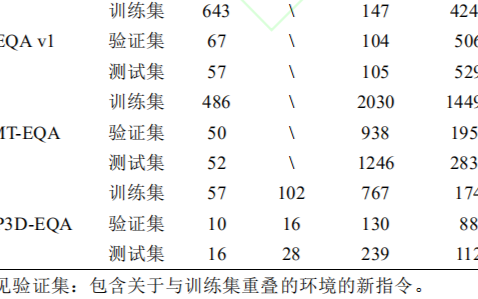


一些NER的英文数据集推荐
1 MUC Data Sets https://www-nlpir.nist.gov/relat....
自动跨主题作文属性评分研究
01 — 研究动机 自动作文评分(英文叫Automated Essay Scoring,简称AES)....
最常见的4个神经网络错误是什么?
点击上方,选择星标或置顶,每天给你送干货 ! 阅读大概需要5分钟 跟随小博主,每天进步一丢丢 作者丨....
如何让PyTorch模型训练变得飞快?
让我们面对现实吧,你的模型可能还停留在石器时代。我敢打赌你仍然使用32位精度或GASP甚至只在一个G....
为什么半监督学习是机器学习的未来?
为什么半监督学习是机器学习的未来。 监督学习是人工智能领域的第一种学习类型。从它的概念开始,无数的算....
NLP到底该怎么搞?
CMU、华盛顿大学、南加州大学、MIT、MILA、密歇根大学、爱丁堡大学、DeepMind、伯克利、....
图解BERT预训练模型!
BERT的发布是这个领域发展的最新的里程碑之一,这个事件标志着NLP 新时代的开始。BERT模型打破....
尝试用QA的形式深入不浅出BERT/Transformer的细节知识点
那在 softmax 后的加权平均中,该词本身所占的比重将会是最大的,使得其他词的比重很少,无法有效....
基于主动学习的半监督图神经网络模型来对分子性质进行预测方法
总体来讲,本文使用教师模型和学生模型来迭代训练。每个模型都是一个图神经网络。在教师模型中,使用半监督....
Hinton的那篇Capsule论文终于揭下了神秘的面纱
而当前的深度学习理论,自从Hinton大神在2007年(先以受限玻尔兹曼机进行训练、再用有监督的反向....
NLP中的自监督表示学习
在这个公式中,我们取三个连续的句子,设计一个任务,其中给定中心句,我们需要生成前一个句子和下一个句子....
微软亚洲研究院的研究员们提出了一种模型压缩的新思路
近日,来自微软亚洲研究院自然语言计算组的研究员们提出了一种与显式地利用蒸馏损失函数来最小化教师模型与....
如何去掉batch normalization层来加速神经网络
一旦训练结束,每个Batch normalization层都拥有一组特定的γ和β,还有μ和σ,后者在....
小米在行业图谱上的探索
小米知识图谱在中台体系下不断的成长,2017年小米知识图谱有了一些开放知识的积累, 2018年知识图....
GNN教程:GraghSAGE算法细节详解!
这一节讨论的是如何给图中的节点生成(或者说更新)embedding, 假设我们已经完成了GraphS....
常见的最优化方法介绍
从上面公式可以注意到,它得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果m很大....
中国会在2020年论文数超过美国,没想到我们提前完成了
这一数据折射出来的,是科技评价体系的问题。施一公称, 在各个单位,不论是晋升还是考量绩效,都会把专利....
深度学习:搜索和推荐中的深度匹配问题
本文主要启发来源SIGIR2018的这篇综述性slides《Deep Learning for Ma....
基于多视图协作学习的人岗匹配研究论文提要
近日,第29届国际计算机学会信息与知识管理大会(CIKM 2020)在线上召开,CIKM是CCF推荐....
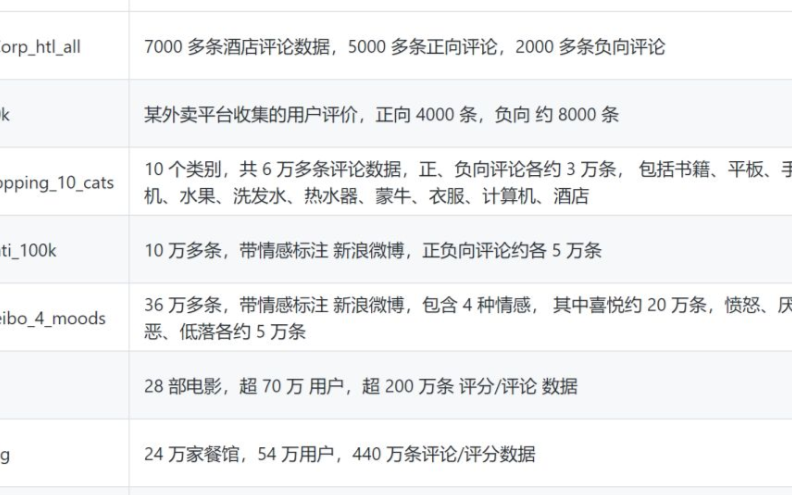
知识图谱:基于实体的层次化概念体系的属性自动获取方法
摘要:属性是实体的重要组成部分,因此如何自动获取实体的属性一直为知识图谱领域的研究者所关注。由哈尔滨....
CV学习中的ROI与泛洪填充
一:ROI ROI(region of interest),中文翻译过来就是感兴趣区域,在机器视觉、....
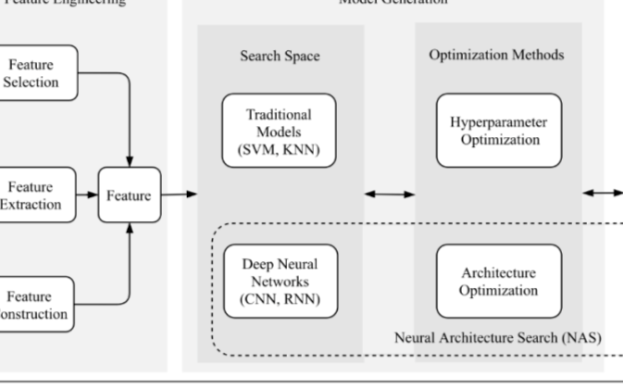
关于Pre-trained模型加速模型学习的建议
首先,为什么要调整模型? 像卷积神经网络( CNN )这样的深度学习模型具有大量的参数;一般称之为超....
腾讯自然语言处理面试问题
师兄在腾讯,就让师兄内推了一下腾讯自然语言处理的实习。在内推前,简单把李航的统计学习方法,简历涉及的....


