 MySQL主从延迟排查全流程
MySQL主从延迟排查全流程

一、概述
1.1 背景介绍
复制延迟一上来,很多人先盯Seconds_Behind_Master。这个指标当然要看,但它只能告诉你“延迟已经发生了”,不能告诉你是网络拉取慢、Relay Log 堆积、SQL 线程执行慢、并行复制没吃满,还是下游被长事务、DDL、热点表拖住了。
生产环境更稳的排查方式是:先分清 IO 线程和 SQL 线程,再判断是拉不到、写不进、还是应用不过来。如果只是看单个秒数,最容易把真正的问题藏掉。
1.2 技术特点
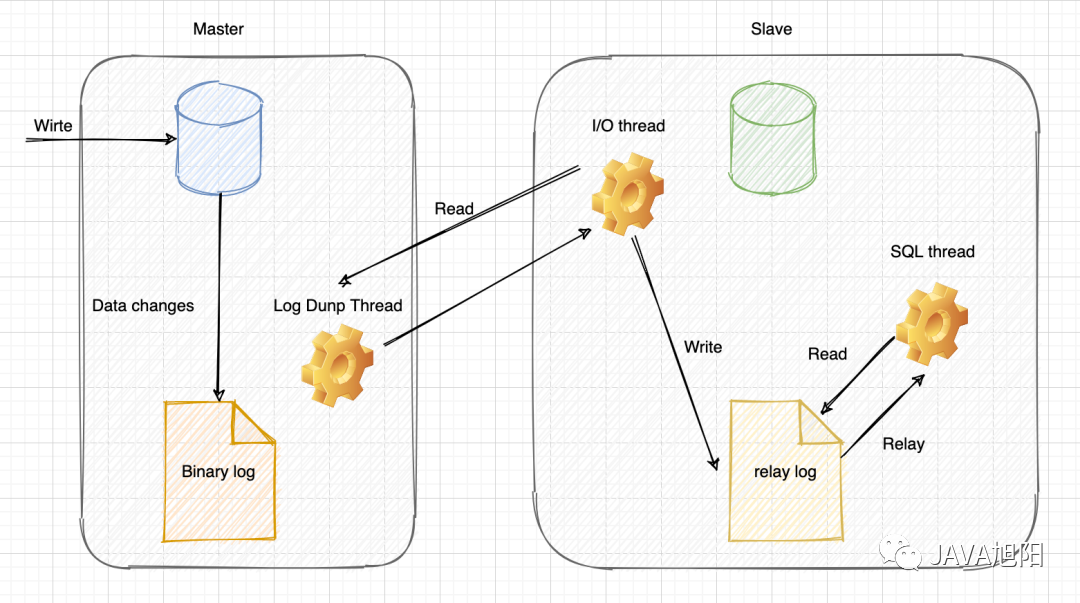
从复制链路拆问题:Source → 网络 → IO Thread → Relay Log → SQL / Applier Thread。
兼顾新旧版本字段:MySQL 8.0 推荐SHOW REPLICA STATUS,旧环境仍可能看到Seconds_Behind_Master。
贴近线上治理:不仅说怎么查,也说怎么避免复制被长事务拖死。
1.3 适用场景
场景一:业务读流量打到从库,延迟突然升高导致读到旧数据。
场景二:主库写入正常,从库relay log堆积。
场景三:发布、DDL、批处理后复制延迟持续几分钟甚至几十分钟。
1.4 环境要求
| 组件 | 版本要求 | 说明 |
|---|---|---|
| MySQL | 8.0+ 推荐 | 示例以SHOW REPLICA STATUS为主 |
| 复制模式 | GTID 或传统 binlog 位点 | 两者命令略有差异 |
| 指标采集 | mysqld_exporter | 监控复制延迟与线程状态 |
| 权限 | 具备复制和性能视图查询权限 | 需要查performance_schema |
二、详细步骤
2.1 准备工作
2.1.1 系统检查
SHOWREPLICASTATUSG SHOWPROCESSLIST; SHOWVARIABLESLIKE'server_id'; SHOWVARIABLESLIKE'gtid_mode'; SHOWVARIABLESLIKE'slave_parallel_workers';
先回答:
IO 线程是否正常拉日志
SQL / Applier 线程是否正常执行
延迟是持续增长还是可追平
并行复制有没有启用,是否真的吃满
2.1.2 安装依赖
sudo apt update ||true sudo apt install -y mysql-client jq ||true sudo yum install -y mysql jq ||true
2.1.3 第一轮确认
SHOWREPLICASTATUSG SELECT*FROMperformance_schema.replication_connection_statusG SELECT*FROMperformance_schema.replication_applier_status_by_workerG
2.2 核心配置
2.2.1 第一步:先区分“拉取慢”还是“执行慢”
核心判断字段:
Replica_IO_Running/Slave_IO_Running
Replica_SQL_Running/Slave_SQL_Running
Seconds_Behind_Source/Seconds_Behind_Master
Relay_Log_Space
Last_IO_Error、Last_SQL_Error
如果 IO 线程不正常,优先查:
SHOWREPLICASTATUSG
如果 SQL 线程正常但追不上,优先查:
SELECTWORKER_ID, LAST_APPLIED_TRANSACTION, APPLYING_TRANSACTION, LAST_APPLIED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP, LAST_APPLIED_TRANSACTION_END_APPLY_TIMESTAMP FROMperformance_schema.replication_applier_status_by_worker;
2.2.2 第二步:标准配置示例
# 文件路径:/etc/my.cnf.d/replication.cnf [mysqld] server_id=102 log_bin=mysql-bin binlog_format=ROW gtid_mode=ON enforce_gtid_consistency=ON relay_log_recovery=ON slave_parallel_type=LOGICAL_CLOCK slave_parallel_workers=8 read_only=ON super_read_only=ON
参数说明:
binlog_format=ROW:复制一致性更稳
relay_log_recovery=ON:异常重启后更容易恢复 relay log 状态
slave_parallel_workers=8:并行复制要按业务写入模型调,不是越大越好
super_read_only=ON:避免业务误写从库
2.2.3 第三步:按三条线下钻
看复制状态:
SHOWREPLICASTATUSG SHOWBINARYLOGSTATUS;
看热点事务和锁:
SHOWPROCESSLIST; SELECT*FROMinformation_schema.innodb_trxG SHOWENGINEINNODBSTATUSG
看延迟是否卡在单个事务:
SELECTTHREAD_ID, EVENT_NAME, TIMER_WAIT FROMperformance_schema.events_stages_current WHEREEVENT_NAMELIKE'stage/sql/%';
2.3 启动和验证
2.3.1 启动服务
STOPREPLICA; STARTREPLICA; SHOWREPLICASTATUSG
2.3.2 功能验证
SHOWREPLICASTATUSG SELECT*FROMperformance_schema.replication_connection_statusG SELECT*FROMperformance_schema.replication_applier_status_by_workerG
三、示例代码和配置
3.1 完整配置示例
3.1.1 主配置文件
# 文件路径:/etc/my.cnf.d/replication.cnf [mysqld] server_id=102 log_bin=mysql-bin binlog_format=ROW gtid_mode=ON enforce_gtid_consistency=ON relay_log_recovery=ON slave_parallel_type=LOGICAL_CLOCK slave_parallel_workers=8 read_only=ON super_read_only=ON
3.1.2 辅助脚本
#!/usr/bin/env bash set-euo pipefail MYSQL_CMD="${MYSQL_CMD:-mysql -uroot -p}" OUT_DIR="/tmp/mysql-replica-$(date +%F-%H%M%S)" mkdir -p"$OUT_DIR" $MYSQL_CMD-e"SHOW REPLICA STATUSG">"$OUT_DIR/replica-status.txt" $MYSQL_CMD-e"SHOW PROCESSLIST">"$OUT_DIR/processlist.txt" $MYSQL_CMD-e"SELECT * FROM performance_schema.replication_connection_statusG">"$OUT_DIR/connection-status.txt" $MYSQL_CMD-e"SELECT * FROM performance_schema.replication_applier_status_by_workerG">"$OUT_DIR/applier-status.txt" $MYSQL_CMD-e"SHOW ENGINE INNODB STATUSG">"$OUT_DIR/innodb-status.txt" echo"artifacts saved to$OUT_DIR"
3.2 实际应用案例
案例一:不是网络慢,是单个大事务把 SQL 线程卡住
场景描述:从库延迟从几十毫秒涨到 18 分钟,主库没报错,网络也正常。
实现代码:
SHOWREPLICASTATUSG SHOWPROCESSLIST; SELECT*FROMinformation_schema.innodb_trxG
运行结果:
Seconds_Behind_Source: 1087 Replica_IO_Running: Yes Replica_SQL_Running: Yes Relay_Log_Space: 1293844832
根因是主库一次性提交了超大批量更新事务,从库 SQL 线程长时间卡在单事务 apply。处理动作:
把批处理切小批次
大表更新改成分段执行
保留并行复制但别指望它能拆开单个超大事务
案例二:不是 SQL 线程慢,是 IO 线程拉不到新 binlog
场景描述:主从延迟持续增长,Relay_Log_Space却不大。
实现步骤:
看 IO/SQL 线程
SHOWREPLICASTATUSG
看错误信息
SHOWREPLICASTATUSG
查网络和权限
mysql -hsource-db -e"SHOW BINARY LOG STATUS;" telnetsource-db 3306
根因是复制链路网络抖动叠加复制账号权限异常,IO 线程断续重连,延迟不断累积。
案例三:DDL 和元数据锁把复制线程长期卡住
场景描述:某次结构变更后,从库延迟持续 40 多分钟。IO 线程正常,Relay Log 也在增长,但 SQL 线程一直追不上。
实现步骤:
看复制状态
SHOWREPLICASTATUSG
查元数据锁和事务
SELECT*FROMperformance_schema.metadata_locksG SELECT*FROMinformation_schema.innodb_trxG SHOWPROCESSLIST;
看是否被 DDL 卡住
SHOWENGINEINNODBSTATUSG
运行结果:
Waiting for table metadata lock
根因是主库 DDL 进入复制链路后,从库上又有长查询占着元数据锁,SQL 线程一直卡在同一条语句。处理动作:
先终止阻塞复制的长查询
大表 DDL 改到低峰窗口
对高风险 DDL 预演复制影响
这类延迟如果只看Seconds_Behind_Source,你知道它慢了,但不知道它为什么永远追不上。
四、最佳实践和注意事项
4.1 最佳实践
4.1.1 性能优化
优化点一:并行复制要开,但要结合业务写入模式验证,热点表和单大事务不会因为 worker 多就 magically 变快。
优化点二:批处理、DDL、大事务必须做节流和窗口管理。
优化点三:主从延迟监控不能只看秒数,还要看 IO/SQL 线程状态和 Relay Log 增长速度。
4.1.2 安全加固
安全措施一:从库保持super_read_only=ON,避免误写。
安全措施二:复制账号最小权限,定期轮换密码。
安全措施三:复制链路变更先在从库灰度验证。
4.1.3 高可用配置
HA 方案一:关键读流量不要只绑一台从库,延迟高时可自动摘流。
HA 方案二:复制监控和业务读延迟监控联动。
备份策略:保留关键时段SHOW REPLICA STATUS和performance_schema快照。
4.2 注意事项
4.2.1 配置注意事项
警告:Seconds_Behind_Master或Seconds_Behind_Source为0,不等于绝对没问题。复制线程断开、SQL thread 卡住、延迟刚好被短暂追平,都可能让你误判。
大事务和 DDL 是复制延迟的常见放大器
并行复制没配置好,延迟会长期追不上
从库性能不足时,复制延迟本质上是资源问题
4.2.2 常见错误
| 错误现象 | 原因分析 | 解决方案 |
|---|---|---|
| 秒数很高,但线程都正常 | SQL 线程在追大事务 | 查长事务、DDL、热点表 |
| 秒数不高,但读流量读到旧数据 | 监控窗口太粗或刚短暂追平 | 增加更细粒度采样 |
| Relay Log 持续增长 | IO 正常拉取,SQL 执行跟不上 | 查 apply 能力、锁等待、资源 |
4.2.3 兼容性问题
版本兼容:8.0 新旧字段名有差异,脚本里要兼容Master/Source命名。
平台兼容:云盘性能、跨可用区网络时延会直接影响复制。
组件依赖:GTID、MTS、binlog 格式和 DDL 策略都会影响复制行为。
五、故障排查和监控
5.1 故障排查
5.1.1 日志查看
grep -Ei'replica|slave|relay|error'/var/log/mysqld.log | tail -50
5.1.2 常见问题排查
问题一:延迟升高,但Relay_Log_Space不大
SHOWREPLICASTATUSG
解决方案:优先查 IO 线程、网络、权限、主库 binlog 获取。
问题二:Relay_Log_Space很大,秒数持续增加
SHOWREPLICASTATUSG SHOWPROCESSLIST;
解决方案:优先查 SQL 线程 apply 慢、锁等待、大事务。
问题三:并行复制开了,还是追不上
症状:slave_parallel_workers大于 0,但延迟长期不降
排查:
SHOWVARIABLESLIKE'slave_parallel%'; SELECT*FROMperformance_schema.replication_applier_status_by_workerG
解决:判断写入是否具备并行空间,热点表和单大事务场景要从业务侧拆解
5.1.3 调试模式
SHOWREPLICASTATUSG SHOWENGINEINNODBSTATUSG
5.2 性能监控
5.2.1 关键指标监控
SHOWREPLICASTATUSG
5.2.2 监控指标说明
| 指标名称 | 正常范围 | 告警阈值 | 说明 |
|---|---|---|---|
| 复制延迟秒数 | < 1s | > 10s 持续5m | 只做结果告警 |
| IO 线程状态 | Running | 非 Running | 日志拉取异常 |
| SQL 线程状态 | Running | 非 Running | Apply 异常 |
| Relay Log 空间 | 平稳 | 持续增长15m | 执行跟不上 |
5.2.3 监控告警配置
groups: -name:mysql-replication rules: -alert:MySQLReplicationLagHigh expr:mysql_slave_status_seconds_behind_master>10 for:5m -alert:MySQLReplicationSQLThreadDown expr:mysql_slave_status_sql_running==0 for:1m -alert:MySQLReplicationIOThreadDown expr:mysql_slave_status_slave_io_running==0 for:1m
5.3 备份与恢复
5.3.1 备份策略
#!/usr/bin/env bash set-euo pipefail mysql -uroot -p -e"SHOW REPLICA STATUSG"> /backup/replica-status-$(date +%F).txt mysql -uroot -p -e"SHOW MASTER STATUSG"> /backup/master-status-$(date +%F).txt
5.3.2 恢复流程
采样现场:bash ./mysql-replica-collect.sh
停止复制:STOP REPLICA;
修复根因后恢复:START REPLICA;
验证追平:SHOW REPLICA STATUSG
六、总结
6.1 技术要点回顾
主从延迟不能只看秒数
先分 IO 线程和 SQL 线程,再看 Relay Log 和事务特征
大事务、DDL、热点表是最常见的复制放大器
并行复制能提速,但救不了单个超大事务
6.2 进阶学习方向
GTID 与复制拓扑治理
并行复制与事务拆分
只读流量摘流与延迟感知路由
6.3 参考资料
MySQL Replication Status- 复制状态字段说明
Performance Schema Replication Tables- 复制相关性能视图
MySQL Replication Options- 从库复制参数
附录
A. 命令速查表
SHOWREPLICASTATUSG SHOWPROCESSLIST; SELECT*FROMperformance_schema.replication_connection_statusG SELECT*FROMperformance_schema.replication_applier_status_by_workerG SHOWENGINEINNODBSTATUSG
B. 配置参数详解
slave_parallel_workers:并行复制 worker 数
relay_log_recovery:异常重启后 relay log 恢复
super_read_only:更严格的只读保护
C. 术语表
| 术语 | 英文 | 解释 |
|---|---|---|
| 复制延迟 | Replication Lag | 从库应用事务落后主库的时间差 |
| 中继日志 | Relay Log | 从库拉取主库 binlog 后本地保存的日志 |
| 应用线程 | SQL / Applier Thread | 在从库执行事务的线程 |
| GTID | Global Transaction Identifier | 全局事务标识 |
-
MySQL
+关注
关注
1文章
928浏览量
29739 -
线程
+关注
关注
0文章
510浏览量
20868
原文标题:MySQL 主从延迟排查全流程:不是只看 Seconds_Behind_Master
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
简单介绍MySQL延迟主从复制
利用MySQL进行一主一从的主从复制
MySQL主从复制原理详解
一个操作把MySQL主从复制整崩了



评论