 VLA模型是基于预置规则来指导行动吗?
VLA模型是基于预置规则来指导行动吗?

[首发于智驾最前沿微信公众号]今天继续来回答小伙伴的提问,最近有一位小伙伴提问,VLA模型中的理解是不是也基于一些预置的规则指导行动的?其实这个问题非常值得讨论,今天智驾最前沿就带大家详细聊一聊。
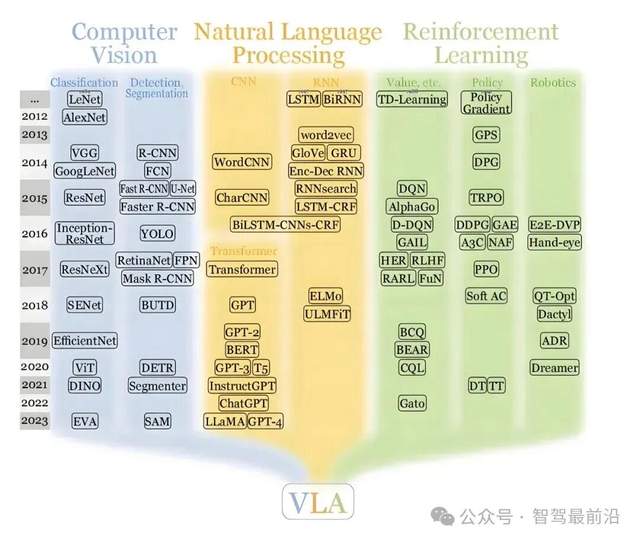
视觉-语言-动作(VLA)模型是什么?
在讲今天的内容之前,要先把VLA讲清楚。视觉-语言-动作模型(Vision-Language-Action Model,简称VLA)是近年来机器人和人工智能领域兴起的一类模型。它的目标是让一台机器“看懂世界”、“理解任务指令”,然后自己去执行动作。
图片源自:网络
举个例子,一台机器人面对一个装满玩具的桌子,你用语言告诉它“把红色球放进盒子里”,它就需要先“看见”桌子上的东西,分辨出哪个是红色球和盒子;然后它要理解你说的这句话的意思;最后它得控制自己的机械臂抓起球并放到指定位置。VLA模型的意义就在于把这三个任务整合起来,而不是像传统机械那样把每个步骤拆开做。
一个典型的VLA模型会包括两个核心部分,一个是视觉-语言编码器(Vision-Language Encoder),负责把图像和语言输入映射成机器内部可以处理的表示;另一个是动作解码器(Action Decoder),负责根据这种内部表示生成具体执行动作的命令。这样的架构可以在一次前向计算中把视觉信息和语言指令结合起来,直接输出机械动作或控制信号。
之所以会提出VLA模型,是因为传统机器人系统会将视觉感知、语言理解和动作规划拆成不同模块,这种模块化系统在复杂环境下很难协同,而且对场景变化的适应性较差。VLA模型的端到端方法试图让感知、理解和行动融成一个整体,从而具备更自然、更接近人类操作的能力。

VLA模型里所谓的“理解”到底是什么?
很多人听到AI具备“理解能力”,就会自然而然联想到传统程序里如“如果看到红色球,就执行抓取动作”这样的规则判断。这种规则式的思考可以让行为动作有据可循,但VLA模型的理解并不是这种有明确规则的程序逻辑。恰恰相反,它没有预定义的、用编程手写的规则来指导每一次动作如何执行。它的理解来自于大量示例学习出来的关联模式。
换句话说,VLA模型的“理解”不是提前写好的指令集,而是一种端到端学习得到的内部能力。在训练阶段,模型会被喂入大规模的训练数据,这些数据是由很多真实或模拟场景组成的三元组,即视觉输入+自然语言指令+与之对应的动作轨迹。如在数据里可能有这样的记录,“图像是桌面场景,语言是把杯子放进箱子,动作序列是机械手臂移动并完成抓取动作”。模型通过反复“看见+读懂+对比正确动作”这样的样本,逐渐学习出视觉特征、语言表征和动作输出之间的统计关系。
这种学习是统计意义上的,而不是逻辑规则式的。模型并没有一个明确的代码告诉它“红色就是要抓取”,它只是从数据里看到在大量场景中,当出现“红色球”和相关指令时,执行某些动作是合适的。
从这个角度看,“理解”在VLA中更像是一种统计上的推断能力,模型不是在判断一个明确的规则是否满足,而是在根据它已经学到的多模态关联进行预测。理解语言成分时,就类似人类语言模型的方式;理解视觉信息时,责利用视觉编码器提取场景特征;动作的输出则是在学习中形成的概率式策略。这种能力的组成是多种网络层结构和训练方法协同的结果,而不是单个模块的规则引擎决定的。
VLA模型内部是怎么做到“理解”的?
为了更清楚地解释VLA模型内部“理解”是怎么发生的,可以把VLA模型拆成几个部分来简单理解。
在视觉模块,计算机视觉网络会把摄像头捕获的画面转换成一组高维特征,这些特征描述了场景里物体的位置、颜色、形状等信息,而且这种转换过程不是通过预定义规则实现的,而是通过视觉编码器(比如Transformer或深度学习某些架构)学习得到的。这些视觉编码器能够把像素转换成更抽象、对任务有意义的表示,这是一种由数据学习出来的视觉理解能力。
语言模块和现在流行的大语言模型类似,它会把自然语言指令转换成机器内部可以处理的语义向量。语言模块并不把指令拆成明确步骤,而是把语言映射成一种语义空间表示,在这个表示里任务目标、动作意图等信息可以被进一步处理。这样的语言编码能力本身也是从大量文本和指令数据中学习出来的。
在视觉和语言的编码结果都转化成内部表示之后,模型内部有一个融合层或者共同的潜在空间表示,它把两种不同模态的表示合并起来,使视觉信息和语言目标能够结合成一个综合的表示。在这一层,模型学习到视觉场景中的哪些对象和语义指令相关联。就拿前文中机器人拿红球的例子来简单理解下,如果语言里提到了“红色球”,视觉编码器的特征里有一种与红色物体相关的高维向量,模型就会将它们关联起来。
融合后的内部表示会传到动作解码器,这一步负责将综合表达转化成具体的动作命令。动作解码器的输出可以是机器人关节的控制信号、路径规划参数等。在训练时模型已经见过大量这样的输入—输出对,所以它能学会在给定视觉和语言条件下如何输出正确动作。这样的输出并不是由预设规则决定的,而是由模型内部网络结构和权重计算得到的最优动作预测。
上面说的整个过程看上去像一个黑箱,输入是一张图像和一句话,输出是一组动作命令,中间有大量的矩阵乘法和非线性变换在发生,而这些都是统计学习得到的映射关系。
最后的话
回到最初的问题,VLA模型里的理解是不是基于一些预置的规则来指导行动?
答案是:不是。VLA模型内部不依赖传统意义上的预先写好的规则。它的理解和动作生成能力来自于对大量视觉—语言—动作示例的学习过程。在学习结束后,模型能在看到新的图像和语言指令时,通过内部的潜在空间表示和映射关系生成合理的动作输出,这种能力更像是一种通过数据训练出来的模式匹配和策略生成能力,而不是靠写好的规则集合。
这样的设计让VLA模型具备了更强的泛化能力和适应性,但同时也意味着它不像规则驱动系统那样容易解释或明确验证。这种“学习出来的理解”是一种统计形式的能力,这类模型有望在更多复杂任务中表现得越来越像我们所理解的“智能体”。
审核编辑 黄宇
-
模型
+关注
关注
1文章
3816浏览量
52265 -
Vla
+关注
关注
0文章
22浏览量
5915
发布评论请先 登录
2500 TOPS!特斯拉HW5智驾算力怪兽突击,国产VLA火速进化
小鹏发布 X-World 世界模型:已全面应用第二代VLA
Nullmax VLA算法深度赋能黑芝麻智能华山A2000芯片
黑芝麻智能华山A2000芯片与Nullmax VLA算法完成深度适配
全球首车搭载元戎启行VLA模型,魏牌蓝山智能进阶版重磅上市

VLA与世界模型有什么不同?

NVIDIA推动面向数字与物理AI的开源模型发展
VLA能解决自动驾驶中的哪些问题?
VLA和世界模型,谁才是自动驾驶的最优解?
自动驾驶上常提的VLA与世界模型有什么区别?
量产交付超10万辆!元戎启行携DeepRoute IO 2.0平台及VLA模型亮相德国IAA

基于大规模人类操作数据预训练的VLA模型H-RDT

VLA,是完全自动驾驶的必经之路?
元戎启行周光:VLA模型将于2025年第三季度量产




评论