 字符感知预训练模型CharBERT
字符感知预训练模型CharBERT

本期推送介绍了哈工大讯飞联合实验室在自然语言处理重要国际会议COLING 2020上发表的工作,提出了一种字符感知预训练模型CharBERT,在多个自然语言处理任务中取得显著性能提升,并且大幅度提高了模型的鲁棒性。本文以高分被COLING 2020录用,且获得审稿人的最佳论文奖推荐(Recommendation for Best Paper Award)。
简介
目前预训练语言模型在NLP领域的大部分任务上都得到了显著的效果提升,其中绝大部分模型都是基于subword的子词粒度构建表示,这样几乎可以避免OOV(out-of-vocab)的产生。但这种基于子词粒度的表示也存在两个问题:1)不完整,只能构建子词粒度的表示,而丧失了全词及字符的信息;2)不鲁棒,字符上一个小的变化就会导致整个切词组合的变化。我们可以通过下面一个示例来说明这两个问题。

图1 单词backhand内部结构示例
一个单词的内部结构可以表示成三层的树:根节点-全词;孩子节点-子词;叶子节点-字符。以BPE(Byte-Pair Encoding)[1]为代表的子词粒度表示方法只可以表示孩子节点的信息,而丧失了根和叶子节点的信息。如果字符序列出现了噪音或者拼写错误(如去掉了字符k),那么整个子词组合就会完全变化,输入到模型中的表示也就完全不一样了,因此鲁棒性较差。以CoNLL-2003 NER的开发集为例,我们基于BERT[2]的tokenizer切词后统计发现28%的名词会被切分成多个子词。如果随机删除所有名词中的任意一个字符,78%的词会切分成如图1这样完全不一样的组合。由此可以看出,不完整与不鲁棒问题是具有统计显著性的问题。
继续看图1中的示例。如果我们仔细观察字符信息对应的叶子节点,可以发现在去掉字符k后,叶子节点只有一个节点发生了变化,信息的变化量从孩子节点的100%降低为12.5%。另外,我们也可以通过字符信息构建出全词级别的表示,从而将词的各级信息完整地表示出来。因此,我们将在目前预训练模型的架构上,融合字符信息来解决上述两个问题。
基于预训练模型的字符融合具有两个挑战:1)如何建模字符序列;2)如何融合字符与原有基于subword的计算。我们在方法上主要解决了这两个问题,其主要贡献如下:
我们提出了一种字符感知预训练模型CharBERT,可以在已有预训练模型的基础上融合字符层级的信息;
我们在问答、文本分类和序列标注三类任务的8个数据集上进行了验证,发现CharBERT可以在BERT和RoBERTa[3]两个基线上有明显的效果提升;
我们通过字符攻击的方式构造了这三类任务对应的噪音测试集合,发现CharBERT可以大幅度提升模型的鲁棒性。
模型与方法
主要架构
因为要同时融合预训练模型原有的subword粒度计算和基于字符的计算,我们整体上采用的双通道的架构,具体如下图2所示。其中我们设计了两大模块:字符编码器Character Encoder和交互融合模块Heterogeneous Interaction来解决上述字符融合的两个问题。其中Character Encoder基于Bi-GRU构造了上下文的字符表示,Heterogeneous Interaction通过融合和分拆两步计算进行两个信息流的交互式融合。
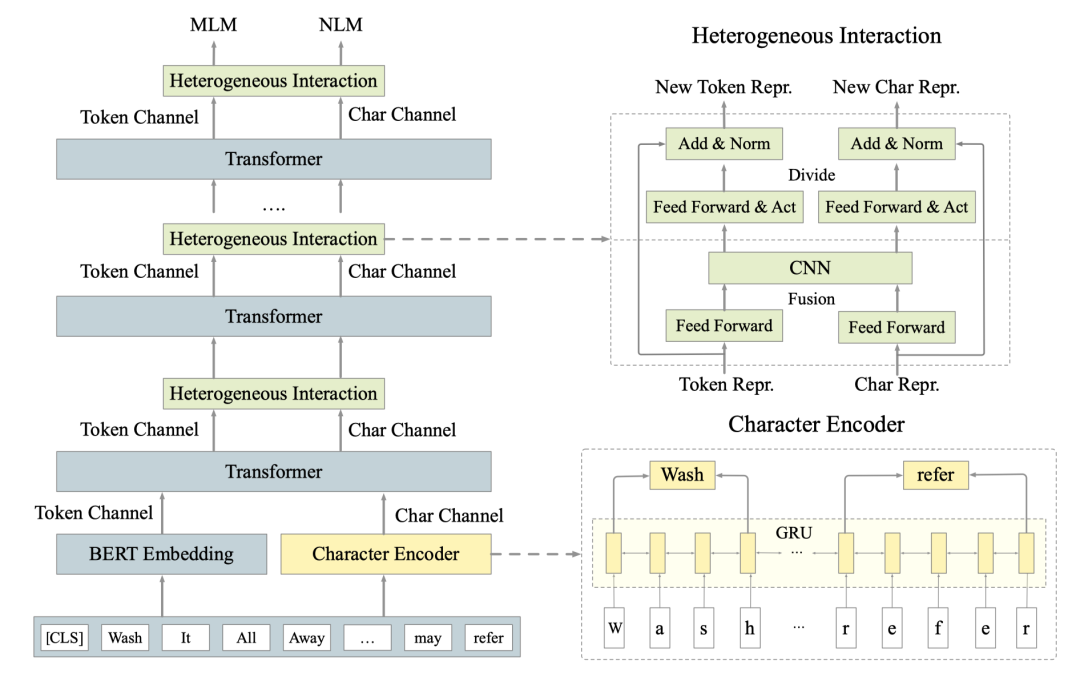
图2 CharBERT模型图
Character Encoder的输入是字符序列,输出与BERT Embedding具有相同shape的字符表示。Heterogeneous Interaction在每个transformer之后进行两个信息流的融合计算,因此其输入和输出具有相同的shape。
Character Encoder
字符编码器的结构如图3所示,主要基于Bi-GRU构建上下文的字符表示。
图3 Character Encoder示意图
我们将整个输入序列看成字符序列,词之间使用一个空字符隔开。将每个字符映射成一个固定大小的embedding后,使用Bi-GRU构建每一个字符的表示,然后将每个词的首尾字符的表示拼接作为每个词对应的表示,对应公式如下:
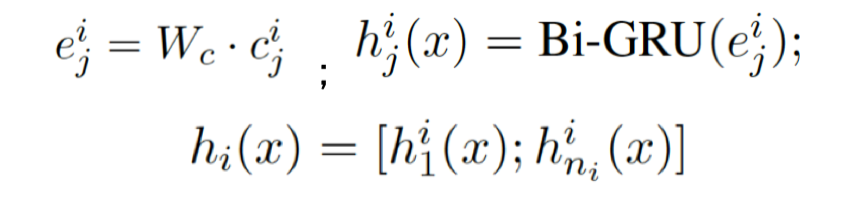
其中ni表示第i个词的长度,h表示通过字符信息构建的词向量。基于Bi-GRU的字符表示,在每个词的首尾字符位置是带上下文信息的,所以将其拼接作为词的表示。
Heterogeneous Interaction
由于来自原始预训练模型的表示和来源于character encoder基于字符的表示是异构的,很难通过简单操作将二者融合起来。因此我们设计了交互式的融合模块Heterogeneous Interaction, 在每一个transformer层计算后进行迭代式融合,其结构如图4所示。
图4 异构交互模块示意图
该模块主要包含两步:融合和分拆。在融合过程中,先对各自表示进行转换后,使用CNN抓取局部特征将两个来源的信息融合到一起:
在分拆过程中,各自进行新的转换然后基于残差构造各自不同的表示:
融合的目的是让两个来源的信息相互补充,分拆是为了各自保持住自己独有的特征,也为后面不同的预训练任务做准备。
无监督字符预训练
为了让模型更好地学习词内部的字符特征,我们设计了一种无监督的字符预训练任务NLM(Noisy LM)。通过字符的增删改自动构造一定比例的字符噪音,再通过NLM任务进行原始序列还原,具体计算如图5所示。
图5 NLM预训练任务示例
需要注意的是,因为在引入字符噪音之后,每个词对应的切词组合会变化,因此我们在NLM任务中预测粒度是全词而不是子词,在预训练过程中我们需要额外构造一个全词词表,而该词表在fine-tuning阶段是不需要的。另外,对于原始预训练模型计算的分支,我们在预训练阶段仍然保持做MLM(Masked LM)任务,该任务预测的词与NLM任务不交叉,在该部分处理和预测的词是不带噪音的。
下游任务精调
NLP中绝大部分分类任务可以分成两类:token-level分类(如序列标注)和sequence-level分类(如文本分类)。对于token-level的分类,我们将CharBERT两个分支的表示拼接进行预测。对于sequence-level的分类,目前大部分预训练模型使用‘[CLS]’位做预测。因为该位置不带有有效的字符序列,所以我们将两个分支的表示拼接后取平均再做分类。
实验
实验设置
为了保持对比的公平性,我们不引入额外数据,仅使用英文维基百科数据(12G,2500M words)进行预训练。由于算力有限,我们只基于BERT和RoBERTa的base模型进行实验,额外增加的模块共占用5M的参数量。预训练过程进行了320K步迭代,使用两张32GB显存的NVIDIA Tesla V100的GPU训练5天左右。我们将MLM中mask的比例从BERT的15%调低到10%,而NLM中将序列中15%的词使用随机增删改的方式引入噪音。
通用评估
我们在问答、文本分类和序列标注三类任务中做模型通用效果的评估。其中问答方面我们基于SQuAD 1.1和2.0两个版本的阅读理解数据集,文本分类基于CoLA、MRPC、QQP和QNLI四个单句和句对分类数据集,序列标注方面基于CoNLL-2003 NER和Penn Treebank POS分类数据集。主要结果如下表1和表2所示。
表1阅读理解、文本分类结果
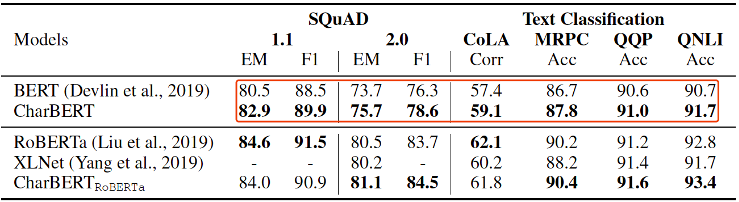
表2命名实体识别、词性标注结果
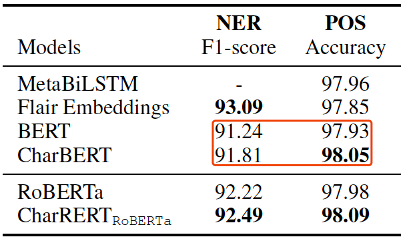
在通用效果的评估上,我们基于BERT的提升比较显著,但是在RoBERTa的基线上由于baseline的增高,提升比较微弱。另外,在各个任务的提升幅度上,大致上是序列标注>阅读理解>文本分类,可能是因为字符信息在序列标注任务上更为重要。
鲁棒性评估
我们基于上述三类任务进行了鲁棒性评估。在该部分评估集的构建上,我们主要按照之前的工作[4]通过四种方式进行字符层级的攻击:dropping, adding, swapping和keyboard。与之前工作不同的是,我们同时考虑问答、文本分类和序列标注三类任务,而不仅仅是某一类任务上的鲁棒性,整体鲁棒性对比结果如下表3所示。
表3鲁棒性测试
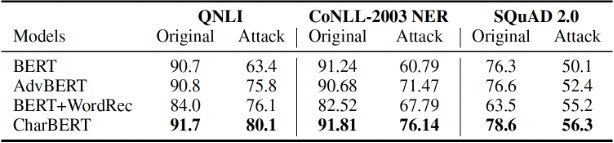
其中AdvBERT是我们基于BERT进行与CharBERT同样数据和超参的预训练,BERT+WordRec是之前工作[4]在BERT之前增加了一个词纠正器,Original是原始测试集,Attack是攻击集合。我们可以看到BERT在攻击集合上效果下降很大,说明BERT的表示在字符攻击上确实不鲁棒。CharBERT在保持原有集合效果提升的前提下,大幅度提升了BERT的鲁棒性。以其中QNLI的数据进行具体对比,我们可以发现各模型效果变化如下。
图6QNLI上不同模型的鲁棒性对比
我们可以看到BERT效果下降幅度超过30%,另外两个baseline模型效果降幅明显缩小,而CharBERT下降幅度为12%,显著超过了所有模型。
分析
为了进一步探究文首所提出的预训练模型不完整和不鲁棒的问题,我们基于CoNLL-2003 NER数据的测试集做了进一步分析。
Word vs. Subword
针对不完整性问题,我们将测试集中所有的词按照是否会被BERT tokenizer切分成多个子词分成‘Word’和‘Subword’两个子集合,前者不会被切分(如‘apple’)而后者会被切分成多个子词(如‘backhand’)。实际上,‘Subword’部分只包含了所有词的17.8%但是包含了所有实体的45.3%。CharBERT和BERT在整体与两个子集合中的效果如下图7所示。
图7CoNLL-2003 NER上性能表现对比
首先,对比同一个模型在不同集合上的表现,我们发现‘Word’集合上的效果都要远高于‘Subword’集合,这说明切分成多个词确实对模型效果有直接影响,子词粒度的表示应该客观上存在不充分的问题。对比同一个集合下不同模型的表现,我们发现CharBERT在‘Word’集合上的提升是0.29%,而在‘Subword’集合上的提升是0.68%,这说明主要的提升来源于‘Subword’集合,也就是说我们通过融入字符信息,可以有效提升切分成多个子词部分的效果,缓解了表示上的不完整问题。
鲁棒性分析
针对预训练模型的鲁棒性问题,我们探究预训练的表示在字符噪音下的变化。我们定义了一个敏感性指标分析模型输出的词向量在噪音下的变化量,从而分析模型对噪音的敏感程度,其具体计算如下:
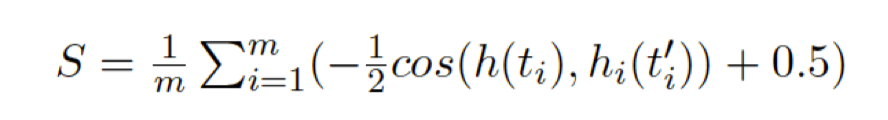
其中m是集合中词的总数,模型敏感性S本质上是模型在整个集合所有序列输出的表示在引入噪音后的cosine距离均值,如果一个模型对噪音完全不敏感,那么前后表示不变,S=0。对应到具体一个序列,我们也可以对每一个词计算引入噪音后的表示变化,如图8所示。
图8CoNLL-2003 NER敏感度测试
我们发现对于没有引入噪音的词如‘I’、‘it’三个模型输出表示的变化量区别不大。而对于引入字符噪音的词如‘think-thnik’、’fair-far’,CharBERT的变化量要远远大于BERT,而经过噪音数据进行训练的AdvBERT则明显低于BERT。在整个集合统计上也具有相同趋势:S(BERT)=0.0612,S(AdvBERT)=0.0407,S(CharBERT)=0.0986。说明CharBERT通过NLM的预训练对噪音部分采用了不同方式的表示,与常规使用噪音数据来提升模型鲁棒性方式有些不同。直观上,我们一般认为越不敏感的模型鲁棒性越好,但是CharBERT通过对噪音部分不同的建模,在表示变得敏感的同时也提升了鲁棒性,这将启发我们后续提升模型鲁棒性的路径也可以有多种方向。
总结
本文主要基于目前预训练模型表示粒度上不完整和不鲁棒的两个问题,提出了字符感知预训练模型CharBERT,通过在已有预训练架构上融入字符信息来解决这些问题。CharBERT在技术上融合了传统的CNN、RNN与现在流行的transformer结构,在模型特征上具有字符敏感、鲁棒和可拓展的特点,可以自然拓展到现在基于transformer的各种预训练模型上。另外,由于本工作限于英语单个语种和有限的算力,在通用的任务上效果提升有限。未来可以在更多的语种,尤其是在字符层级带有更多形态学信息的语言上进行适配,同时也可以在噪音种类上拓展到子词、句子级别的噪音,更全面地提升预训练模型的鲁棒性。
原文标题:COLING 2020 | 字符感知预训练模型CharBERT
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
模型
+关注
关注
1文章
3649浏览量
51715 -
机器学习
+关注
关注
66文章
8541浏览量
136236
原文标题:COLING 2020 | 字符感知预训练模型CharBERT
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
在Ubuntu20.04系统中训练神经网络模型的一些经验
基于大规模人类操作数据预训练的VLA模型H-RDT

请问如何在imx8mplus上部署和运行YOLOv5训练的模型?
用PaddleNLP为GPT-2模型制作FineWeb二进制预训练数据集

从Open Model Zoo下载的FastSeg大型公共预训练模型,无法导入名称是怎么回事?
用PaddleNLP在4060单卡上实践大模型预训练技术






 工商网监
工商网监
评论