 如何排查和解决MySQL死锁问题
如何排查和解决MySQL死锁问题

生产环境 MySQL 死锁:定位思路与根治方案
MySQL死锁是数据库运维和后端开发中最棘手的问题之一。与普通查询超时不同,死锁意味着两个或多个事务相互持有对方需要的锁,形成循环依赖,导致涉及的表或行无法被任何事务继续修改。业务系统一旦出现死锁,轻则部分请求报错,重则整个业务链路的写操作集体阻塞。
本文从死锁的形成原理出发,系统讲解如何排查、分析和解决MySQL死锁问题。内容适用于MySQL 5.7/8.0及兼容版本(MySQL 8.0在锁机制上有部分改进)。
1. 死锁的形成原理
1.1 事务与锁的基本概念
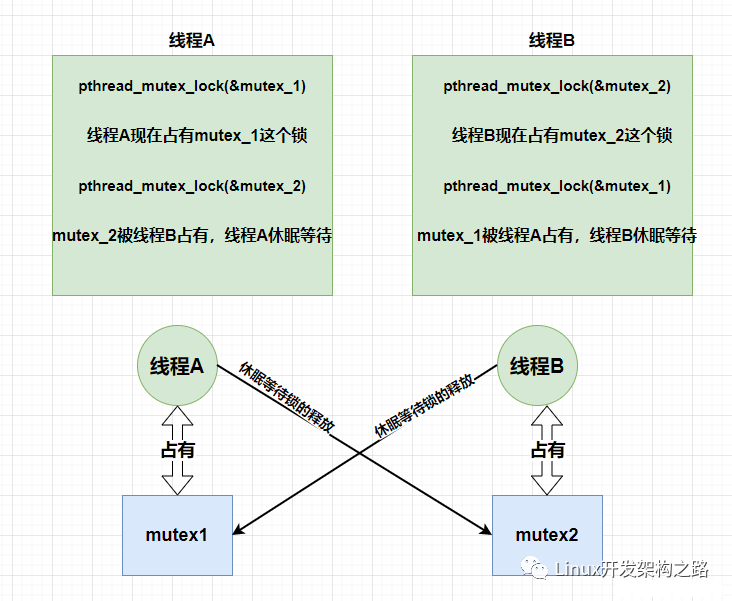
MySQL的InnoDB引擎采用行级锁(Row Lock)实现并发控制。事务在对某行数据进行修改时,会对该行加锁,直到事务提交(COMMIT)或回滚(ROLLBACK)时才释放锁。
-- 事务A:先锁定id=1的行 BEGIN; SELECT*FROMaccountsWHEREid=1FORUPDATE; -- 对id=1加排他锁 -- 此时事务A持有id=1的锁,等待事务B释放id=2的锁 -- 事务B:先锁定id=2的行 BEGIN; SELECT*FROMaccountsWHEREid=2FORUPDATE; -- 对id=2加排他锁 -- 此时事务B持有id=2的锁,等待事务A释放id=1的锁 -- 循环等待形成:事务A等事务B,事务B等事务A → 死锁
1.2 死锁的必要条件
数据库理论中,死锁的形成必须满足以下四个条件(Carl-RoadConditions):
| 条件 | 含义 | 在MySQL中的体现 |
|---|---|---|
| 互斥条件 | 资源不能被共享 | 一行数据同一时刻只能被一个事务持有排他锁 |
| 持有并等待 | 事务持有资源的同时请求其他资源 | 事务A持有id=1锁,等待id=2锁 |
| 不可抢占条件 | 资源不能被强制释放 | 锁只能被持有事务显式释放,不能被其他事务抢走 |
| 循环等待条件 | 形成事务间的等待循环 | 事务A等事务B,事务B等事务A |
MySQL的InnoDB引擎通过死锁检测(Deadlock Detection)来打破循环等待:当检测到死锁后,会主动回滚代价最小的事务(通常是持有最少行锁的事务),让其他事务继续执行。
1.3 锁的类型与兼容性
InnoDB的锁类型远比表面上复杂:
| 锁类型 | 模式 | 兼容性 | 说明 |
|---|---|---|---|
| 共享锁(S) | SELECT ... LOCK IN SHARE MODE | 与S锁兼容,与X锁互斥 | 读取时不阻止其他读 |
| 排他锁(X) | SELECT ... FOR UPDATE | 与S锁、X锁均互斥 | 写入时锁定整行 |
| 记录锁(Record Lock) | 索引记录 | 锁定单个索引记录 | 最常见的行锁 |
| 间隙锁(Gap Lock) | 范围查询时 | 锁定区间而非记录 | 防止幻读 |
| Next-Key Lock | 记录锁+间隙锁 | 锁定记录及其区间 | InnoDB默认的RR隔离级别锁 |
| 意向锁(Intention Lock) | 表级锁 | 表上的IX/IS锁 | 表示事务将在表上加行级锁 |
Next-Key Lock是死锁的高发区:当执行范围查询(如WHERE id > 10 AND id < 20)时,Next-Key Lock会锁定(10, 20)这个间隙,如果另一个事务试图插入这个范围内的记录,会被阻塞,长期积累可能导致死锁。
-- 事务A:锁定id > 10的所有行(实际锁定区间10到正无穷) BEGIN; SELECT*FROMordersWHEREuser_id >100FORUPDATE; -- Next-Key Lock锁定区间 (100, +∞) -- 事务B:插入id=101的新订单(尝试获取插入意向锁) BEGIN; INSERTINTOorders (id, user_id, amount)VALUES(NULL,101,100); -- 被事务A的Next-Key Lock阻塞:Gap Lock冲突 -- 事务A再执行:插入id=102的新订单 INSERTINTOorders (id, user_id, amount)VALUES(NULL,102,200); -- 尝试获取插入意向锁,但事务B已经持有id=102的Gap锁 -- 死锁形成
2. 死锁的排查方法
2.1 开启死锁日志
MySQL默认将死锁信息记录到错误日志,但不会记录每次死锁的完整锁等待图。可以通过以下方式增强日志:
-- 查看当前死锁日志配置 SHOWVARIABLESLIKE'innodb_print_all_deadlocks'; -- 默认OFF -- 开启所有死锁信息输出到错误日志(需要SUPER权限) SETGLOBALinnodb_print_all_deadlocks =ON; -- 查看死锁日志(MySQL错误日志文件) -- Linux: /var/log/mysql/error.log -- macOS Homebrew: /usr/local/var/mysql/{hostname}.err -- Windows: {数据目录}mysql*.err
innodb_print_all_deadlocks = ON会将每次死锁的完整信息输出到错误日志,包括涉及的事务、SQL语句、持有的锁和等待的锁。
2.2 使用information_schema获取锁信息
-- 查看当前所有事务持有的锁 SELECT t.trx_id, t.trx_state, t.trx_started, t.trx_rows_locked, t.trx_query, l.lock_id, l.lock_mode, l.lock_type, l.lock_table, l.lock_index, l.lock_space, l.lock_page, l.lock_rec, l.lock_data FROMinformation_schema.INNODB_TRX t JOINinformation_schema.INNODB_LOCKS lONt.trx_id = l.lock_trx_id ORDERBYt.trx_started; -- 查看锁等待关系 SELECT requesting_trx.trx_idASrequesting_trx_id, requesting_trx.trx_queryASrequesting_query, blocking_trx.trx_idASblocking_trx_id, blocking_trx.trx_queryASblocking_query, blocking_locks.lock_idASblocking_lock_id, blocking_locks.lock_modeASblocking_lock_mode, blocking_locks.lock_typeASblocking_lock_type, blocking_locks.lock_tableASblocking_lock_table FROMinformation_schema.INNODB_LOCK_WAITS lw JOINinformation_schema.INNODB_TRX requesting_trxONlw.requesting_trx_id = requesting_trx.trx_id JOINinformation_schema.INNODB_TRX blocking_trxONlw.blocking_trx_id = blocking_trx.trx_id JOINinformation_schema.INNODB_LOCKS blocking_locksONlw.blocking_lock_id = blocking_locks.lock_id;
2.3 使用performance_schema监控锁事件
MySQL 8.0引入了更强大的performance_schema锁监控:
-- 开启锁监控(需要重启或重新配置) UPDATEperformance_schema.setup_instruments SETENABLED ='YES', TIMED ='YES' WHERENAMELIKE'wait/lock%'; UPDATEperformance_schema.setup_consumers SETENABLED ='YES' WHERENAMELIKE'%events_transactions%'; -- 查看最近的锁等待事件 SELECT*FROMperformance_schema.events_waits_history_long WHEREevent_nameLIKE'%lock%' ORDERBYTIMER_ENDDESC LIMIT20;
2.4 解读死锁日志
开启innodb_print_all_deadlocks后,错误日志会输出类似以下内容的死锁报告:
2025-04-27 1045 0x7f8c9a4c8700 INNODB MONITOR OUTPUT ======================== LATEST DETECTED DEADLOCK ------------------------ 2025-04-27 1042 0x7f8c9a4c8700 *** (1) TRANSACTION: TRANSACTION 12345, ACTIVE 5 sec inserting mysql tablesinuse 1, locked 1 LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s) MySQL thread id 99, OS thread handle 0x7f8c9a4c8700, query id 10001 localhost root updating -- 事务1正在执行的SQL UPDATE orders SET status ='shipped'WHERE user_id > 100 *** (1) HOLDS THE LOCK(S): RECORD LOCKS space id 123 page no 5 n bits 200 index idx_user_id of table `shop`.`orders` trx id 12345 lock_mode X locks rec but not gap -- 事务1持有orders表中idx_user_id索引上的记录锁 *** (1) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 123 page no 5 n bits 200 index idx_user_id of table `shop`.`orders` trx id 12345 lock_mode X locks rec but not gap waiting -- 事务1正在等待另一个记录锁(可能是Gap锁冲突) *** (2) TRANSACTION: TRANSACTION 12346, ACTIVE 3 sec inserting mysql tablesinuse 1, locked 1 LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s) MySQL thread id 100, OS thread handle 0x7f8c9a4c8800, query id 10002 localhost root updating -- 事务2正在执行的SQL INSERT INTO orders (id, user_id, amount) VALUES (NULL, 105, 299.00) *** (2) HOLDS THE LOCK(S): RECORD LOCKS space id 123 page no 5 n bits 200 index idx_user_id of table `shop`.`orders` trx id 12346 lock_mode X locks gap before rec -- 事务2持有Gap锁(锁定区间) *** (2) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 123 page no 5 n bits 200 index idx_user_id of table `shop`.`orders` trx id 12346 lock_mode X locks rec but not gap waiting -- 事务2正在等待记录锁 -- MySQL决定回滚事务12346(较晚开始,持有锁较少) *** WE ROLL BACK TRANSACTION 12346
关键解读点:
LOCK WAIT表示当前正在等待锁
HOLDS THE LOCK(S)表示事务已持有的锁
WE ROLL BACK TRANSACTION后面是MySQL决定回滚的事务ID
lock_mode X locks rec but not gap是记录锁,不锁定间隙
lock_mode X locks gap before rec是间隙锁,锁定记录前的区间
3. 常见死锁场景与解决方案
3.1 场景一:不同事务以不同顺序访问多行
问题:事务A先锁定行1再锁定行2,事务B先锁定行2再锁定行1,形成循环等待。
解决:确保所有事务以相同顺序访问资源。
# 错误的并发写入(死锁高发) deftransfer_funds_wrong(from_id, to_id, amount): withconnection.cursor()ascursor: # 事务1: A->B, 事务2: B->A → 死锁 cursor.execute("SELECT balance FROM accounts WHERE id = %s FOR UPDATE", (from_id,)) cursor.execute("SELECT balance FROM accounts WHERE id = %s FOR UPDATE", (to_id,)) # 正确的并发写入(顺序加锁) deftransfer_funds_correct(from_id, to_id, amount): withconnection.cursor()ascursor: # 按ID顺序加锁,避免循环等待 first_id, second_id = (from_id, to_id)iffrom_id < to_id else (to_id, from_id) cursor.execute("SELECT balance FROM accounts WHERE id = %s FOR UPDATE", (first_id,)) cursor.execute("SELECT balance FROM accounts WHERE id = %s FOR UPDATE", (second_id,))
3.2 场景二:索引导致的间隙锁冲突
问题:范围查询或使用索引范围扫描时,Next-Key Lock锁定较宽区间,导致插入操作被阻塞。
解决:
使用覆盖索引减少锁范围:覆盖索引(Covering Index)可以让查询只需扫描索引,不必回表,减少锁定的记录数。
-- 创建覆盖索引:查询只需扫描idx_user_id,无需回表锁定主键 CREATEINDEXidx_user_id_coveringONorders(user_id,status, amount); -- 改写查询使用覆盖索引 SELECTstatus, amountFROMordersWHEREuser_id =100;
调整隔离级别:将隔离级别从REPEATABLE READ降为READ COMMITTED,可以减少Gap Lock的使用。
-- 方法1:会话级别调整 SETSESSIONTRANSACTIONISOLATIONLEVELREADCOMMITTED; -- 方法2:配置文件永久调整(my.cnf / my.ini) -- [mysqld] -- transaction-isolation = READ-COMMITTED
3.3 场景三:主从延迟导致的锁等待升级
问题:主从架构中,从库应用事件存在延迟,主库上的长事务持有锁时间延长,增加死锁概率。
解决:
-- 检查从库延迟 SHOWSLAVESTATUSG -- 关注 Seconds_Behind_Master 字段 -- 优化从库应用速率 STOPSLAVE; CHANGEMASTERTOMASTER_RETRY_COUNT =3; STARTSLAVE;
3.4 场景四:大事务拆分
问题:单个事务中处理过多数据,持有锁的时间过长,死锁窗口扩大。
解决:将大事务拆分为小批量事务,减少单次持有的锁数量。
# 错误:单事务处理10万条记录
defbatch_update_wrong(ids):
withconnection.cursor()ascursor:
cursor.execute("BEGIN")
foridinids: # 10万次循环,锁持有时间长
cursor.execute(
"UPDATE orders SET status = 'processed' WHERE id = %s",
(id,)
)
cursor.execute("COMMIT")
# 正确:分批处理,每批500条
defbatch_update_correct(ids, batch_size=500):
withconnection.cursor()ascursor:
foriinrange(0, len(ids), batch_size):
batch = ids[i:i + batch_size]
cursor.execute("BEGIN")
cursor.execute(
"UPDATE orders SET status = 'processed' WHERE id IN (%s)"%
",".join(["%s"] * len(batch)),
batch
)
cursor.execute("COMMIT")
connection.commit() # 每批后立即释放锁
4. 代码层面的防死锁设计
4.1 应用层锁顺序控制
在应用层维护一个全局锁顺序规则:
importthreading # 定义全局锁顺序:按资源ID排序 # 所有需要同时锁定多个资源的代码,必须按此顺序获取锁 LOCK_ORDER = {} classAccountService: def__init__(self, db_connection): self.conn = db_connection deftransfer(self, from_id: int, to_id: int, amount: decimal.Decimal): # 按ID顺序确定加锁顺序 first_id, second_id = sorted([from_id, to_id]) # 获取应用层逻辑锁(防止代码层面的并发问题) withself._get_lock(first_id): withself._get_lock(second_id): self._do_transfer(first_id, second_id, amount) def_get_lock(self, account_id: int): """获取指定账户的应用层锁""" ifaccount_idnotinLOCK_ORDER: LOCK_ORDER[account_id] = threading.Lock() returnLOCK_ORDER[account_id]
4.2 锁超时机制
设置合理的锁等待超时时间,避免无限等待:
-- 查看当前锁等待超时(默认50秒) SHOWVARIABLESLIKE'innodb_lock_wait_timeout'; -- 默认50 -- 设置锁等待超时为10秒 SETGLOBALinnodb_lock_wait_timeout =10; -- 在应用程序中捕获锁等待超时异常
importpymysql
frompymysqlimportOperationalError
try:
withconnection.cursor()ascursor:
cursor.execute("SELECT ... FOR UPDATE")
exceptOperationalErrorase:
ife.args[0] ==1205: # Lock wait timeout error
logger.error(f"Lock wait timeout exceeded for transaction")
raiseRetryableError("Lock timeout, should retry")frome
raise
4.3 重试机制
锁等待超时不等同于死锁,被超时的其他事务可能已经完成。应用层应实现有限重试:
importtime
frompymysqlimportOperationalError
MAX_RETRIES =3
RETRY_DELAY =0.5# 秒
deftransfer_with_retry(from_id, to_id, amount):
forattemptinrange(MAX_RETRIES):
try:
withconnection.cursor()ascursor:
cursor.execute("BEGIN")
# 锁定逻辑...
cursor.execute("COMMIT")
returnTrue
exceptOperationalErrorase:
ife.args[0] ==1205: # Lock wait timeout
connection.rollback()
logger.warning(f"Attempt{attempt +1}failed, retrying...")
time.sleep(RETRY_DELAY * (attempt +1))
continue
raise
logger.error(f"Transfer failed after{MAX_RETRIES}attempts")
returnFalse
5. 监控与预防
5.1 持续监控指标
建议在数据库监控系统中追踪以下指标:
| 指标 | 阈值建议 | 告警策略 |
|---|---|---|
| Innodb_row_lock_waits | > 100/min | 超过基线2倍告警 |
| Innodb_row_lock_time_avg | > 500ms | 超过基线3倍告警 |
| Threads_connected | > max_connections * 0.7 | 接近连接上限告警 |
| Lock_wait_timeout | 出现任何 | 必须告警 |
-- 查看InnoDB行锁统计 SHOWSTATUSLIKE'Innodb_row_lock%'; -- +-------------------------------+-------+ -- | Variable_name | Value | -- +-------------------------------+-------+ -- | Innodb_row_lock_current_waits | 0 | -- | Innodb_row_lock_time | 12345 | -- | Innodb_row_lock_time_avg | 123 | -- | Innodb_row_lock_time_max | 5000 | -- | Innodb_row_lock_waits | 100 | -- +-------------------------------+-------+
5.2 慢查询与死锁的关联分析
长时间运行的查询是死锁的主要诱因。定期分析慢查询日志:
# 查看慢查询配置 mysql -e"SHOW VARIABLES LIKE 'slow_query%';" mysql -e"SHOW VARIABLES LIKE 'long_query_time';" # 常用分析命令 mysqldumpslow -s t -t 20 /var/log/mysql/slow.log # 按时间排序top 20 mysqldumpslow -s c -t 20 /var/log/mysql/slow.log # 按次数排序top 20
6. 排障清单
| 问题现象 | 排查步骤 | 解决方案 |
|---|---|---|
| 事务报错"Deadlock found" | 1. 查看错误日志 2. 分析锁等待图 3. 找出循环等待的SQL | 调整SQL顺序或加锁范围 |
| Lock wait timeout exceeded | 1. 检查innodb_lock_wait_timeout 2. 查看哪个事务长时间持有锁 | 优化长事务,拆分批次 |
| 某表频繁死锁 | 1. 分析该表的访问模式 2. 检查索引设计 3. 评估隔离级别 | 优化索引或降级隔离级别 |
| 从库延迟导致主库死锁 | 1.SHOW SLAVE STATUS2. 检查从库IO/SQL线程 | 优化从库应用或增加从库数量 |
| 批量更新时偶发死锁 | 1. 分析批量SQL的锁范围 2. 检查是否跨表操作 | 按主键顺序处理,减少锁冲突 |
死锁排查的核心能力在于正确解读INNODB_TRX、INNODB_LOCKS、INNODB_LOCK_WAITS三个系统表联合查询出的锁等待关系图。运维和开发人员应建立肌肉记忆:在生产环境出现死锁时,第一时间导出这三个表的数据快照,同时开启innodb_print_all_deadlocks抓取完整的死锁上下文。事后的日志分析比现场排查更有价值,因为死锁发生时相关事务可能已经回滚。
-
数据库
+关注
关注
7文章
4086浏览量
68573 -
MySQL
+关注
关注
1文章
932浏览量
29780
原文标题:生产环境 MySQL 死锁:定位思路与根治方案
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
死锁是什么?产生死锁的主要原因有哪些
RS-485 总线的死锁检测与解除
MySQL死锁原因排查技巧详解

MySQL中的高级内容详解
MySQL并发Replace into导致死锁场景简析
如何解决I2C器件死锁的问题?
Linux内核死锁lockdep功能

死锁的产生因素
死锁的现象及原理
死锁的现象以及原理
java死锁产生的条件
mysql配置失败怎么办
浅谈MySQL常见死锁场景




评论