,并在缓冲区之间实现必要的锁定机制和数据复制。
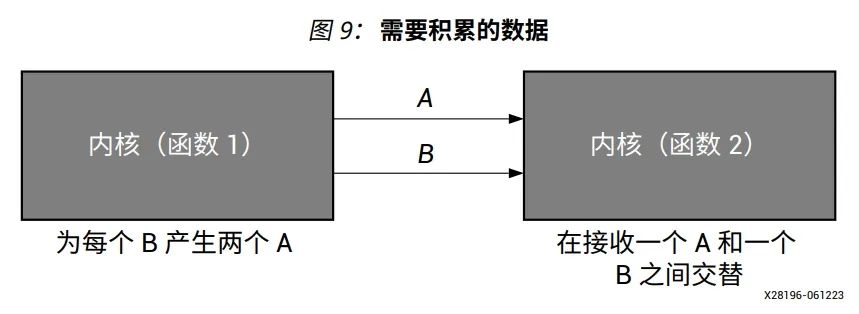
如下图所示,函数 1 的作用是为每个 B 产生两个 A。平均而言,函数 2 消耗的 A 是其消耗的 B 的两倍。它可能并不总是 A 和 B,可能在一段时间内是 A,在另一段时间内是 B。为了处理这种情况,需要积累数据/令牌以便以后处理。在某些情况下,如果积累的周期较长,则可能导致系统停滞并影响性能。具体难度根据设计要求而异。克服这些挑战的方法包括通过添加 FIFO 来积累数据,通过使用多个 AI 引擎和其它优化技术的方式对内核进行编程,以提高性能。了解死锁问题并使用适当的技术来解决它至关重要。
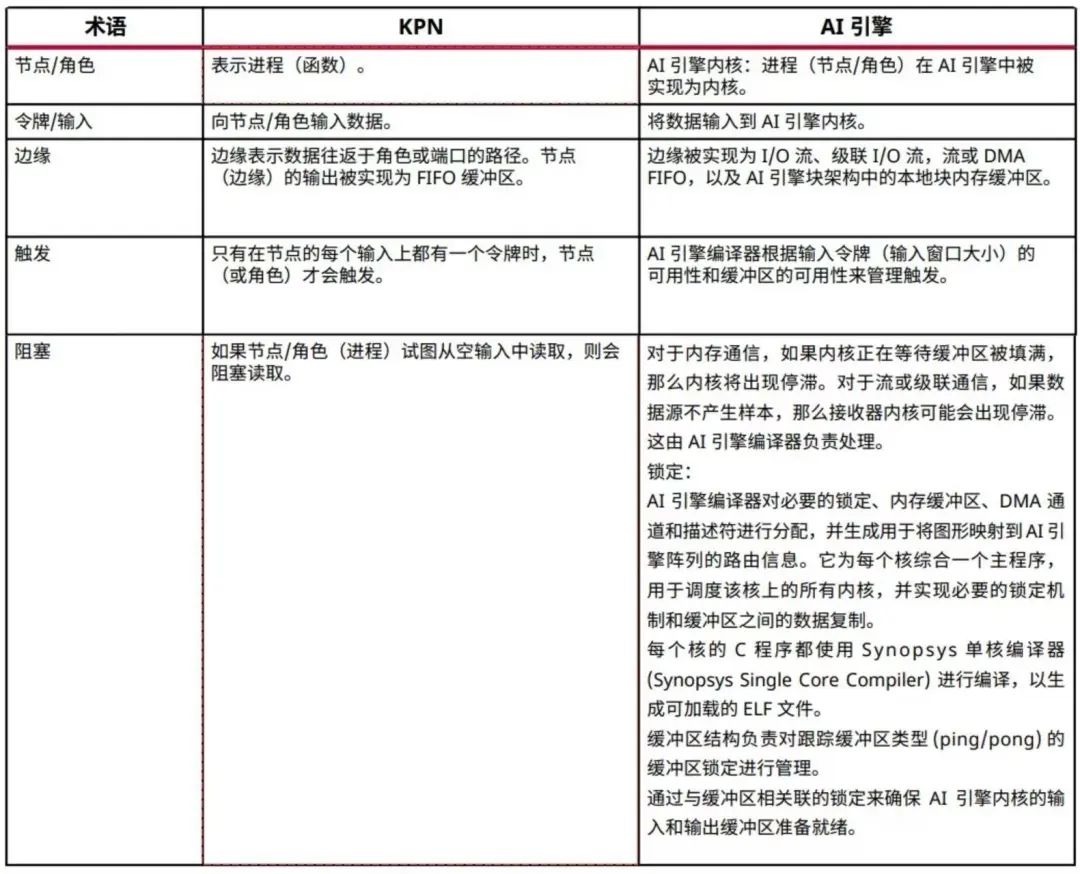
下表列出了 KPN 和 AI 引擎术语之间的比较
表 1:KPN 和 AI 引擎术语
在某些情况下,对于特定算法而言,数据流编程具有一定挑战性,因为调度可能会导致进程停滞。
-
处理器
+关注
关注
68文章
20345浏览量
255384 -
gpu
+关注
关注
28文章
5292浏览量
136115 -
AI
+关注
关注
91文章
41449浏览量
302781 -
模型
+关注
关注
1文章
3840浏览量
52293 -
图形编程
+关注
关注
1文章
7浏览量
8632
原文标题:白皮书|AI 引擎编程:Kahn 处理网络的演进发展
文章出处:【微信号:赛灵思,微信公众号:Xilinx赛灵思官微】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
赛灵思分享:智能引擎中所的AI引擎技术分析
信而泰×DeepSeek:AI推理引擎驱动网络智能诊断迈向 “自愈”时代
Microwindows图形编程机制
Firefly支持AI引擎Tengine,性能提升,轻松搭建AI计算框架
Qualcomm最新推出的神经处理引擎
嵌入式AI在linux芯片平台上的部署方案分享
嵌入式边缘AI应用开发指南
HarmonyOS:使用MindSpore Lite引擎进行模型推理
嵌入式Linux平台部署AI神经网络模型Inference的方案

Imagination 宣布推出 E-Series GPU:开启Edge AI 与图形处理新时代




评论