 音频编码原理
音频编码原理

音频编码原理
语音编码致力于:降低传输所需要的信道带宽,同时保持输入语音的高质量。
语音编码的目标在于:设计低复杂度的编码器以尽可能低的比特率实现高品质数据传输。
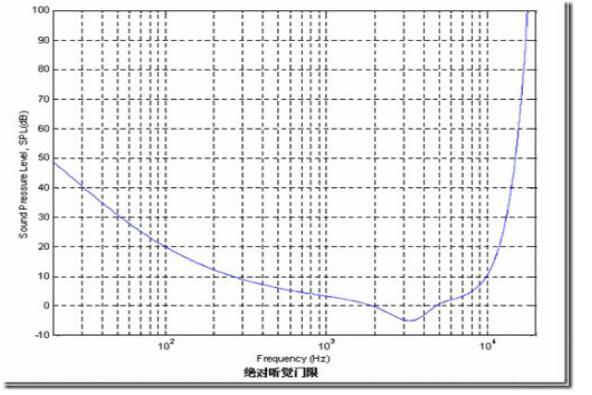
1、静音阈值曲线:只在安静环境下,人耳在各个频率能听到声音的阈值。
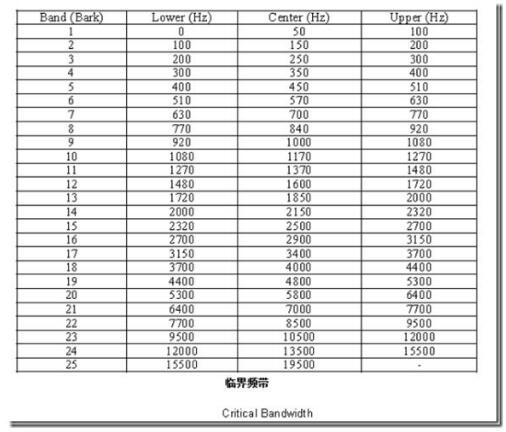
2、临界频带
由于人耳对不同频率的解析度不同,MPEG1/Audio将22khz内可感知的频率范围,依不同编码层,不同取样频率,划分成23~26个临界频带。下图列出理想临界频带的中心频率与频宽。图中可看到,人耳对低频的解析度较好。
3、频域上的掩蔽效应:幅值较大的信号会掩蔽频率相近的幅值较小的信号,如下图:
4、时域上的遮蔽效应:在一个很短的时间内,若出现了2个声音,SPL(sound pressure level)较大的声音会掩蔽SPL较小的声音。时域掩蔽效应分前向掩蔽(pre-masking)和后向掩蔽(post-masking),其中post-masking的时间会比较长,约是pre-masking的10倍。
时域遮蔽效应有助于消除前回音。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
音频编码
+关注
关注
0文章
38浏览量
13252
发布评论请先 登录
相关推荐
热点推荐
瑞芯微(EASY EAI)RV1126B 音频电路
1.音频电路主板引出了一组DSM音频接口和一组MIC差分输入接口。1.1DSM音频接口电路DSM音频(DigitalSignalModulator)指的是将


HX‑01 USB 音频编码模块:矿场通讯与音频系统的可靠核心解决方案
HX‑01 USB 音频编码模块以免驱兼容、高清语音、宽温稳定、抗干扰强、灵活配置、极简集成六大核心优势,精准解决矿山音频通讯的行业痛点,全面覆盖井下对讲、调度广播、安全监控、设备改造、应急处置等

HX-01 USB 音频编码模块:全场景语音交互核心,赋能多领域音频应用
HX‑01 USB 音频编码模块以一模块适配全场景的强大能力,打破不同领域音频应用的技术壁垒,从安防门禁的安全对讲、医疗监护的实时沟通,到智慧教育的清晰拾音、工业检测的精准采集,均能提供稳定、高效

基于 HX‑01 的 USB 音频编码模块设计与应用研究
HX‑01 模块以DSP+USB一体化架构,实现高性能、免驱、可配置的音频编码解决方案,在信噪比、失真度、通道灵活性、系统兼容性等方面具备显著优势,可广泛应用于智能对讲、监护通讯、嵌入式音频、教学终端、
16位PCM音频DAC AD1856:高性能音频解决方案
的纯净度和真实感。今天,我们就来详细探讨一款高性能的16位PCM音频DAC——AD1856。 文件下载: AD1856.pdf 一、AD1856概述 AD1856是一款单片、16位脉冲编码调制(PCM
磁铁在编码器中的作用与应用
在编码器中,磁铁的作用不可小觑,常用的磁性材料主要是钕铁硼和铁氧体,今天这篇文章主要介绍下磁铁用于哪些编码器类型,以及其具体作用。磁铁在编码器中的作用(功能)是什么?在编码器中,磁铁主

深入理解PCM:从底层代码到音频开发实战
当我们播放音乐、录制语音时,设备背后正在进行一场 "模拟与数字" 的转换游戏。PCM(Pulse Code Modulation,脉冲编码调制) 就是这场游戏的核心规则—— 它是将模拟音频信号(如人声、乐器声)转换为数字信号的标准方法,也是所有数字
高性能音频A/D转换器PCM4202:专业音频领域的理想之选
的性能和丰富的功能。接下来,让我们深入了解一下PCM4202的详细信息。 文件下载: pcm4202.pdf 一、产品概述 PCM4202是一款高性能的立体声音频A/D转换器,专为专业和广播音频应用而设计。它具备24位线性脉冲编码
蓝牙模块低功耗新突破:LE Audio技术详解(LC3编解码/多设备串流/广播音频)
Audio是蓝牙技术联盟(SIG)在2020年推出的全新音频技术标准,以低功耗蓝牙5.2为基础,采用ISOC(isochronous)架构,引入了创新的LC3音频编码算法,具有更低的延迟和更高的传输质量,同时


HX-01 USB 音频编码模块:重塑音频连接,赋能全场景创新
HX-01 是一款免驱 USB 音频编码模块,搭载专业 USB 编码 DSP 芯片,为音频输入输出提供高效解决方案。模块支持 Windows、MAC 及安卓 4.4 + 系统,兼容 U

新唐科技推出低延迟音频编解码器NAU88L21C
Audio CODEC (Audio Coder-Decoder) 是音频“编解码器”,主要功能是进行音频信号的编码(压缩)和解码(解压)。在音频信号处理过程中,信号的采集处理,

光纤如何传输数享音频?
生成 音频设备(如CD播放机、电脑)将声音信号转换为模拟电信号,再通过模数转换器(ADC)将其编码为数字信号(如PCM格式)。这一过程确保音频信息以二进制数据形式存在,便于后续调制。 电光调制 数字信号被送入光发射器(如激光二极
一款低功耗、高质量的24位立体声编解码器-CJC8972
24位立体声编解码器通过数字信号处理实现高精度音频编码与解码,核心在于对立体声信号的数字化处理及还原。



评论