 VLA与世界模型,会让自动驾驶汽车走多远?
VLA与世界模型,会让自动驾驶汽车走多远?

[首发于智驾最前沿微信公众号]在一个雨夜的十字路口,你开车行驶到路中央,前方是一辆犹豫不决的电动车,左侧有一台打着转向灯的出租车,右后方突然闪过一束远光灯。这时候你会怎么做?经验丰富的司机往往会迅速分析,电动车可能突然横穿,出租车大概率要并线,后车逼得太紧不能急刹,最稳妥的办法是先减速,给前后左右都留出余地。看似几秒钟的决定,实际上包含了感知、预测、推理和取舍。
可如果把同样的场景交给自动驾驶呢?传统的系统更多是基于规则和简单预测,它能看见电动车、检测出租车、识别远光灯,却未必能像人类一样“想明白”这些信号背后的意图和逻辑。于是,车子要么显得过度保守停在原地,要么冒进地冲出去,最终都和人类驾驶的直觉一定会有差距。也正因为如此,行业开始追问,能不能让车也拥有“理解和推理”的能力?答案正是近年来兴起的VLA(视觉—语言—动作模型)和世界模型。
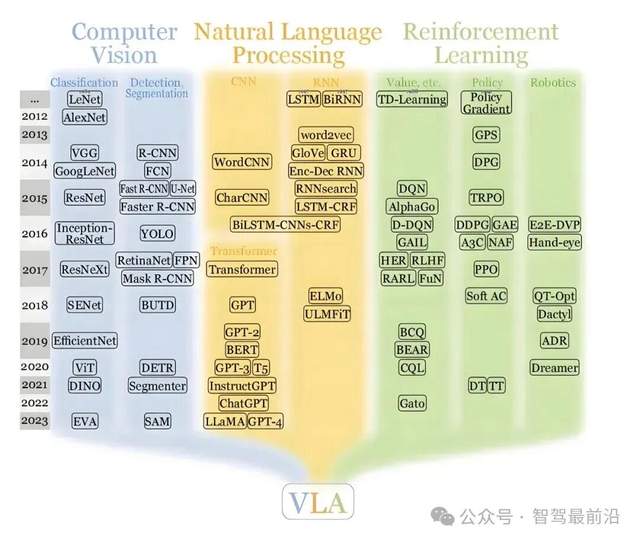
其实过去十年,自动驾驶的发展像坐过山车一样起伏。早期技术方案觉得靠感知、预测、规划、控制的模块化体系,把规则写全,把数据堆够,就能让汽车自动开起来。但随着项目规模扩大,越来越多从业者意识到,这套方法天然有天花板。模块化的链条太长,每个环节之间的信息丢失严重,人工接口让系统难以联合优化,即使投入海量人力,也难以覆盖长尾复杂场景。VLA和世界模型的出现,让车子不只是“执行规则”,而是像人一样“理解和推理”。
VLA的逻辑:从“会看”到“会想”
VLA的本质是把自动驾驶从单纯的数据驱动,逐步引向知识驱动。过去的端到端尝试大多直接把图像输入和车辆动作输出绑定在一起,中间缺乏解释能力。而VLA则引入了多模态大模型的优势,把视觉、点云、地图、传感器信息都编码进一个统一的语义空间,再通过语言模型来进行逻辑推理和高层决策。换句话说,它让车不只是会“看”,更会“想”。视觉编码器负责从图像或点云中提取特征,对齐模块把这些特征映射到语言空间,语言模型则像人脑的“推理区”,根据上下文和逻辑得出结论,最后生成器把这种高层意图转换成车辆可以执行的轨迹或动作。可以说,VLA就是把人类驾驶的认知流程,第一次较完整地搬进了机器世界。
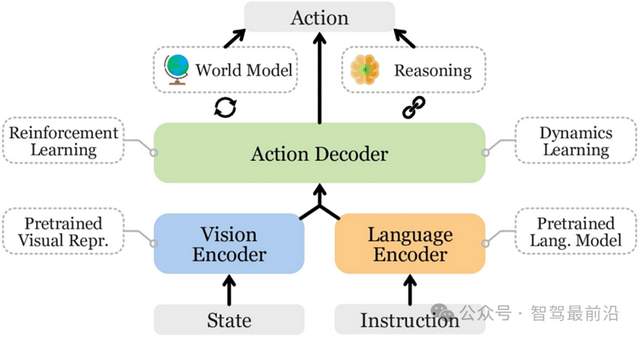
VLA模型的总体架构,包含编码器、解码器和输出动作
要让VLA真正工作起来,有三块技术难点是绕不开的。首先是三维特征的表达。车面对的是一个三维世界,二维的图像信息远远不够。近年来被频繁提到的3D Gaussian Splatting技术,正是为了解决这一问题。它用一系列高斯分布来显式表示三维点,不仅比传统的体素网格节省算力,还能达到实时渲染的水平。相比之下,像NeRF那样的隐式场景表示虽然能渲染得极其逼真,但计算量过大,几乎不可能放在车端使用。3D GS在效率和真实感之间找到了平衡,因此被很多团队作为中间特征的候选方案。不过,它也有短板,比如对初始点云的质量非常依赖,这意味着在采集数据阶段就要保证精度,否则渲染结果会受到较大影响。但从整体趋势来看,3D GS已经成为让车能更“立体”地理解世界的重要一步。
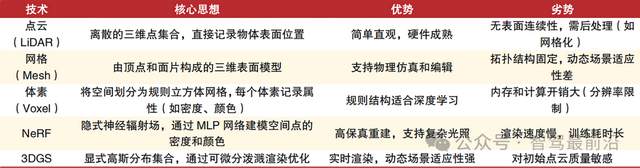
3D GS与其余三维重建技术的区别
第二个难点是记忆与长时序推理。驾驶是一项连续任务,不是单帧的反应动作。车需要记住前方几秒钟的交通参与者行为,才能判断对方是要超车、掉头还是直行。然而传统Transformer在处理长序列时开销太大,窗口一旦超过几千步,计算就变得不可承受,同时信息还容易被稀释掉。为了解决这个问题,有技术引入了稀疏注意力和动态记忆模块。稀疏注意力通过只关注关键位置,显著降低了计算复杂度,而动态记忆则像外挂的存储器,把历史中的关键信息提取、保存,在需要时重新调出。这种方式让模型既能处理长时依赖,又不会在车端算力有限的环境下崩溃。像是小米的QT-Former就在长时记忆上做了优化,理想的Mind架构同样在探索类似的思路,说明这已经成了产业界的共识。
小米QT-Former模型架构
第三个难点是推理效率。车端的算力和功耗都有限,不可能像云端一样无限堆GPU。于是量化、蒸馏、裁剪等传统模型压缩手段,成了落地必备。理想采用GPTQ等后训练量化方法,把大模型缩小到能实时运行的程度,同时探索混合专家模型MOE,通过只激活部分专家的方式来减少开销。这样的架构既能保持大模型的能力,又不会让推理速度拖慢整个系统。智驾最前沿以为,未来车端的大模型必然是“稀疏+量化”的形态,否则在能耗和成本上都不现实。

世界模型:虚拟世界里的试炼场
如果说VLA是车子的“大脑”,那么世界模型就是它的“训练场”。因为现实世界的数据再多,也不可能覆盖所有情况,更不能无限试错。高保真的世界模型能生成各种道路场景,补充长尾数据,还能提供一个低成本、安全的闭环环境,让模型在虚拟世界里反复学习。理想的DriveDreamer4D就是一个典型案例,它能生成新轨迹视频并和真实数据对齐,用来扩展数据集;ReconDreamer则通过渐进式数据更新来减少长距离生成里的假象;OLiDM针对激光雷达数据稀缺的问题,用扩散模型来生成点云。这些名字看起来很学术,但本质上都是在做一件事,用虚拟的方式去还原真实世界的复杂性,让模型提前适应未来可能遇到的情况。
在训练范式上,VLA和世界模型也发生了很多变化。过去大家依赖行为克隆,即让模型模仿人类驾驶,但这种方法在遇到没见过的情况时往往会失效。现在更多采用三阶段闭环,先用行为克隆做起步,保证模型有个基础,再用逆强化学习从专家数据中学习奖励函数,最后通过世界模型里的强化学习不断迭代优化。这种方式让模型不仅会模仿,还能自己探索更优解,逐渐超越人类示范的水平。
产业视角:车企为何抢跑?
把大语言模型放到自动驾驶里并不是把车变成聊天机器人那么简单。VLA的核心在于“多模态”和“动作生成”,视觉编码器要能把图像、视频、甚至点云编码成对语言友好的中间表示;对齐模块要把这些视觉表示映射到语言空间;语言模型承担长时的推理和决策;解码器则把高层意图细化成车辆可执行的低层动作或者轨迹。其实汽车的任务比较单一,就是开车,场景也相对有规则,道路标线、交通灯、车辆行为都有明确约束。再加上车企自带海量车队和数据收集能力,这使得VLA更容易在车上形成规模效应。这也是为什么国内外厂商纷纷入局的原因。Waymo早期推出了EMMA系统,算是奠定了方向;国内理想正在构建完整的Mind架构,小米在量产车中测试QT-Former,小鹏在尝试端到端引入大模型,华为则在MDC平台上为未来预留了大模型接口。不同公司路线各异,但目标是一致的,让车子具备更强的理解和推理能力。
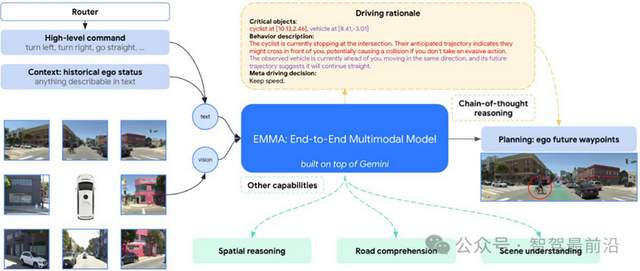
EMMA模型架构
写在最后
总的来说,VLA与世界模型的结合,标志着自动驾驶正在经历一次认知层面的升级。它们不仅仅是算法改良,而是范式的转变,从“能看会开”走向“能想会推理”。这条路当然不轻松,三维表征、记忆机制、算力约束和仿真保真度,每一项都是难题。但随着架构逐步成熟、世界模型越来越逼真、闭环训练越发完善,我们有理由相信,未来的自动驾驶不只是冷冰冰的感知与控制机器,而是一个能理解环境、能解释行为、能与人类逻辑对接的“驾驶智能体”。谁能最先把这些技术变成大规模落地的体验,谁就能在下一阶段的竞争中拔得头筹。
审核编辑 黄宇
-
Vla
+关注
关注
0文章
29浏览量
5929 -
自动驾驶
+关注
关注
795文章
15102浏览量
182283
发布评论请先 登录
视觉语言动作模型(VLA)为何能让自动驾驶理解世界?

VLA与世界模型哪个更适合自动驾驶?为什么车企会有不同选择?

小米正式发布并全面开源自动驾驶模型Xiaomi OneVL
小鹏发布 X-World 世界模型:已全面应用第二代VLA
理想汽车发布下一代自动驾驶基础模型MindVLA-o1


强化学习会让自动驾驶模型学习更快吗?

黄仁勋:未来十年很多汽车是自动驾驶 英伟达发布Alpamayo汽车大模型平台
VLA与世界模型有什么不同?

世界模型是让自动驾驶汽车理解世界还是预测未来?

VLA能解决自动驾驶中的哪些问题?
VLA和世界模型,谁才是自动驾驶的最优解?
自动驾驶上常提的VLA与世界模型有什么区别?
自动驾驶中常提的世界模型是个啥?



评论