 英特尔针对7纳米工艺节点做出哪些关键改进?
英特尔针对7纳米工艺节点做出哪些关键改进?

据称,该GPU计划是迄今为止最大,设计最多的芯片:将具有1000个执行单元(EU),内核数量超过8000个,采用了7种关键技术,包含47个Tile,是有史以来尺寸最大、最复杂的GPU。
英特尔新GPU:Foveros 3D封装不同代工厂Tile
英特尔的Ponte Vecchio GPU集成了超过1000亿个晶体管,47颗XPU Tile以及各种制程节点的混搭。这款GPU采用了Xe-HPC图形架构,该架构是基于英特尔7nm EUV节点的旗舰产品。
除此之外,该芯片还有大量基于不同工艺节点的Tile,其中一些Xe-HPC Tile由台积电等外部晶圆代工厂生产。
目前,尚无法确定英特尔是否会采用台积电的7nm或7nm+ EUV工艺节点,但是鉴于台积电代工的Xe Link I/O Tile采用了标准的非EUV 7nm工艺,英特尔可能会继续采用标准7nm工艺。
英特尔首席架构师Raja Koduri曾经说Ponte Vecchio GPU采用了7项先进技术,技术媒体Wccftech给出了具体名单:
英特尔7nm工艺、台积电7nm工艺、Foveros 3D封装、EMIB(嵌入式多芯片互连桥接)技术、英特尔增强型10nm SuperFin工艺、Rambo Cache(兰博缓存)与HBM2显存。
Raja Koduri也在推特上公布了47颗Tile分别是什么:16颗Xe HPC(internal/external)、8颗Rambo(internal、2颗Xe Base(internal)、11颗EMIB(internal)、2颗Xe Link(external)和8颗HBM(external)。
Ponte Vecchio实际上由两个独立GPU芯片组成,每个GPU包含六个Xe-HPC计算单元。
一对Xe-HPC计算单元直接与兰博缓存相连,兰博缓存采用了英特尔增强型10nm SuperFin工艺。
每个GPU还连接了四个HBM2显存,HBM2采用4Hi或8Hi堆叠(可以简单理解为4层或8层)。一共八个HBM2可以提供多GB的内存容量和带宽负载。此外,每个GPU上还有8个Passive Die Stiffeners。
总体来说,英特尔Xe HPC这款MCM结构GPU处理器使用了最先进的Foveros 3D封装技术,将多个来自不同代工厂,使用不同工艺制作的Tile集成在一个平台上,EMIB技术则将HBM2、Xe Link I/O等Tile与GPU互连。
所有这些整合形成了Ponte Vecchio Xe-HPC GPU。
执行单元数量将超1000,提供40倍双精度浮点算术能力
英特尔此前曾介绍过,其Xe-HPC GPU将具有1000个执行单元(EU)。到目前为止,Xe LP有96个EU,它们构成了总共768个内核。
新GPU的每个子层(subslice)有8个EU。第12代GPU中的subslice类似于英伟达SM单元或AMD的CU单元。
而在英特尔的9.5和11代GPU上,每个subslice具有8个EU,因此如果12代保持相同的层次结构,人们将能看到大量由subslice组成的超级切片。从目前的图片上看,英特尔第12代GPU将有8个算术逻辑单元(ALU),与11代和9.5代保持一致。
大致来说,一个GPU芯片将有1000个EU单元,8000个内核,而实际内核数量还要更多。而Xe HP GPU的HPC尺寸也将更大。
Wccftech列出了英特尔GPU的实际EU单元、对内核数量的估计。功率和TFLOPS(每秒浮点运算次数)等数据:
英特尔Xe HP (12.5) 2-Tile GPU: 1024个EU单元,8192个内核,20.48 TFLOPS,1.25 GHz,300W;
英特尔Xe HP (12.5) 4-Tile GPU: 2048个EU单元,16384个内核,36 TFLOPS,1.1 GHz,400W-500W。
英特尔Xe类GPU具有下面几种可变矢量宽度(vector width):SIMT(GPU)、SIMD(CPU)、SIMT+SIMD(最高性能)。
Raja Koduri谈到,英特尔的Xe HPC GPU能够扩展到1000个EU,EU通过几个高带宽内存通道与XE内存结构相连,并且每个EU单元都进行了升级,可以提供40倍的双精度浮点计算能力。
兰博缓存则将在整个双精度工作负载中提供可持续的FP64计算性能。
就工艺优化而言,以下是英特尔针对7纳米工艺节点的一些关键改进:
1、相较10nm节点具有两倍的密度缩放优势;
2、内部的节点优化;
3、DR(Design Rules)的4倍缩减;
4、采用了EUV光刻技术;
5、新一代Foveros和EMIB封装。
责任编辑:pj
-
芯片
+关注
关注
463文章
54423浏览量
469302 -
英特尔
+关注
关注
61文章
10321浏览量
181084 -
晶圆
+关注
关注
53文章
5449浏览量
132758 -
gpu
+关注
关注
28文章
5271浏览量
136069
发布评论请先 登录
英特尔炮轰,AMD回击!掌机市场芯片之争
超越台积电?英特尔首个18A工艺芯片迈向大规模量产

英特尔计划裁员21000人,可能跳过18A工艺
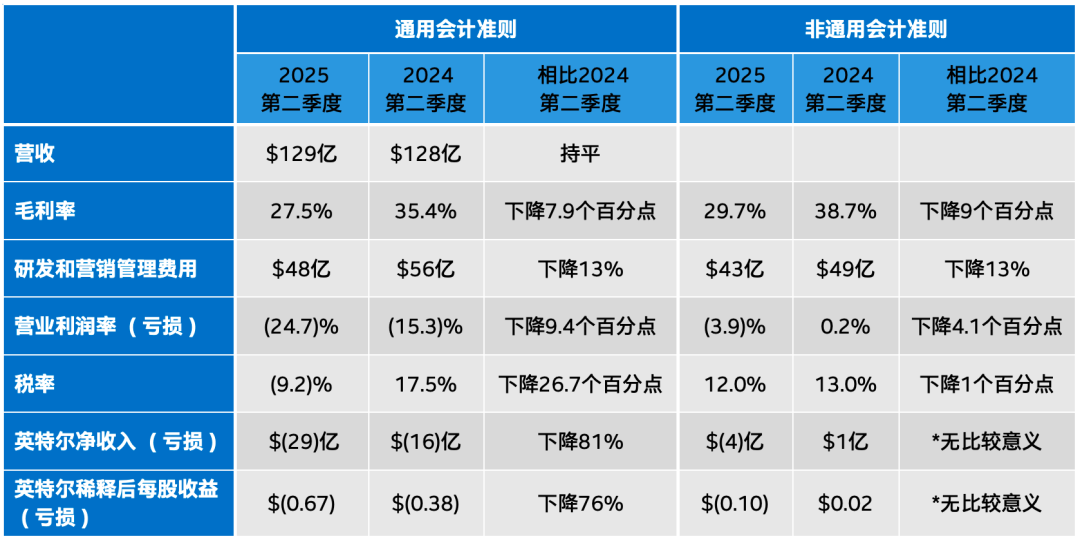
让英特尔再次伟大,新CEO推动18A提前量产,14A已在路上

释放极致游戏性能!英特尔酷睿Ultra 200S Plus发布
18A工艺首发!英特尔推出下一代PC处理器,77%游戏性能暴涨+180TOPS算力

英特尔举办行业解决方案大会,共同打造机器人“芯”动脉

18A工艺大单!英特尔将代工微软AI芯片Maia 2
美国政府将入股英特尔?
使用英特尔® NPU 插件C++运行应用程序时出现错误:“std::Runtime_error at memory location”怎么解决?
英特尔锐炫Pro B系列,边缘AI的“智能引擎”

英特尔先进封装,新突破
新思科技与英特尔在EDA和IP领域展开深度合作
英特尔发布全新GPU,AI和工作站迎来新选择
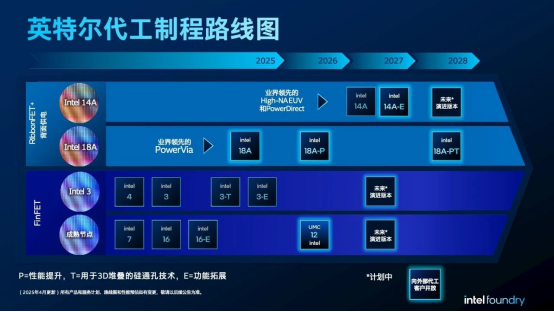
英特尔持续推进核心制程和先进封装技术创新,分享最新进展



评论