 强化学习会让自动驾驶模型学习更快吗?
强化学习会让自动驾驶模型学习更快吗?

[首发于智驾最前沿微信公众号]在谈及自动驾驶大模型训练时,有的技术方案会采用模仿学习,而有些会采用强化学习。同样作为大模型的训练方式,强化学习有何不同?又有什么特点呢?

什么是强化学习?
强化学习是一种让机器通过“试错”学会决策的办法。与监督学习不同,监督学习是有人提供示范答案,让模型去模仿;而强化学习不会把每一步的“正确答案”都告诉你,而是把环境、动作和结果连起来,让机器自己探索哪个行为长期看起来更有利,便往那个行为中去靠。
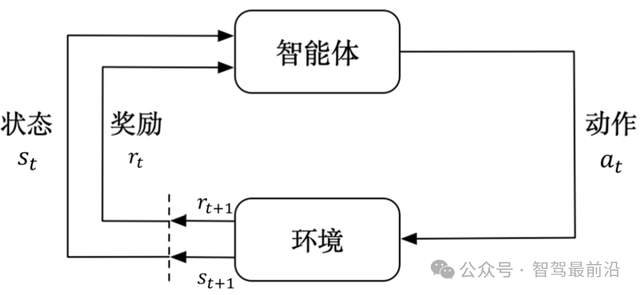
强化学习示意图,图片源自:网络
这里的“有利”是通过一个叫做奖励(reward)的信号来衡量的。奖励可以是正向的,也可以是负向的,机器的目标是让长期累计的奖励尽可能多。把决策过程抽象成在某个状态下采取某个动作会进入到下一个状态并获得相应的奖励的机制,这种数学化的描述叫做马尔可夫决策过程。
从定义上看,这个概念有些晦涩难懂,举个简单的例子吧。自动驾驶系统在驾驶仿真里开车,顺利通过一个路口就可以得到奖励,但撞到路缘或急刹车将被罚分,这些奖励和惩罚会引导学习算法偏向于那些带来更多正向回报的驾驶行为。强化学习把这样一整套“感知—决策—反馈—调整”的循环自动化,让模型在没有人逐条教它规则的情况下也能学出一套安全的驾驶策略。

为什么强化学习会被用到自动驾驶中
自动驾驶汽车会通过各种传感器识别路况,但它不是简单识别摄像头拍摄的图片或激光雷达探测到的点云这么简单,它会不断与环境进行交互。自动驾驶汽车需要在复杂且动态的交通环境里做出连续决策,这些决策不仅影响当前瞬间的安全,也会改变未来的交通态势。

图片源自:网络
强化学习刚好擅长解决这种“序列决策”的问题。相比传统方案中把每种场景写成规则的方式,强化学习能够把环境状态(来自摄像头、雷达、激光雷达以及速度、加速度等车载信息)映射成动作(转向、加速、减速等),并通过长期回报来优化策略。
这种端到端或者半端到端的学习方式让模型在面对复杂交互、非线性场景时比规则系统更具适应性。很多技术方案中会把强化学习与深度学习结合起来,处理高维输入,然后再输出决策。
在安全可控的仿真环境里,强化学习还可以以极大的样本量去尝试各种边缘情况,积累经验,之后再把模型迁移或微调到真实车辆上,这将极大优化模型的训练效果。
简而言之,当问题表现为“连续决策、长期回报、即时反馈”时,强化学习提供了一条比规则更有弹性的途径。
强化学习如何应用到自动驾驶中
将自动驾驶系统拆分开看,其实是一条连续的系统,其最前端是感知,中间是决策规划,末端是执行控制。强化学习可以在多个环节发挥作用,但更多是用在决策与控制之间。
感知模块负责把摄像头、雷达、激光雷达这些原始数据处理成如周围车辆的位置和速度、车道线、交通标志等对路况有用的表征信息。决策模块要基于这些信息决定接下来几秒钟内的动作。

图片源自:网络
强化学习的优势在于,它可以把决策看作是一个优化问题,其不只是考虑当前动作的即时好坏,更会衡量动作序列在未来带来的累计效果。因此在跟车、换道、避障和复杂交叉口应对这类需要考虑连贯动作与长期影响的任务上,强化学习能学出比单步规则更流畅、可预测的行为。
在很多的技术方案中,强化学习不仅可以单独作为一个端到端控制器,从传感器输入直接学习输出控制命令,也可以作为决策层的一个组件,与传统规划器或约束优化器协同工作。前者在学出来后更简洁,但可解释性和可验证性较差;后者能把强化学习产生的策略纳入现有安全约束下进行检查和修正,从而兼顾灵活性和安全性。
现阶段很多常见的做法是先用模拟器做大量训练,得到一个初步策略,再用监督学习的方法做预训练,把人类驾驶数据用作引导,最后在仿真里用强化学习精调。这样的复合流程能显著提升模型训练效率并降低在真实世界试错的风险。
强化学习有什么问题?
强化学习的概念看起来的确不错,可以让大模型自己学习,并研究出一套可行的驾驶策略。但想把它安全可靠地部署到车辆上,并不是一朝一夕的事情。其最大的问题就是安全与鲁棒性。
仿真和真实世界一定会存在差距,这个差距会让在仿真中表现良好的策略在实车上出现意外行为。环境变化、传感器噪声、极端天气、未见过的交通流模式等都会考验模型的泛化能力。深度强化学习一般还是黑盒式的,难以解释模型为什么在某个时刻做出某个决定,这给责任归属、事故分析和安全验证带来了极大挑战。
强化学习的训练成本也是很现实的问题,强化学习需要大量多样的样本来覆盖边缘情况,光靠真实道路采集不仅危险还很慢,因此很多训练必须在高质量的仿真中完成,而高保真模拟本身就需要很高的成本投入且需不断精细化,这无疑提高了成本。
强化学习还会面临在线学习和离线学习之间的取舍。完全在线学习在真实道路上意味着系统会在行驶过程中不断试错,这必然会带来很多的风险。而长期离线训练则可能让模型落后于环境变化,为此,就就需要周期性地迁移学习或进行持续集成。
最后的话
强化学习的核心价值在于为序列决策问题提供系统化的解决框架,尤其在处理长期目标、复杂交互与高维感知方面展现出很强的潜力。但想将其从算法潜力变成可靠应用的转化,始终面临可验证性、安全约束与工程落地的核心挑战。当前可以将强化学习视为一种强大的优化与决策组件,在明确边界内与传统方法进行架构性整合。
审核编辑 黄宇
-
自动驾驶
+关注
关注
795文章
15057浏览量
182001
发布评论请先 登录
Momenta R7强化学习世界模型实现量产首发
Momenta R7强化学习世界模型助力上汽大众ID. ERA 9X正式上市
上汽奥迪E5 Sportback车型升级搭载全新Momenta强化学习大模型
上汽大众ID. ERA 9X全球首发搭载Momenta R7强化学习世界模型
理想汽车发布下一代自动驾驶基础模型MindVLA-o1

Momenta R7强化学习世界模型即将推出
如何构建适合自动驾驶的世界模型?


多智能体强化学习(MARL)核心概念与算法概览

上汽别克至境E7首发搭载Momenta R6强化学习大模型
如何训练好自动驾驶端到端模型?

自动驾驶中常提的“强化学习”是个啥?

自动驾驶中Transformer大模型会取代深度学习吗?




评论