 LLM推理模型是如何推理的?
LLM推理模型是如何推理的?

这篇文章《(How) Do Reasoning Models Reason?》对当前大型推理模型(LRM)进行了深刻的剖析,超越了表面的性能宣传,直指其技术本质和核心局限。以下是基于原文的详细技术原理、关键过程与核心见解拆解。
一、核心论点与总览
LRM(如 o1, R1)的“推理”能力提升,并非源于模型学会了人类式的逻辑推理,而是通过两类主要技术手段,优化了生成过程,使其在输出最终答案前,模仿并生成看似合理的推导过程。其本质是在“生成-测试”框架中,将外部验证信号逐步“编译”进生成模型参数中。
二、两大技术路径的详细原理与过程
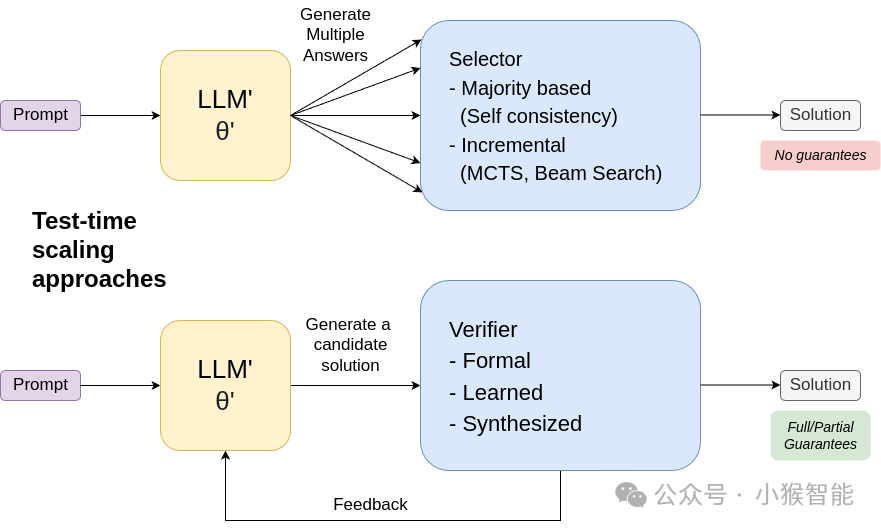
Figure 1:Test-time scaling approaches for teasing out reasoning
核心思想:在推理(回答用户问题)时,让模型做比“直接生成答案”更多的工作,相当于在测试时进行可扩展的、问题自适应的计算。
关键过程:
(1)生成:使用LLM为同一个问题生成多个候选答案或解轨迹。
(2)验证/选择:通过某种机制筛选出最优答案。
2.1)简单选择:如“自我一致性”,选择出现频率最高的答案(假设模型误差是随机的)。
2.2)验证驱动:引入“验证器”对候选答案进行检验。这是性能提升的关键。
验证器类型:
(a)外部可靠验证器:使用传统求解器或可证明正确的程序(如数学计算器、规划器)。这是最可靠的方式,能提供正确性保证(如LLM-Modulo框架)。
(b)学习型验证器:训练另一个模型来判断答案正确性(问题:验证器也可能出错)。
(c)LLM自我验证:让LLM自我评估(已被证明存在问题,容易产生过度自信)。
迭代改进:如果验证失败,可以将错误信息反馈给生成器,让其重新生成,形成“生成-测试-修正”循环。
核心见解: 这本质上是将搜索或规划过程外包给了测试时的计算循环,而非内化于模型权重中。
根本问题:成本爆炸。计算成本不再与输出长度成正比,而是与问题的内在计算复杂度成正比,颠覆了LLM按token计费的传统商业模式。
2. 训练后方法(基于推导轨迹,Post-Training on Derivational Traces)
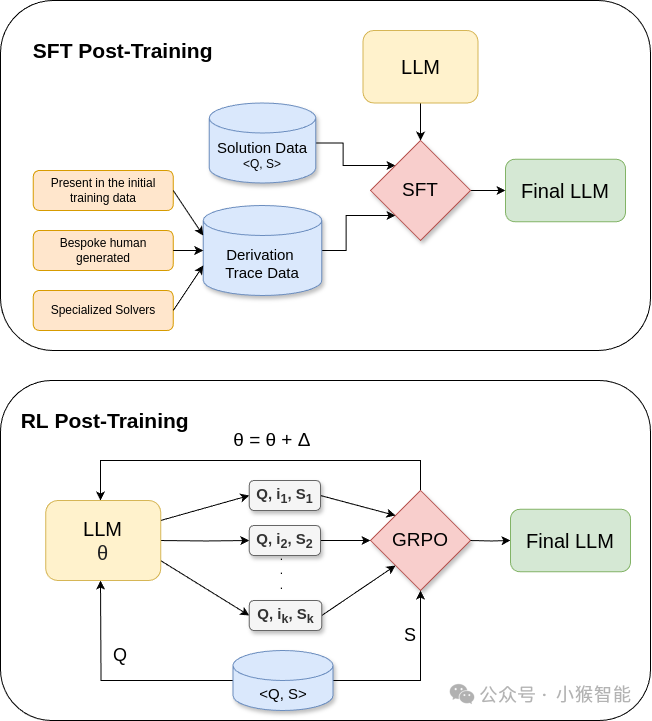
Figure 2:Post-training Approaches for teasing out reasoning
核心思想:在标准预训练后,使用包含“解题步骤”(推导轨迹)的数据对模型进行进一步训练,教会模型在输出答案前,先输出类似的中间步骤。
关键过程:
(1)轨迹数据获取(最大难点):
1)人工标注:高质量但代价极高(如GSM8K数据集)。
2)合成生成:使用传统求解器(如A*搜索)自动生成问题解及其完整的搜索轨迹(如SearchFormer)。轨迹准确但领域受限。
3)LLM生成后过滤:让LLM自己生成步骤(利用其预训练中已有的“步骤示范”数据),然后通过验证器过滤出最终答案正确的轨迹(无论中间步骤是否真正合理)。这是当前主流方法。
模型训练:
(1)监督微调:直接在(问题,推导轨迹,答案)数据上微调。
(2)强化学习:更先进的方法(如DeepSeek R1)。
2.1)过程:对于可验证的问题,让模型生成多条带“痕迹”的答案。
2.2)奖励:仅根据最终答案的正确与否给予奖励/惩罚。
2.3)效果:模型参数被调整,使得能导致正确答案的输出模式(包括其前面的“痕迹”)概率增大。
2.4)知识蒸馏:将经过RL训练的“教师模型”的输出作为数据,去训练一个更小的“学生模型”,可以免去昂贵的RL过程。
(3)核心见解:
痕迹的语义虚假性:训练目标只关心最终答案正确。模型学会的是一种能“讨好”奖励信号的输出格式(先输出一堆token,然后输出答案),这些中间token不一定构成逻辑推理,而可能是任何有助于提高最终答案正确率的模式。
本质是编译验证信号:该过程可以理解为将外部验证器(在训练时使用)的“测试”能力,部分地编译到了生成模型的“生成”倾向中。即“智能是将‘生成-测试’中的测试部分转移到生成部分”(明斯基)。
三、对LRM的批判性见解(打破误解)
1. 中间token不是“思考痕迹”
模型生成的“让我们一步步思考…”等文本,是对预训练数据中人类解题风格的模仿,而非内部计算过程的反映。作者戏称为“大型喃喃自语模型”。
证据:即使在专门训练输出求解器轨迹的模型(如SearchFormer)中,其输出的“步骤”也常包含违反基本算法规则的操作(如从开放列表中删除不存在的节点),但这些错误轨迹有时仍能“蒙对”最终答案。这说明轨迹的正确性并非必要。
2. 性能提升的来源是“提示增强”,而非获得推理能力:
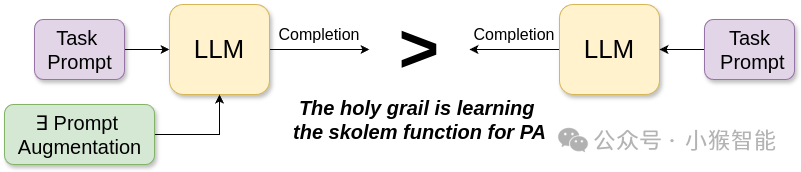
Figure 4: Augmenting a task prompt with additional tokens often seems to improve the accuracy of LLM completion even if the tokens don’t have human-parseable meaning.
给LLM一个更长的、特定格式的提示词(如包含“步骤”),即使这些附加token对人类毫无意义,也能提高其答案准确性。
LRM的训练后方法,实质上是将这种有效的“提示增强”动态地、内化地置于每次生成的开头。模型学会了自己为自己“铺垫”一段有利于解题的上下文。
3. 泛化能力脆弱
在简单规划任务(Blocksworld)上表现尚可,但一旦对对象和动作进行重命名(Mystery Blocksworld),性能就大幅下降。这表明模型严重依赖表面词汇的匹配,而非抽象的逻辑结构理解。
面对不可解问题时,LRM会自信地生成虚假计划并配上看似合理的解释,存在“ gas lighting ”(误导)用户的风险。
4. 与LLMs没有根本性架构区别
仅经过训练后的LRMs,在推理时仍然是接收提示,自回归地生成token。其架构与普通LLM完全相同。
唯一改变的是模型输出token序列的概率分布:它现在更倾向于先生成一段“类推导痕迹”的token,再生成答案。没有自适应计算,生成长度在训练时已大致确定。
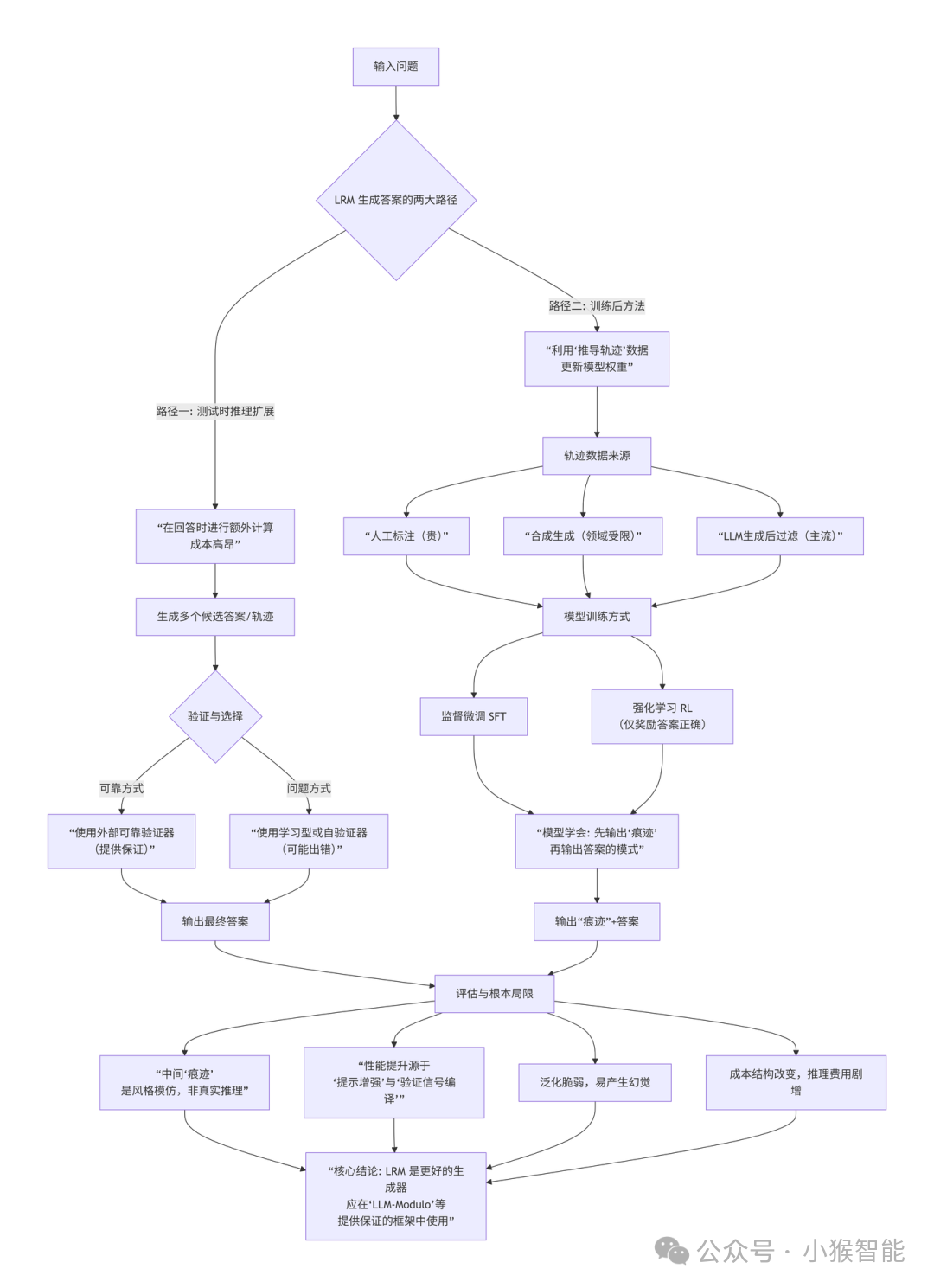
四、核心流程图解:LRMs的工作原理与本质
以下图表概括了上述所有关键过程和见解:
五、未来方向与建议
去拟人化:放弃让中间token像人类“思考”,转而探索高效、压缩、符号化的中间表示,纯粹以提升最终准确性为目标进行优化(类似AlphaZero学习价值函数)。
混合系统定位:LRMs不应被视为独立的“推理者”,而应作为增强型的提议生成器,集成在如LLM-Modulo的框架中,由外部验证器提供可靠性保证。
重新审视评估:需要超越最终答案准确率的基准测试,设计能测评推理过程稳健性、泛化性和成本效率的评估体系。
总而言之,本文揭示了LRMs“推理”能力背后的工程本质,对其过度拟人化的解读提出了有力批判,并为更稳健、可靠的AI系统设计指明了方向。
本文转自:小猴智能,由小猴翻译校对
源文:(How) Do Reasoning Models Reason?2025.4.14
-
测试
+关注
关注
9文章
6509浏览量
131793 -
LLM
+关注
关注
1文章
351浏览量
1412
发布评论请先 登录
从显存瓶颈到推理革命:vLLM 为何成为大模型服务的底层标配

是德科技如何评估AI推理基础设施的性能

商汤科技正式开源多模态自主推理模型SenseNova-MARS

商汤开源SenseNova-MARS:突破多模态搜索推理天花板
阿里巴巴发布通义千问旗舰推理模型Qwen3-Max-Thinking

基于NVIDIA Alpamayo构建具备推理能力的辅助驾驶汽车
NVIDIA TensorRT LLM 1.0推理框架正式上线
什么是AI模型的推理能力
NVIDIA Nemotron Nano 2推理模型发布

澎峰科技完成OpenAI最新开源推理模型适配
利用NVIDIA推理模型构建AI智能体




评论