 DeepSeek V3.1发布!拥抱国产算力芯片
DeepSeek V3.1发布!拥抱国产算力芯片

电子发烧友网报道(文/李弯弯)2025年8月21日,DeepSeek正式官宣发布DeepSeek-V3.1大模型。新版本不仅在技术架构上实现重大升级,更通过参数精度优化与国产芯片深度适配。从混合推理架构到Agent能力突破,从API价格调整到国产芯片生态共建,DeepSeek V3.1的发布标志着中国AI产业进入技术突破与产业落地协同发展的新阶段。

图:DeepSeek正式发布DeepSeek-V3.1(来自DeepSeek官微)
DeepSeek V3.1的技术突破与生态升级
DeepSeek V3.1的核心创新在于混合推理架构的规模化应用。该架构首次实现单一模型同时支持思考模式与非思考模式:在思考模式下,模型通过深度推理提升复杂任务处理能力;在非思考模式下,则通过精简计算路径实现高效响应。测试数据显示,V3.1-Think在输出token数减少20%-50%的情况下,各项任务平均表现与前代R1-0528持平,而非思考模式的输出长度控制能力则帮助用户降低使用成本。
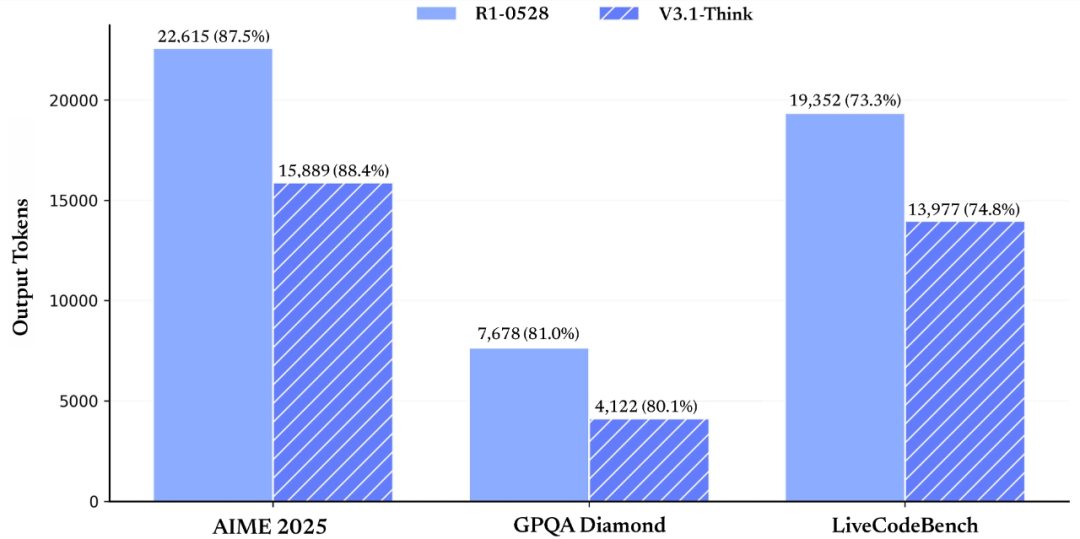
图:在各项评测指标得分基本持平的情况下(来自DeepSeek官微)
参数精度优化是另一重大突破。V3.1采用UE8M0 FP8 Scale技术,将参数精度提升至8位浮点数规模。这一设计不仅减少30%的内存占用,更通过量化感知训练保持模型精度。DeepSeek官方透露,UE8M0 FP8标准是专为下一代国产芯片设计的计算范式,可显著提升芯片在AI推理场景下的能效比。

FP8是Float8的简称,即用8位二进制数表示浮点数,主要用于深度学习的训练和推理。相比传统的FP32(32位浮点数)或FP16(16位浮点数),FP8显著降低了显存占用和计算资源需求,同时通过优化设计(如动态范围调整)维持了较高的精度。FP8对国产芯片的使用效率提升显著,将进一步缩小与NVIDIA芯片的效率/成本差距,大大增加国产芯片的可用性。
在Agent能力方面,V3.1通过Post-Training优化实现质的飞跃。在代码修复测评 SWE 与命令行终端环境下的复杂任务(Terminal-Bench)测试中,DeepSeek-V3.1 相比之前的 DeepSeek 系列模型有明显提高。DeepSeek-V3.1 在多项搜索评测指标上取得了较大提升。在需要多步推理的复杂搜索测试(browsecomp)与多学科专家级难题测试(HLE)上,DeepSeek-V3.1 性能已大幅领先 R1-0528。官方将其定义为“迈向Agent时代的第一步”。
生态建设同步加速。官方App与网页端同步升级V3.1,用户可通过“深度思考”按钮自由切换模式。API接口价格自9月6日起调整为输入每百万tokens 0.5元(缓存命中)/4元(未命中),输出每百万tokens 12元,同时取消夜间优惠。尽管价格有所上调,但输入缓存命中成本保持不变,输出成本增幅控制在50%以内,体现技术优化带来的成本分摊效应。
国产芯片适配进程:从技术追赶到生态共建
DeepSeek与国产芯片的协同发展。2025年1月,华为昇腾910B率先完成V3模型适配,通过自研推理加速引擎使模型性能达到高端GPU水平,在智能安防、工业物联网等端侧场景实现本地化决策。2月,海光DCU完成V3与R1模型适配,其GPGPU架构支持全精度通用AI加速,通信延迟降低40%,训练效率提升35%。同月,龙芯中科发文称,搭载龙芯3号 CPU 的设备成功运行DeepSeek R1 7B模型,实现本地化部署。
多芯片厂商形成差异化竞争格局。沐曦曦云C500 GPU在V3推理中性能达国际主流产品的110%-130%,单位token成本仅为H100的70%;天数智芯支持R1千问蒸馏模型,提供稳定推理服务;壁仞科技壁砺系列覆盖1.5B至70B参数规模的全系列蒸馏模型。摩尔线程成为首个支持原生FP8的国产GPU厂商,其MUSA架构为V3.1提供原生计算支持;芯原股份NPU芯原VIP9000实现FP8技术从云端训练到硬件部署的快速迁移。
政策与市场形成双轮驱动。国家超算互联网平台将DeepSeek模型纳入标准算力库,三大运营商在5G基站部署中优先采用适配国产芯片的AI推理模块。
在能源行业私有化部署实践中,中国石油、中国海油、国家管网等央企已完成DeepSeek私有化部署,中国海油采用全国产化算力,在“海能”人工智能模型平台接入DeepSeek系列模型,通过私有化部署面向全集团提供开放服务。电网故障预测响应时间从分钟级压缩至秒级,需结合实时数据采集、高速算力支撑和智能算法优化,海光DCU的低延迟计算能力与DeepSeek模型的实时推理能力相结合,可满足这一需求。
重构中国AI产业竞争力
技术突破显著降低硬件门槛。DeepSeek通过MoE架构将激活参数量控制在合理范围,V3.1的UE8M0 FP8精度标准使国产芯片在推理场景下的能效比提升40%。实测显示,在671B参数规模下,沐曦曦云C500运行V3的单位算力成本较H100降低35%,推理延迟缩短至8ms以内。龙芯芯片在适配DeepSeek后,也凭借其架构优势,在特定场景下实现了较低的功耗和较高的性价比,为国产AI应用的普及提供了更多选择。
生态共建加速产业落地进程。华为云昇腾算力服务已承载超过7万颗910B芯片,订单价值超20亿美元;海光DCU在金融行业市占率突破28%,其适配的DeepSeek模型日均调用量达4.7亿次。龙芯在完成适配后,积极与众多软件厂商和系统集成商展开合作,推动基于龙芯芯片和DeepSeek模型的解决方案在更多行业落地。例如,在一些教育领域的智能教学系统中,龙芯芯片与DeepSeek模型结合,实现了智能答疑、个性化学习推荐等功能,提升了教学质量和效率。
技术差距缩短在具体领域表现突出。华为昇腾910C在推理性能上达到H100的60%,能效比优于后者;沐曦曦云C500成为首个支持70B参数大模型单卡推理的国产GPU。龙芯芯片在不断研发和优化过程中,性能也在逐步提升,在一些特定的AI应用场景中,已经能够满足基本的需求,为中国在AI算力芯片等关键领域的自主化率提升贡献了力量。
写在最后
站在2025年的节点回望,DeepSeek V3.1的发布不仅是单一产品的迭代,更是中国AI产业生态重构的缩影。从技术参数的优化到产业生态的共建,从芯片算力的突破到应用场景的落地,中国AI正在走出一条不同于国际巨头的自主化道路。随着UE8M0 FP8标准成为行业新范式,随着“模型+芯片+应用”生态的持续完善,中国AI产业有望在2030年前实现全球竞争力的实质性跃升。
发布评论请先 登录
华为领衔,三剑客入局!十万卡智算集群落地,国产算力芯片强势崛起

百度腾讯抢滩布局!DeepSeek-R1升级和开源背后,国产AI的逆袭之路
国产AI算力:从DeepSeek V4与华为昇腾协同看全栈自主之路
国产算力出海元年开启

国产算力生态拥抱开源AI智能体:光合组织全国OpenClaw体验“龙虾局”正式启动

赋能电源芯片国产替代,智芯谷助力AI算力稳定前行



国产AI芯片真能扛住“算力内卷”?海思昇腾的这波操作藏了多少细节?
拥抱DeepSeek开源生态| 算能TPU接入TileLang,集结北大复旦山大顶尖团队!

商汤大装置算力Mall重磅发布
借势 RISC-V与 AI 浪潮,元石智算打造算力新范式




评论