 VLA和世界模型,谁才是自动驾驶的最优解?
VLA和世界模型,谁才是自动驾驶的最优解?

[首发于智驾最前沿微信公众号]随着自动驾驶技术发展,其实现路径也呈现出两种趋势,一边是以理想、小鹏、小米为代表的VLA(视觉—语言—行动)模型路线;另一边则是以华为、蔚来为主导的世界模型(World Model)路线,这两种路径都为自动驾驶快速落地提供了可能,那谁才是最优解?
什么是VLA模型?
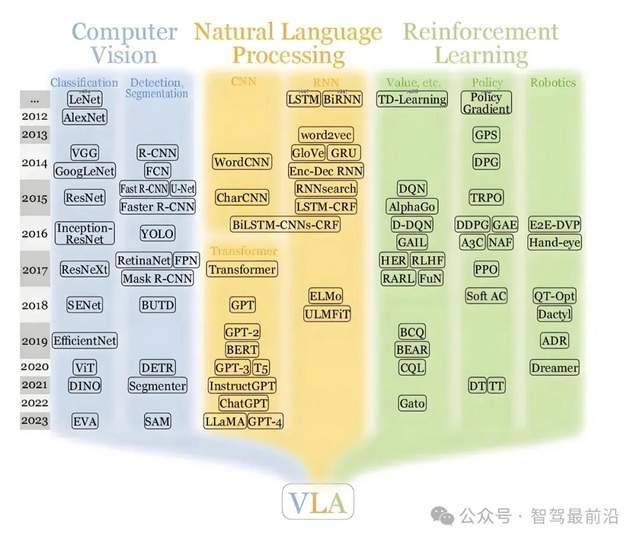
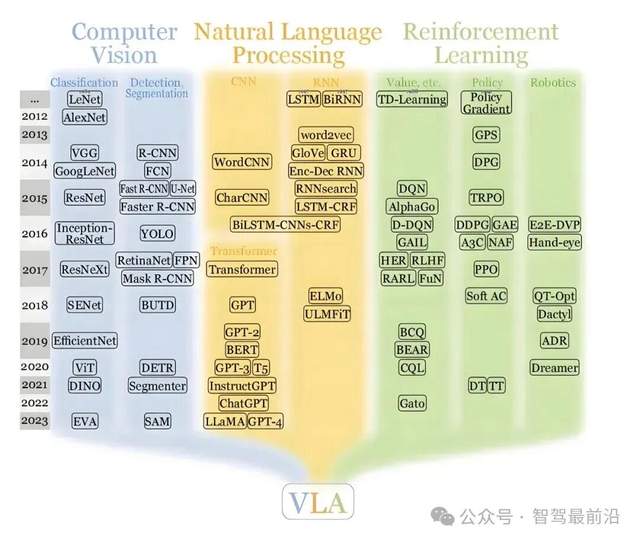
VLA模型,即视觉—语言—行动模型,是将视觉感知、语言理解和动作生成串联起来的一套方法。它先是通过视觉编码器,将摄像头看到的画面转换成语义丰富的特征向量,像是SigLIP、Dino V2/V3等这类模型就是用于完成这项任务的。这些视觉特征会被“翻译”成一种类似语言的表征单元(token),并将其送入一个大型语言模型(LLM)中。LLM经过多模态改造后,其任务不再只是生成文本,而是能够基于这些视觉信息进行如分析车道线的状况、预判前方行人的意图、或者评估不同驾驶策略的合理性等更高层次的语义推理。LLM的推理结果会被转化为例像是轨迹和速度,从而驱动车辆执行等具体的控制指令。
图片源自:网络
从理论上看,VLA还是比较难以理解的,通俗理解下就是,VLA是让车辆先用语言描述清楚眼睛看到了什么,再用语言进行思考,最后把思考结果转化为行动。这种方法的优势在于,语言层面天然适合进行抽象和长时序推理,也便于整合上下文信息和规则知识,这使得从感知到决策的桥梁可以建立在更明确、更具可迁移性的语义表示之上。
因为语言模型擅长将零散信息组合成高层结论,VLA在遇到多种复杂场景时,理论上能更容易进行“概念化”的判断,同时也更容易将人类规则、法规或场景说明以文本形式融入到训练与调优流程中。
当然,想将视觉特征可靠地转换为LLM能够有效利用的token并不容易,有很多问题需要解决。视觉与语言之间的信息损失和对齐问题是一定要解决的;语言推理产生的结论也需要被严格约束在物理可行的动作范围内,否则就可能出现“想法很好”但“执行不安全”的情况。此外,LLM的推理开销、系统实时性以及决策的可解释性等都是需要解决的问题。虽然语言的抽象能力很强,但物理世界对控制精度和约束的要求极高,如何在语义抽象与精确控制之间建立可信赖的映射,更是VLA需要去攻克的。
VLA的优势在于其强大的语义理解能力,对复杂的社交互动和规则理解有天然优势,适合用较少的显式规则去捕捉场景中的行为意图。对于那些希望利用“数据和模型”将驾驶经验迁移到不同车型、不同城市的厂商而言,VLA的通用性和抽象能力是非常有吸引力的。其短板在于,对物理精度和安全约束的保障需要额外的工程手段,且其推理延迟、模型可解释性和系统验证的难度都相对更高。

什么是世界模型路线
世界模型的核心思想,是把环境、物体和行为都建模成一个可计算、可推演的“物理世界”,决策不用借助自然语言作为中介,可以直接在状态空间中进行。世界模型强调“空间认知与物理推演”,它从多传感器数据出发,能构建一个连续、可预测的世界状态表示,并基于物理规则进行行为生成与验证。
以华为WEWA的“云端与本地协同”模式为例,团队可以在云端构建高保真的物理仿真环境,让模型在虚拟世界中不断“驾驶”并生成海量的仿真轨迹。仿真环境能提供极高的数据密度,模型可以在大量受控的、甚至是极端的场景中学习物理世界的因果关系。通过一套对模型生成行为进行打分的奖惩机制,模型可以逐渐学会在各种情境下如何规避风险,并做出合规且稳定的决策。

华为WEWA技术架构,图片源自:网络
训练完成后,通过模型蒸馏或压缩技术,将复杂的云端模型转化为能在车端实时运行的轻量版本,使得车辆能够根据实时传感器数据直接生成轨迹与控制命令。
世界模型的优势在于其出色的可控性和物理一致性。因为决策是建立在明确的、可验证的状态与动力学模型之上,所以更容易进行形式化验证、安全边界检查以及物理约束的强制执行。这对于安全关键场景的可解释性和可证伪性也更为有利。由于采用的是仿真训练,可以人为创造现实中罕见但对安全至关重要的极端场景,能有效弥补真实道路采集数据的不足,从而提升系统在危险情况下的鲁棒性。
与VLA模型一样,世界模型技术路线也有很多问题需要解决。高保真仿真、复杂动力学建模以及对自车与环境的精确重建,都需要庞大的算力支撑与成本投入,这将是一笔非常大的开销。对于如何构建足够多样化的仿真环境以覆盖现实世界的复杂性,并有效弥合“仿真与现实之间的迁移鸿沟”,也是一个需要解决的问题。此外,该路线对感知传感器的类型与精度存在较高依赖性,若采用以激光雷达为核心的方案,将直接让系统成本与部署门槛直接提升,进而会影响其规模化落地的进程。
世界模型的优势在于其决策结果更接近真实的物理世界,易于注入约束并进行形式化的检验,仿真训练能够高效覆盖各类风险场景,适合对安全性要求极高的产品化路径。其短板在于仿真与现实的差距难以完全消除、系统建模复杂,以及对高精度传感器的依赖可能推高整体成本。此外,在某些需要“常识”或长时序社会推理的场景下,纯物理规则驱动的模型可能不如引入语言中介的模型那样灵活和直观。
两条路线的核心差异
将两条路线进行比较,会发现它们在“世界如何表示”、“决策如何形成”、“训练数据来源”以及“部署策略”这几个维度上是完全不同的。
对于世界如何表示的问题上,VLA倾向于用语义化的token来表达世界,突出抽象概念和高层意图,这种表示方式便于将人类知识和规则以语言形式注入系统;而世界模型则将世界表示为连续的状态变量和实体间的空间关系,更强调几何属性、动力学与可预测性。
在推理机制上,VLA依赖大语言模型的语义推理能力,擅长处理长时序依赖和复杂上下文的综合判断,但需要将语言结论映射到具体动作,并确保其满足物理约束;世界模型则直接在状态空间进行物理推演和策略生成,其推理过程更贴近物理规律,结果通常更易于验证,但在处理语义模糊、规则解释或长时序社会行为推断时,灵活性可能不如前者。
两者训练数据的来源也有明显差异。VLA更依赖大量经过标注的多模态数据、真实道路场景数据,以及用于对齐的语言数据;世界模型则重度依赖高质量的仿真数据以及多传感器融合的真实驾驶日志,仿真数据在数据量和场景可控性上占据明显优势。
两者在部署策略上也各有侧重。VLA需要更复杂的模型栈来完成从视觉到语言再到控制的完整映射,LLM带来的推理开销和实时性要求会影响其在车端的直接应用,因此很多技术方案中会采用轻量化、模型蒸馏或分层决策的方式,将高层规划放在云端或开发阶段,而将受严格约束的执行模块部署在车端。世界模型的“云端仿真训练、车端模型蒸馏”流程则更为直接,将仿真中学到的策略压缩后运行在车端,车端系统可以根据实时感知直接进行物理层面的决策。
最后的话
将VLA和世界模型放在一起比较,会发现它们各有专长,也各有局限,如果要给出谁更具优势的结论,或许会很难。未来,VLA与世界模型或将走向深度融合的方向,VLA作为感知与决策的“大脑”,负责理解复杂场景与高层规划;世界模型则成为控制与执行的“小脑”,确保所有动作均符合物理规律与安全边界。
审核编辑 黄宇
-
Vla
+关注
关注
0文章
25浏览量
5921 -
自动驾驶
+关注
关注
795文章
15061浏览量
182017
发布评论请先 登录
小米正式发布并全面开源自动驾驶模型Xiaomi OneVL
小鹏发布 X-World 世界模型:已全面应用第二代VLA
理想汽车发布下一代自动驾驶基础模型MindVLA-o1

如何构建适合自动驾驶的世界模型?

2026年,3DGS和世界模型,在自动驾驶仿真中的组合应用

已有VLM,自动驾驶为什么还要探索VLA?
黄仁勋:未来十年很多汽车是自动驾驶 英伟达发布Alpamayo汽车大模型平台
VLA与世界模型有什么不同?

世界模型是让自动驾驶汽车理解世界还是预测未来?

VLA能解决自动驾驶中的哪些问题?
PLC vs 嵌入式:谁才是工业场景的“最优解”?

自动驾驶上常提的VLA与世界模型有什么区别?
自动驾驶中常提的世界模型是个啥?



评论