 MySQL主从延迟的排查路径和解决方案
MySQL主从延迟的排查路径和解决方案

前言
MySQL 主从复制是生产环境中常用的高可用架构,通过将写操作同步到从库,实现数据冗余和读写分离。但主从延迟是一个让人头疼的问题:明明网络带宽充足,从库 CPU 也不高,为什么延迟就是降不下来?
很多人第一反应是"网络问题",但实际上主从延迟的原因五花八门,可能出在主库、从库、网络、配置等各个环节。本文从原理出发,详细分析主从延迟的各种原因,并给出排查路径和解决方案。
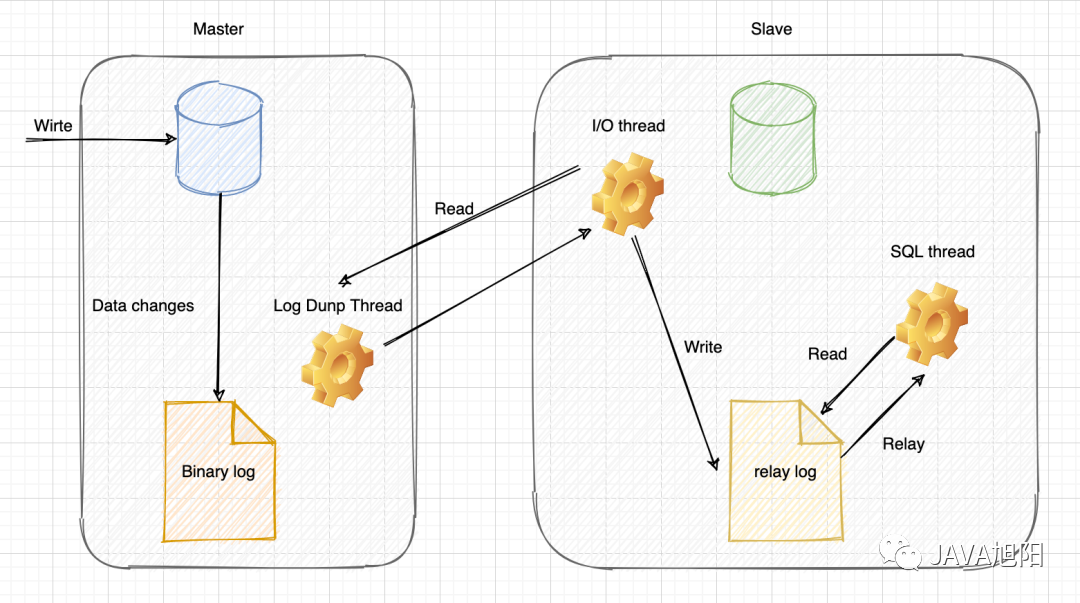
1 MySQL 主从复制原理
1.1 复制架构
MySQL 主从复制基于 binlog 实现,采用半同步或异步复制方式:
主库(Master) 从库(Slave) | | | 写入事务 | | --> 记录 binlog | | | | Dump Thread 发送 binlog ------> | | | I/O Thread 接收 | | --> 写入 relaylog | | | | SQL Thread 读取 | | --> 执行 SQL | | | Commit | Apply
复制涉及的线程:
主库 Binlog Dump Thread:将从库的请求读取 binlog 并发送
从库 I/O Thread:连接主库,请求 binlog,写入 relay log
从库 SQL Thread:读取 relay log,执行 SQL
1.2 复制方式
异步复制:主库提交事务后立即返回客户端,不等待从库确认。默认模式。
半同步复制:主库提交事务后,等待至少一个从库确认收到 binlog 后才返回客户端。
-- 安装半同步插件 INSTALLPLUGINrpl_semi_sync_masterSONAME'semisync_master.so'; INSTALLPLUGINrpl_semi_sync_slaveSONAME'semisync_slave.so'; -- 启用半同步 SETGLOBALrpl_semi_sync_master_enabled =1; SETGLOBALrpl_semi_sync_slave_enabled =1; -- 查看配置 SHOWVARIABLESLIKE'rpl_semi_sync%';
增强半同步(MySQL 8.0):等待从库应用并提交事务后才返回。
1.3 binlog 格式
STATEMENT:记录执行的 SQL 语句。优点是日志量小,缺点是某些函数(如 NOW()、UUID())在从库执行结果不同。
ROW:记录被修改的行。优点是结果准确,缺点是日志量大。
MIXED:混合模式。默认使用 STATEMENT,在需要时自动切换到 ROW。
-- 查看当前 binlog 格式 SHOWVARIABLESLIKE'binlog_format'; -- 设置 binlog 格式(需要 SUPER 权限) SETGLOBALbinlog_format ='ROW'; SETGLOBALbinlog_format ='STATEMENT'; SETGLOBALbinlog_format ='MIXED'; -- 配置文件设置 [mysqld] binlog_format = ROW
2 主从延迟监控
2.1 查看复制状态
-- 查看所有从库状态 SHOWSLAVEHOSTS; -- 查看从库复制状态(MySQL 5.7) SHOWSLAVESTATUSG -- 查看从库复制状态(MySQL 8.0,推荐使用) SHOWREPLICASTATUSG
关键指标说明:
-- MySQL 5.7 输出
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.1.100
Master_User: repl_user
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000456
Read_Master_Log_Pos: 456789012
Relay_Log_File: relay-bin.000123
Relay_Log_Pos: 456789200
Relay_Master_Log_File: mysql-bin.000456
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB: app_db
Replicate_Ignore_DB:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 456789012
Relay_Log_Space: 789012345
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: a1b2c3d4-xxxx-xxxx-xxxx-xxxxxxxxxxxx
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: a1b2c3d4-xxxx:1-12345
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 0
Network_Namespace:
关键字段详解:
| 字段 | 说明 | 正常值 |
|---|---|---|
| Seconds_Behind_Master | 延迟秒数 | 0 |
| Slave_IO_Running | I/O 线程运行状态 | Yes |
| Slave_SQL_Running | SQL 线程运行状态 | Yes |
| Master_Log_File | 主库 binlog 文件 | 与Read_Master_Log_Pos对应 |
| Read_Master_Log_Pos | I/O 线程读取位置 | 递增 |
| Relay_Master_Log_File | relay log对应的binlog | 与Exec_Master_Log_Pos对应 |
| Exec_Master_Log_Pos | SQL 线程执行位置 | 递增,与Read_Master_Log_Pos接近 |
| Last_Errno | 上次错误编号 | 0 |
| Last_Error | 上次错误信息 | 空 |
2.2 实时监控脚本
#!/bin/bash
# filename: check_replication_delay.sh
# 监控主从延迟
MYSQL_HOST="192.168.1.100"
MYSQL_PORT="3306"
MYSQL_USER="root"
MYSQL_PASS="your_password"
THRESHOLD=30 # 延迟阈值(秒)
whiletrue;do
# 获取延迟秒数
DELAY=$(mysql -h$MYSQL_HOST-P$MYSQL_PORT-u$MYSQL_USER-p$MYSQL_PASS-e"SHOW SLAVE STATUSG"2>/dev/null | grep"Seconds_Behind_Master"| awk'{print $2}')
if["$DELAY"="NULL"];then
echo"$(date)[WARN] 复制线程未运行"
elif["$DELAY"-gt$THRESHOLD];then
echo"$(date)[ERROR] 延迟:${DELAY}秒,超过阈值:${THRESHOLD}秒"
# 显示详细状态
mysql -h$MYSQL_HOST-P$MYSQL_PORT-u$MYSQL_USER-p$MYSQL_PASS-e"SHOW SLAVE STATUSG"2>/dev/null | grep -E"(Slave_IO_Running|Slave_SQL_Running|Master_Log_File|Read_Master_Log_Pos|Exec_Master_Log_Pos|Relay_Log_Space|Last_Error)"
else
echo"$(date)[OK] 延迟:${DELAY}秒"
fi
sleep 5
done
2.3 使用 Performance Schema 监控
-- MySQL 5.7+ 启用复制监控 -- 开启 performance_schema UPDATEmysql.general_logSET'general_log'='ON'; -- 查看复制相关的表 USEperformance_schema; -- 查看从库状态 SELECT*FROMreplication_connection_statusG -- 查看应用延迟 SELECT*FROMreplication_applier_statusG -- 查看协调事务状态 SELECT*FROMreplication_applier_status_by_coordinatorG -- 查看 worker 事务状态 SELECT*FROMreplication_applier_status_by_workerG -- 查看主库信息 SELECT*FROMreplication_group_members; -- 查看慢应用的事务 SELECT*FROMreplication_applier_status_by_worker WHERELAST_ERROR_NUMBER !=0;
3 常见延迟原因与排查
3.1 网络问题
排查方法:
# 1. 测试主从网络延迟 ping -c 100 192.168.1.100 | tail -5 # 2. 测试主从网络带宽 iperf3 -c 192.168.1.100 # 3. 查看从库网络连接状态 mysql -e"SHOW PROCESSLIST;"| grep -E"Binlog Dump|Has sent all" # 4. 查看网络监控 ss -tan | grep 3306 netstat -i | grep eth0
解决方案:
检查主从之间的网络延迟和带宽
使用压缩减少数据传输量(slave_compressed_protocol=1)
如果是跨机房复制,考虑使用专线或优化网络拓扑
-- 启用压缩协议 SETGLOBALslave_compressed_protocol =1; -- 配置文件 [mysqld] slave_compressed_protocol = 1
3.2 主库写入压力大
排查方法:
-- 1. 查看主库的写入 QPS SHOWSTATUSLIKE'Com_insert'; SHOWSTATUSLIKE'Com_update'; SHOWSTATUSLIKE'Com_delete'; SHOWSTATUSLIKE'Questions'; -- 2. 查看主库的 binlog 写入速度 SHOWSTATUSLIKE'Binlog_disk_writes'; SHOWSTATUSLIKE'Binlog_stmt_cache_disk_use'; -- 3. 查看从库relay log写入速度 SHOWSTATUSLIKE'Relay_log_space'; -- 4. 查看主库的写入线程 SHOWPROCESSLIST;
解决方案:
优化主库写入,避免高峰期的批量写入
使用并行复制提升从库应用速度
调整 sync_binlog 和 innodb_flush_log_at_trx_commit 平衡性能和数据安全
-- 调整 sync_binlog(建议 100-1000) SETGLOBALsync_binlog =1000; -- innodb_flush_log_at_trx_commit: -- 1: 每次事务提交时刷新日志(最安全,性能最低) -- 2: 事务提交时写入日志,但不刷新,由操作系统决定 -- 0: 不在事务提交时刷新,由 master thread 决定 SETGLOBALinnodb_flush_log_at_trx_commit =2;
3.3 从库 SQL 线程瓶颈
排查方法:
-- 1. 查看从库 SQL 线程状态 SHOWPROCESSLIST; -- 注意 State 列: -- "Reading event from the relay log" - 正常读取 -- "Slave has read all relay log..." - 追上主库了 -- "Waiting for an event from Coordinator" - 多线程复制协调器空闲 -- 其他状态可能有问题 -- 2. 查看等待的 Worker 线程 USEperformance_schema; SELECT*FROMreplication_applier_status_by_worker; -- 3. 查看 relay log 应用情况 SHOWSTATUSLIKE'Slave_retrieved_gtid_set'; SHOWSTATUSLIKE'Slave_executed_gtid_set';
常见问题:
单线程复制瓶颈:MySQL 5.6 以前的版本从库只有一个 SQL 线程,串行执行所有事件
大事务阻塞:主库的一个大事务在从库执行时,SQL 线程被阻塞
-- 查看主库正在执行的事务 SHOWENGINEINNODBSTATUS; -- 查看 History list length,如果很大说明有大事务在执行
解决方案:
升级到 MySQL 5.7+ 启用多线程并行复制
将大事务拆分成小事务
-- MySQL 5.7 多线程复制配置 [mysqld] slave_parallel_workers = 16 # 建议设置为 CPU 核心数的 50%-80% slave_parallel_type = LOGICAL_CLOCK # 基于组提交 slave_parallel_type = DATABASE # 基于数据库(需要配置 Replicate_Do_DB) -- 查看当前 worker 数量 SHOWVARIABLESLIKE'slave_parallel_workers'; -- 查看多线程复制状态 SHOWSLAVESTATUSG -- 观察 Slave_SQL_Running_State 是否为 "Worker"
3.4 大事务延迟
问题现象:主库写入很快,但从库的延迟突然增加,然后慢慢减小。
排查方法:
-- 1. 查看从库 relay log 位置变化 -- 如果 Read_Master_Log_Pos 一直在增长,但 Exec_Master_Log_Pos 增长很慢,说明有大事务 -- 2. 监控 relay log 文件大小变化 SHOWMASTERSTATUS; -- 主库 SHOWSLAVESTATUS; -- 从库,对比 Exec_Master_Log_Pos -- 3. 查看当前执行的事务 SHOWPROCESSLIST; -- 如果 State 显示 "Reading event from the relay log" 但长时间不变,说明正在执行大事务 -- 4. 查看 Innodb 事务状态 SHOWENGINEINNODBSTATUS; -- 关注 History list length 和 Lock wait time
解决方案:
拆分大事务:将 DELETE、UPDATE 大表的操作拆分成小批量
-- 错误的做法:一次性删除100万条 DELETEFROMlarge_tableWHEREcreated_at < '2024-01-01'; -- 正确的做法:分批删除 DELETE FROM large_table WHERE created_at < '2024-01-01' LIMIT 10000; -- 循环执行直到删完
使用 pt-archiver 工具:Percona Toolkit 的 pt-archiver 可以安全归档和删除大表数据
# 安装 percona-toolkit
yum install percona-toolkit -y
# 使用 pt-archiver 删除数据(不锁表)
pt-archiver --sourceh=localhost,D=test,t=large_table
--where"created_at < '2024-01-01'"
--limit 1000
--txn-size 1000
--purge
--charset utf8
3.5 表缺少主键或唯一索引
问题原理:MySQL Row 格式复制时,如果表没有主键或唯一索引,DELETE 和 UPDATE 操作需要在从库全表扫描才能定位到对应的行。
排查方法:
-- 1. 查找没有主键的表
SELECTt.TABLE_SCHEMA, t.TABLE_NAME
FROMinformation_schema.TABLES t
JOINinformation_schema.COLUMNS c
ONt.TABLE_SCHEMA = c.TABLE_SCHEMAANDt.TABLE_NAME = c.TABLE_NAME
WHEREt.TABLE_SCHEMANOTIN('mysql','information_schema','performance_schema','sys')
ANDt.TABLE_TYPE ='BASE TABLE'
ANDt.AUTO_INCREMENTISNOTNULL
GROUPBYt.TABLE_SCHEMA, t.TABLE_NAME
HAVINGMAX(c.COLUMN_KEY) !='PRI';
-- 2. 检查复制延迟与特定表的关系
-- 在主库执行可能产生大量 binlog 的操作,观察从库延迟变化
-- 3. 查看从库慢查询日志
SHOWVARIABLESLIKE'slow_query_log%';
SHOWVARIABLESLIKE'long_query_time';
解决方案:
为所有表添加主键
如果不能添加主键,至少添加一个唯一索引
-- 添加主键 ALTERTABLEyour_tableADDPRIMARYKEY(id); -- 如果有业务逻辑的唯一字段组合,添加唯一索引 ALTERTABLEyour_tableADDUNIQUEKEYuk_col1_col2 (col1, col2);
3.6 从库服务器负载高
排查方法:
# 1. 查看 CPU 使用率 top htop # 2. 查看磁盘 I/O iostat -x 1 iotop # 3. 查看内存使用 free -h # 4. 查看 InnoDB 缓冲池命中率 mysql -e"SHOW ENGINE INNODB STATUSG"| grep"Buffer pool hit rate" # 5. 查看连接数 mysql -e"SHOW STATUS LIKE 'Threads_connected';" mysql -e"SHOW STATUS LIKE 'Max_used_connections';"
解决方案:
将从库移出高负载服务器
增加从库硬件资源
优化从库查询(如果从库承担读请求)
-- 调整 InnoDB 缓冲池大小 SETGLOBALinnodb_buffer_pool_size =10737418240; -- 10GB -- 调整 InnoDB 线程并发数 SETGLOBALinnodb_thread_concurrency =32; -- 调整 I/O 线程数 SETGLOBALinnodb_read_io_threads =16; SETGLOBALinnodb_write_io_threads =16;
3.7 复制冲突
问题原理:主从复制是基于 binlog 的,在从库上执行的写操作(虽然不应该有)可能导致复制冲突。
排查方法:
-- 1. 查看复制错误 SHOWSLAVESTATUSG -- 查看 Last_Errno 和 Last_Error 字段 -- 2. 查看从库错误日志 SHOWVARIABLESLIKE'log_error'; -- 查找 "Duplicate entry" 或 "Primary key exists" 等错误 -- 3. 查看从库上的写操作(不应该有) SHOWPROCESSLIST; -- 检查是否有非系统账号的写操作
解决方案:
确保没有应用连接从库执行写操作
使用 read_only 参数保护从库
-- 启用从库只读 SETGLOBALread_only =ON; -- 允许有 SUPER 权限的用户写入(通常是管理员) SETGLOBALsuper_read_only =ON; -- 配置文件 [mysqld] read_only = 1 super_read_only = 1
3.8 GTID 模式下的特殊问题
问题现象:MySQL 5.7+ 使用 GTID 复制时,某些情况下会出现延迟。
排查方法:
-- 1. 查看 GTID 执行状态 SHOWSLAVESTATUSG -- Retrieved_Gtid_Set: I/O 线程接收到的 GTID 集合 -- Executed_Gtid_Set: SQL 线程已执行的 GTID 集合 -- 2. 对比两者差异 -- Retrieved_Gtid_Set - Executed_Gtid_Set = 待应用的 GTID -- 3. 查看事务执行时间 SELECT*FROMperformance_schema.events_statements_history ORDERBYTIMER_WAITDESCLIMIT10; -- 4. 查看是否有人在从库执行事务 SELECT*FROMperformance_schema.replication_connection_statusG -- 关注 FREE_TREATS、GCT_RETRIEVED、HCT_RETRIEVED 等字段
常见问题与解决方案:
主库执行的事务被跳过:检查 slave_skip_counter 和 gtid_skip_counter
-- 跳过 N 个事务(慎用) SETGLOBALgtid_skip_counter =1; -- 正确做法:使用 gtid_executed 表管理
从库找不到事务:主库的 binlog 被 PURGE,但还没有同步到从库
-- 查看主库的 binlog 保留策略 SHOWVARIABLESLIKE'binlog_expire_logs_seconds'; SHOWVARIABLESLIKE'expire_logs_days';
4 实战排查案例
4.1 案例一:从库延迟忽高忽低
现象:从库延迟在 0 到 300 秒之间波动。
排查过程:
# 1. 持续监控延迟变化
whiletrue;do
echo"$(date):$(mysql -e 'SHOW SLAVE STATUSG' | grep Seconds_Behind_Master | awk '{print $2}')"
sleep 1
done
# 2. 观察主库写入模式
# 发现主库在每小时有批量导入操作,导致 binlog 突增
# 3. 检查主库的 binlog 生成速度
mysql -e"SHOW MASTER STATUS;"
# 每分钟观察 Binlog_Logpos 变化
# 4. 检查从库 SQL 线程状态
mysql -e"SHOW PROCESSLIST;"
# 发现 "Reading event from the relay log" 长时间不变
根因:主库每小时有批量导入,产生大量 binlog,从库 SQL 线程来不及应用。
解决:启用多线程并行复制,调整 slave_parallel_workers。
SETGLOBALslave_parallel_workers =16; SETGLOBALslave_parallel_type = LOGICAL_CLOCK;
4.2 案例二:从库完全停止复制
现象:Seconds_Behind_Master 突然变为 0,但 Relay_Log_Pos 不再变化。
排查过程:
-- 1. 查看复制状态 SHOWSLAVESTATUSG -- 2. 发现 Slave_IO_Running = Yes, Slave_SQL_Running = No -- Last_Errno: 1062 -- Last_Error: Duplicate entry for key 'PRIMARY' -- 3. 查看错误详情 -- 尝试在主库执行相同语句 SELECT*FROMproblem_tableWHEREid= xxx;
根因:从库存在数据冲突,导致 SQL 线程停止。
解决:根据业务场景选择跳过错误或修复数据。
-- 方法1:跳过这个错误(适用于可以容忍重复的场景) STOPSLAVE; SETGLOBALgtid_skip_counter =1; STARTSLAVE; SETGLOBALgtid_skip_counter =0; -- 方法2:删除重复数据后重新复制 DELETEFROMproblem_tableWHEREid= xxx; STARTSLAVE; -- 方法3:使用 pt-table-checksum 检查主从数据一致性 pt-table-checksumh=master,u=root,p=pass h=slave,u=root,p=pass--replicate-check=1
4.3 案例三:延迟持续增加,追不上主库
现象:延迟从几秒开始,一直增长到几个小时。
排查过程:
-- 1. 检查 I/O 线程和 SQL 线程状态 SHOWSLAVESTATUSG -- Read_Master_Log_Pos 和 Exec_Master_Log_Pos 差距很大 -- 说明 I/O 线程接收速度快,但 SQL 线程执行慢 -- 2. 检查从库负载 SHOWPROCESSLIST; -- SQL 线程长时间处于某个状态 -- 3. 检查 relay log 大小 SHOWSTATUSLIKE'Relay_log_space'; -- 4. 检查是否有大事务 SHOWENGINEINNODBSTATUS; -- History list length 很大 -- 5. 检查慢查询 SHOWVARIABLESLIKE'slow_query_log%';
根因:某个 UPDATE 语句在从库执行很慢(缺索引)。
解决:优化从库的查询性能。
-- 找到慢的 SQL,在主库执行 EXPLAIN 分析 EXPLAINUPDATEproblem_tableSETstatus='done'WHEREupdated_at < '2024-01-01'; -- 添加索引 ALTER TABLE problem_table ADD INDEX idx_updated_at (updated_at); -- 确认索引已应用 SHOW INDEX FROM problem_table;
4.4 案例四:网络正常但复制延迟
现象:主从之间 ping 延迟很低,但复制延迟很高。
排查过程:
# 1. 抓包分析主从复制流量 tcpdump -i eth0 port 3306 -w /tmp/replication.pcap # 2. 分析网络包 # 发现有很多小的 binlog 事件,而不是批量的大事件 # 3. 检查从库的 net_write_timeout 和 net_read_timeout mysql -e"SHOW VARIABLES LIKE 'net_%';"
根因:主库写入很频繁,但每个事务很小,binlog 传输和解析开销大。
解决:启用主库的binlog_row_image优化,并调整从库网络超时参数。
-- 使用 MINIMAL 格式记录行镜像(只记录修改的列) SETGLOBALbinlog_row_image ='MINIMAL'; -- 增加网络超时时间 SETGLOBALnet_write_timeout =300; SETGLOBALnet_read_timeout =300; -- 启用压缩 SETGLOBALslave_compressed_protocol =1;
5 预防与优化
5.1 配置优化
# my.cnf 配置示例 [mysqld] # 复制相关 log-slave-updates = 1 slave-parallel-workers = 16 slave-parallel-type = LOGICAL_CLOCK slave-preserve-commit-order = 1 slave_compressed_protocol = 1 # binlog 优化 sync_binlog = 1000 binlog_format = ROW binlog_row_image = MINIMAL binlog_expire_logs_seconds = 604800 # 7天 # InnoDB 优化 innodb_flush_log_at_trx_commit = 2 innodb_buffer_pool_size = 16G innodb_thread_concurrency = 32 innodb_read_io_threads = 16 innodb_write_io_threads = 16 innodb_flush_method = O_DIRECT # 网络优化 net_write_timeout = 300 net_read_timeout = 300
5.2 监控告警
#!/bin/bash
# filename: replication_monitor.sh
# 主从复制监控告警脚本
MYSQL_HOST="192.168.1.100"
MYSQL_PORT="3306"
MYSQL_USER="monitor"
MYSQL_PASS="monitor_password"
ALERT_EMAIL="ops@example.com"
THRESHOLD_WARNING=30
THRESHOLD_CRITICAL=300
# 获取状态
STATUS=$(mysql -h$MYSQL_HOST-P$MYSQL_PORT-u$MYSQL_USER-p$MYSQL_PASS-e"
SHOW SLAVE STATUSG
"2>/dev/null)
IO_RUNNING=$(echo"$STATUS"| grep"Slave_IO_Running:"| awk'{print $2}')
SQL_RUNNING=$(echo"$STATUS"| grep"Slave_SQL_Running:"| awk'{print $2}')
DELAY=$(echo"$STATUS"| grep"Seconds_Behind_Master:"| awk'{print $2}')
LAST_ERROR=$(echo"$STATUS"| grep"Last_Error:"| awk'{print $2}')
# 检查线程状态
if["$IO_RUNNING"!="Yes"] || ["$SQL_RUNNING"!="Yes"];then
echo"严重: 复制线程未运行"| mail -s"[CRITICAL] MySQL Replication Down"$ALERT_EMAIL
exit1
fi
# 检查延迟
if["$DELAY"="NULL"];then
echo"严重: 无法获取延迟信息"| mail -s"[CRITICAL] MySQL Replication Error"$ALERT_EMAIL
exit1
fi
if[$DELAY-ge$THRESHOLD_CRITICAL];then
echo"严重: 复制延迟${DELAY}秒,超过临界值${THRESHOLD_CRITICAL}秒"| mail -s"[CRITICAL] MySQL Replication Lag"$ALERT_EMAIL
elif[$DELAY-ge$THRESHOLD_WARNING];then
echo"警告: 复制延迟${DELAY}秒,超过阈值${THRESHOLD_WARNING}秒"| mail -s"[WARNING] MySQL Replication Lag"$ALERT_EMAIL
fi
# 检查错误
if[ ! -z"$LAST_ERROR"];then
echo"发现复制错误:$LAST_ERROR"| mail -s"[ERROR] MySQL Replication Error"$ALERT_EMAIL
fi
5.3 定期检查脚本
-- filename: check_replication_health.sql -- 定期检查主从复制健康状态 -- 1. 检查复制线程状态 SELECT CASE WHENSlave_IO_Running ='Yes'ANDSlave_SQL_Running ='Yes'ANDSeconds_Behind_Master =0THEN'HEALTHY' WHENSlave_IO_Running ='Yes'ANDSlave_SQL_Running ='Yes'ANDSeconds_Behind_Master >0THEN'LAGGING' ELSE'BROKEN' ENDASreplication_status, Seconds_Behind_Master, Master_Log_File, Read_Master_Log_Pos, Relay_Master_Log_File, Exec_Master_Log_Pos, Last_Error FROMinformation_schema.PROCESSLIST WHERECommand ='Binlog Dump';
6 总结
6.1 延迟排查检查清单
| 检查项 | 命令/方法 |
|---|---|
| 延迟秒数 | SHOW SLAVE STATUS 中 Seconds_Behind_Master |
| I/O 线程状态 | Slave_IO_Running 是否为 Yes |
| SQL 线程状态 | Slave_SQL_Running 是否为 Yes |
| 网络延迟 | ping master_ip 和iperf3 |
| 主库写入压力 | SHOW STATUS LIKE 'Com_%' |
| 从库负载 | top ,iostat,free |
| 大事务 | SHOW ENGINE INNODB STATUS 的 History list length |
| 缺少索引 | EXPLAIN 慢查询 |
| 并行复制 | slave_parallel_workers 设置 |
6.2 常见延迟原因速查
| 原因 | 表现 | 解决方案 |
|---|---|---|
| 网络问题 | I/O 线程延迟 | 检查网络带宽和延迟 |
| 主库压力大 | 延迟与主库写入同步 | 优化主库写入,多线程复制 |
| SQL 线程瓶颈 | 单线程复制 | 启用并行复制 |
| 大事务 | 延迟突增后缓慢减小 | 拆分大事务 |
| 缺主键 | Relay_Log_Pos 不增长 | 添加主键或唯一索引 |
| 从库负载高 | 延迟持续增长 | 优化从库性能 |
| 复制冲突 | SQL 线程停止 | 修复冲突或跳过错误 |
6.3 优化建议
使用 GTID 简化复制管理:便于监控和问题定位
启用多线程并行复制:MySQL 5.7+ 推荐使用 LOGICAL_CLOCK 模式
使用半同步复制:确保事务至少到达一个从库
定期检查数据一致性:使用 pt-table-checksum
做好监控和告警:延迟超过阈值及时通知
主库写入优化:避免高峰期大批量写入
从库性能优化:合理配置 InnoDB 缓冲池和线程数
主从延迟不是单一原因造成的,需要从主库、从库、网络、配置等多个维度综合排查。养成良好的监控习惯,在问题发生时才能快速定位根因。
-
cpu
+关注
关注
68文章
11375浏览量
226414 -
网络
+关注
关注
14文章
8382浏览量
95702 -
MySQL
+关注
关注
1文章
939浏览量
29855
原文标题:MySQL 主从延迟排查:不只是网络的锅
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
简单介绍MySQL延迟主从复制
一个操作把MySQL主从复制整崩了
mysql如何实现主从复制的具体流程
mysql主从复制主要有几种模式
mysql主从复制的原理
mysql主从复制 混合类型的复制
构建数据库解决方案,基于华为云 Flexus X 实例容器化 MySQL 主从同步架构



评论