 自动驾驶端到端时代,还会使用BEV和Transformer吗?
自动驾驶端到端时代,还会使用BEV和Transformer吗?

[首发于智驾最前沿微信公众号]在讨论自动驾驶技术时,很多人容易产生一种误解,认为端到端是一项孤立的新技术,会完全取代BEV(鸟瞰图)或Transformer,也有小伙伴曾在后台留言询问端到端模型还会使用BEV+Transformer吗?
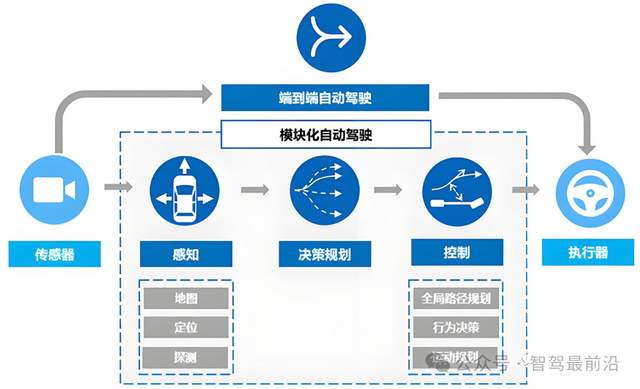
事实上,端到端并不是要推翻现有的感知架构,而是将原本各司其职的模块,通过一种更高效、更具逻辑性的方式融合在一个庞大的神经网络里。BEV和Transformer依然是这套系统的眼睛和骨架,只是它们的工作方式发生了变革。

为什么空间感知依然是核心?
自动驾驶最基本的要求就是让车辆知道自己在哪里,周围有什么。虽然端到端模型可以直接输出驾驶轨迹,但如果系统内部没有建立起准确的空间模型,它给出的动作就会变得不可预测且缺乏逻辑。
BEV技术的核心价值在于它提供了一个统一的空间底座。它能将布置在车身四周的多个摄像头采集到的图像信息,实时投影到一个俯视的角度下。在这个角度里,物体之间的距离、车道的走向以及交叉口的布局,都变得和人类看地图一样直观。

图片源自:网络
在目前的端到端方案中,BEV不再只是为了画出漂亮的感知画面供工程师查看。它的真实作用是作为特征容器。当多路摄像头的数据涌入模型时,系统会在这个统一的空间平面内进行特征叠加。
这种做法解决了摄像头视野重叠或遮挡的问题,让模型在处理诸如大曲率弯道或复杂的城市路口时,能够拥有一份连贯的空间记忆。如果缺少了这个空间视角,端到端模型就只能在混乱的像素中摸索,很难表现出稳定的驾驶决策能力。

Transformer是如何连接时空的?
如果说BEV是舞台,那么Transformer就是舞台上的总导演,负责决定哪些信息该被保留,哪些信息该被重点关注。在端到端模型内部,Transformer的注意力机制解决了感知中的一个痛点,如何把不同位置、不同时间的信息关联起来。

图片源自:网络
通过这种机制,模型可以自主学习哪些画面特征对当前的驾驶任务最重要。如在通过红绿灯路口时,它会自动把权重分配给前方的信号灯和侧方的行人,而不是路边无关紧要的树木。
更重要的是,现在的端到端模型非常依赖Transformer来处理时间序列。驾驶不是一个静态的瞬间,而是一个连续的过程。Transformer能够像人类的短期记忆一样,把过去几秒钟的特征信息串联起来。这让模型具备了预测能力,即使遇到一个骑车人被路边的公交车挡住了的场景,系统依然能通过之前的观察记录,推断出这个人的大概位置和行进速度。这种对时空信息的深度整合,让端到端模型在面对“鬼探头”等极端场景时,反应比纯粹的规则算法更加灵敏且自然。

神经网络内部是怎么交流的?
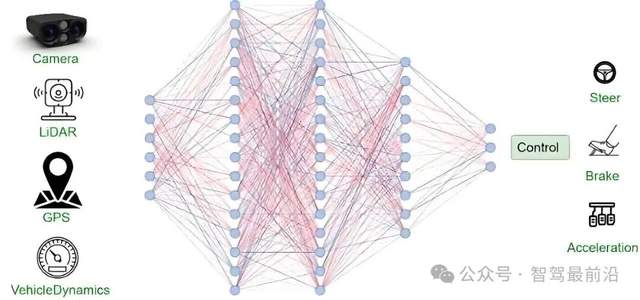
传统的自动驾驶架构像是一条流水线,感知算完了给预测,预测算完了给规控。每一道工序都会把数据翻译成如目标物的坐标、速度数值等人类能读懂的格式。但在端到端模型中,这种交流变得更加高效。BEV和Transformer生成的特征,直接以高维向量的形式传给下游。这种方式最大的进步在于避免了信息折损。

图片源自:网络
以往如果我们把一个异形物体误识别成了电线杆,后面的规划模块就可能因为这个错误的标签而做出错误的规避。但在端到端系统里,即便模型叫不出那个物体的名字,它也能通过Transformer感知到那个位置的特征是不可通行的,从而直接计算出一条绕行的曲线。
这种从原始特征到驾驶行为的直接映射,省去了中间繁杂的人工规则定义,让车辆在面对各种奇奇怪怪的路况时,表现得更像一个有经验的老司机,而不是只会按说明书干活的机器人。

未来的模型还会怎么变?
虽然现在的端到端模型高度依赖BEV和Transformer,但这套组合也在不断进化。目前的趋势是让模型具备更强的世界感,很多技术方案也正在尝试引入Occupancy(占用网络)的思想,让模型不再关注具体的物体,而是关注空间中的每一个体积单位是否被占据。这种做法让端到端模型在处理施工区域、散落物等不规则障碍物时,拥有了更高的鲁棒性。

图片源自:网络
此外,随着多模态大模型的普及,端到端架构也开始吸收语言和视觉大模型的经验。未来的系统可能不仅能看到路,还能通过类似Transformer的架构去理解一些如识别出路边交警的手势、判断出前方车辆突然减速的意图等隐性的交通逻辑。
所以,BEV和Transformer并不会消失,它们反而在端到端的大趋势下,从原本独立的插件变成了系统神经网络中不可分割的神经元,共同让自动驾驶变得更加聪明。
审核编辑 黄宇
-
端到端
+关注
关注
0文章
51浏览量
10857 -
自动驾驶
+关注
关注
794文章
14985浏览量
181446 -
大模型
+关注
关注
2文章
3765浏览量
5269
发布评论请先 登录
为什么一段式端到端自动驾驶很难落地?

自动驾驶端到端为什么会出现黑盒现象?

Transformer如何让自动驾驶大模型获得思考能力?
端到端与模块化自动驾驶的数据标注要求有何不同?
如何训练好自动驾驶端到端模型?

自动驾驶中端到端仿真与基于规则的仿真有什么区别?
西井科技端到端自动驾驶模型获得国际认可
一文读懂特斯拉自动驾驶FSD从辅助到端到端的演进
端到端自动驾驶相较传统自动驾驶到底有何提升?
Nullmax端到端自动驾驶最新研究成果入选ICCV 2025
为什么自动驾驶端到端大模型有黑盒特性?




评论