 VLA与世界模型哪个更适合自动驾驶?为什么车企会有不同选择?
VLA与世界模型哪个更适合自动驾驶?为什么车企会有不同选择?

[首发于智驾最前沿微信公众号]在自动驾驶快速发展的当下,世界模型与VLA成为两大主流技术,虽然它们都属于现在流行的大模型技术范畴,也都在为实现更高级别的无人驾驶出力,但它们在车里扮演的角色和思考问题的逻辑是完全不同的。那他们之间有什么区别?为什么车企会有不同选择?

为什么车需要一个世界模型?
在传统的算法里,车只是在被动地接收雷达和摄像头传回来的数据,然后根据写好的逻辑去判断该刹车还是该转弯。而世界模型就像是给自动驾驶系统装上了一个模拟器,它的核心在于预测,其不仅能看到现在发生了什么,更在乎下一秒会发生什么。它通过大量视频数据的学习,掌握了物理世界的运行规律。李飞飞教授就曾在《金融时报》专访中指出,缺乏空间理解的AI是不完整的,必须构建能感知三维环境、理解物理规律的世界模型,让AI具备类似人类的空间认知能力。

图片源自:网络
自动驾驶行业在这个方面其实很早就布局了,英国自动驾驶公司Wayve在2023年就推出了生成式世界模型GAIA-1,经过持续优化,该模型最终扩展至90亿参数,使用4700小时在伦敦采集的真实驾驶数据完成训练,能够根据视频、文本和动作输入生成逼真的驾驶场景。
特斯拉也于2025年发布了基于神经网络的世界模拟器,一个为其FSD和擎天柱机器人项目打造的逼真虚拟训练场。据特斯拉自动驾驶副总裁Ashok Elluswamy介绍,该系统能让AI在一天内学习相当于人类500年的驾驶经验,可一次性生成长达6分钟、覆盖8个摄像头的逼真驾驶视频,大幅降低了对真实路测的依赖。
世界模型还能让车在脑子里复现出周围环境的演变过程,Wayve的GAIA-1就是一个典型的例子,它通过学习海量驾驶视频,不仅能够理解车辆、行人、交通标志等各类交通要素,还能生成物理上合理、视觉上逼真的未来场景,甚至在训练中表现出与大语言模型类似的规模效应,即模型越大、数据越多,预测能力越强。
如当车看到路边有一个正在弹跳的皮球时,世界模型会基于它对物理世界的理解,预测出皮球后方极大概率会出现一个跑出来捡球的孩子。这种预测并不是靠人写进去的代码,而是模型在看过无数段交通视频后,自己悟出来的因果关系。它通过预测未来的图像或状态,可以帮助驾驶系统提前做出反应,而不至于等到危险真的出现在视野里才急刹车。
特斯拉的世界模拟器在实践中就体现了这种能力,它不仅可以在虚拟环境中重现历史上的危险场景并探索不同的应对策略,还能主动创造现实中极为罕见的长尾场景和对抗性测试,帮助AI在安全环境中应对各种极端情况。
从技术实现的角度看,世界模型更像是一个时空环境的建模工具。它负责把复杂的交通环境、天气变化、行人轨迹等信息,转化成一种可以预测的内部表达。如果把自动驾驶比作一个驾驶员,世界模型提供的就是一种预判能力,让车知道在当前的物理环境下,各种物体的运动趋势是怎样的。这种能力对于处理一些罕见的、突发的危险情况尤为重要,因为它能让系统在事情发生前就对潜在风险有所觉察。

语言能力如何让车更聪明?
说完世界模型,我们再来看看VLA,也就是视觉-语言-动作模型。顾名思义,它在视觉和动作之间加入了一个非常关键的中间层,即语言。很多人可能会觉得奇怪,车又不用开口说话,为什么要学语言?其实,这里的语言代表的是一种逻辑推理和常识理解能力。现在的VLA模型大多是把大语言模型作为大脑的核心,让它来指挥车怎么开。

图片源自:网络
事实上,VLA正成为智能驾驶领域公认的下一代核心技术,理想汽车、小鹏汽车、长城汽车等国内主流车企都已加入VLA阵营,其中理想率先量产VLA模型,实现了读懂路面文字与交警手势的能力。
有了语言模型的加入,自动驾驶系统就不再只是处理像素和坐标,而是在处理概念。当车在路口看到一辆打着双闪的物流车停在路边时,普通的系统可能只把它当成一个静止的障碍物,但VLA模型可以通过它的常识库进行推理,如这辆车是在路边装卸货,短时间内不会动,而且前方空间足够,可以安全绕行。这种基于逻辑的判断,正是语言模型带来的优势,它让车具备了处理复杂语义和潜规则的能力。
现阶段,VLA的使用已经非常普遍,小鹏汽车于2026年初发布了第二代VLA模型,官方将其定义为物理世界操作系统,彻底摒弃了视觉—语言—动作的传统分段范式,以视觉输入为起点直接映射至车辆控制指令,大幅压缩了信息传递链路,显著提升了响应实时性与推理稳定性。
英伟达则于2025年底正式开源了其自动驾驶VLA模型Alpamayo-R1,这是行业内首个专注自动驾驶领域的开源VLA模型。英伟达公布的数据显示,该模型在复杂场景下的轨迹规划性能提升了12%,近距离碰撞率减少了25%,推理质量提升了45%。值得一提的是,Alpamayo-R1主打可解释性,能够给出自身决策的理由,有助于安全验证、法规审查与事故责任判定,这恰恰解决了传统端到端模型黑盒决策的信任难题。

图片源自:网络
VLA模型的工作流程通常是这样的,它先通过视觉模块看清路况,然后把这些图像信息转化为语言描述,交给内核里的语言模型去思考。大模型会结合导航指令和当前的交通规则,像人类一样给出一串逻辑分析,最后输出具体的驾驶动作。
这种方式最大的好处是,我们可以直接用人类的自然语言跟车沟通,告诉它在前面路口找个安全的地方靠边停一下,此时车就能理解什么是安全的地方,而不是只能执行精确到厘米的经纬度指令。

这两者到底有什么本质不同?
虽然世界模型和VLA都在处理视觉信息,也最终都要服务于驾驶动作,但它们的侧重点有着天壤之别。世界模型关注的是环境的逻辑,也就是这个物理世界是怎么动的。它不一定非要懂人类的语言,它的任务是把下一秒的画面给画出来或算出来,从而提供一个可靠的背景参考。你可以把它看作是一个精密的物理仿真引擎,存在于车的算法底层。
VLA更侧重于决策的逻辑,它并不负责去模拟物理世界的演变,而是负责在看懂环境的基础上,结合人类的知识体系去做决定。VLA更像是一个读过很多书、经验丰富的老司机,它知道遇到校车要保持距离,知道救护车鸣笛时要主动避让。它解决的是为什么要这么开的问题。

图片源自:网络
简而言之,世界模型给出了未来的可能性,而VLA则在这些可能性中,选出最符合逻辑和人类习惯的那一条路径。
对于路线的选择,特斯拉在ICCV 2025上的技术分享中给出了一个的答案,FSD采用端到端基础模型与世界模型深度融合的路线,将多摄像头图像、导航地图、音频信号等输入到一个统一的神经网络中,直接输出控制指令,其整体框架与世界模型思想高度相似。
需要一提的是,世界模型在实际产业应用中已经展现出强大的数据生成能力。商汤绝影在2025年世界人工智能大会上发布了绝影开悟世界模型,这是业内首个已量产、可交互的世界模型。基于一张A100的GPU,绝影开悟每天生成的数据相当于10台真实车或100台路测车的数据采集能力。借助该模型,商汤绝影已生产超100万clips面向量产的生成式数据,覆盖50多类天气和光照条件、200类交通标牌和300类道路连接场景,并与上汽智己汽车合作打造面向量产端到端的数据工厂。

图片源自:网络
此外,世界模型和VLA的学习方式也有所不同。世界模型主要是通过海量的无标注视频来学习,就像小孩子看电视一样,看得多了自然知道杯子掉地上会碎。而VLA的训练则需要大量的视觉-指令-动作对,它需要学习人类在特定场景下是怎么思考和操作的。简单理解就是,世界模型在构建车对外部世界的认知,而VLA在构建车对驾驶任务的理解。

未来它们会如何分工协作?
在未来的自动驾驶架构中,这两者并不是互斥的关系,反而更有可能走向融合。一个完善的系统,既需要世界模型提供的强大预判力,防止意外发生,也需要VLA模型提供的高级推理能力,应对复杂的城市交互。世界模型可以作为VLA的安全底座或者是训练模拟器,让VLA在脑海中进行成千上万次的模拟驾驶,而不需要在真实道路上测试。

图片源自:网络
当前,行业阵营的分化与融合正同步推进,理想与小鹏主推VLA路径,华为与蔚来倾向世界模型,吉利与Momenta明确站队世界模型阵营。但在实际技术实践中,二者的边界正趋于模糊,理想的MindVLA-o1整合了隐式世界推演能力,而吉利的WAM世界行为模型同样依赖多模态识别与价值函数评估。特斯拉FSD V12在旧金山的复杂路况测试中,匝道汇入成功率提升了40%,其核心正是在端到端模型中引入了世界模型以模拟10万种潜在驾驶场景。Wayve则已在伦敦、东京等城市开展Robotaxi路测试点,持续推进端到端学习架构在复杂城市环境中的落地验证。
当我们把这两者结合起来时,自动驾驶将变得更加智能。车既能通过世界模型看透物理规律,避开视觉盲区里的风险,又能通过VLA像人一样理解复杂的交通意图,在车流中丝滑地穿梭。这种技术的进步,正让自动驾驶从一个只会按指令行事的机器,变成一个真正有常识、有逻辑、能预测的智能体。
审核编辑 黄宇
-
Vla
+关注
关注
0文章
26浏览量
5924 -
自动驾驶
+关注
关注
795文章
15082浏览量
182143
发布评论请先 登录
小米正式发布并全面开源自动驾驶模型Xiaomi OneVL
2026年,各车企的自动驾驶方案到了什么阶段(二)?

小鹏发布 X-World 世界模型:已全面应用第二代VLA
如何构建适合自动驾驶的世界模型?

已有VLM,自动驾驶为什么还要探索VLA?
VLA与世界模型有什么不同?

世界模型是让自动驾驶汽车理解世界还是预测未来?

VLA能解决自动驾驶中的哪些问题?
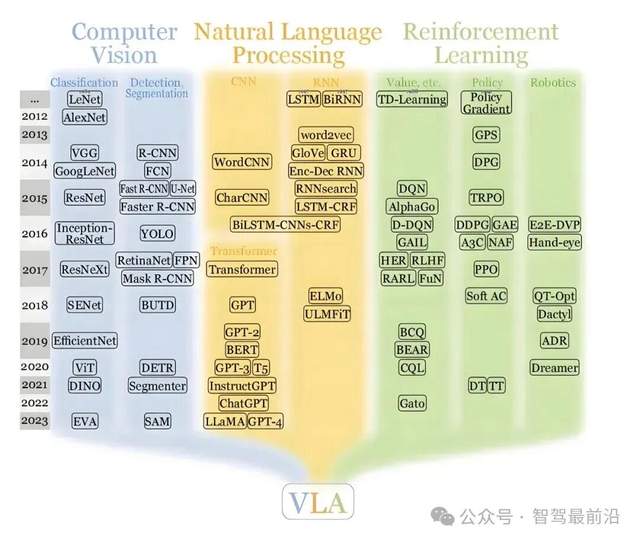
VLA和世界模型,谁才是自动驾驶的最优解?
自动驾驶上常提的VLA与世界模型有什么区别?
传统车企和造车新势力在自动驾驶技术上各有什么优势?

自动驾驶中常提的世界模型是个啥?



评论