 拥抱DeepSeek开源生态| 算能TPU接入TileLang,集结北大复旦山大顶尖团队!
拥抱DeepSeek开源生态| 算能TPU接入TileLang,集结北大复旦山大顶尖团队!

近日,DeepSeek V3.2-Exp 上线,官宣支持国产AI算子编程语言TileLang 并发布了针对 V3.2 的算子示例,这意味着支持“同一语义、跨多后端”的TileLang得到了权威认可,基于算能TPU的TileLang-TPU项目也于近日完成工程验证。
TileLang 发布之初,算能联合北京大学、复旦大学、山东大学等高校的科研团队,共同开展TileLang接入算能TPU的工作,目前已在BM1684X 、SC11等智算平台上完成了主流大模型算子的工程验证。
算能SC11 FP300单卡集成256GB LPDDR5X高带宽内存,内置原生FP8算力单元,板载高达1.1TB/s的内存带宽,配合PCIe Gen5主机接口及256GB/s的卡间高速互联,有效应对大模型参数存储与计算需求,DeepSeek V3满血版在4卡SC11上吞吐超过600tokens/s。
Tile Language (TileLang) 是一种简洁的领域专用语言,也是一款开源的 AI 算子编程语言,TileLang 对接算能TPU扩展的工作由北大硕士生解文浩、博士生任天行作为主要负责人牵头开发,山大、复旦的研发团队也参与了算子开发、大模型接入TPU的工作,一并表示感谢。
全栈贯通|从可行性到工程闭环
TileLang能够将高级别的数据流描述,自动转换并优化为高效的底层代码(如CUDA或TPU kernel)。通过独特的Tile级抽象和自动调度能力,开发者可以用更简洁的代码表达复杂计算,快速为自己的算法开发一个接近峰值性能的算子,显著提升算子开发效率。
TileLang-TPU适配路径以“少惊扰、强约束”为原则:前端仅描述 tile 级计算逻辑与数据流,不引入设备细节;中间以稳定的 Tile-IR 承接形状推断、布局决定与算子融合;后端生成面向算能 TPU 的 device 侧 C 代码与指令序列,并与 PPL 的内核注册、调度与运行时贯通。
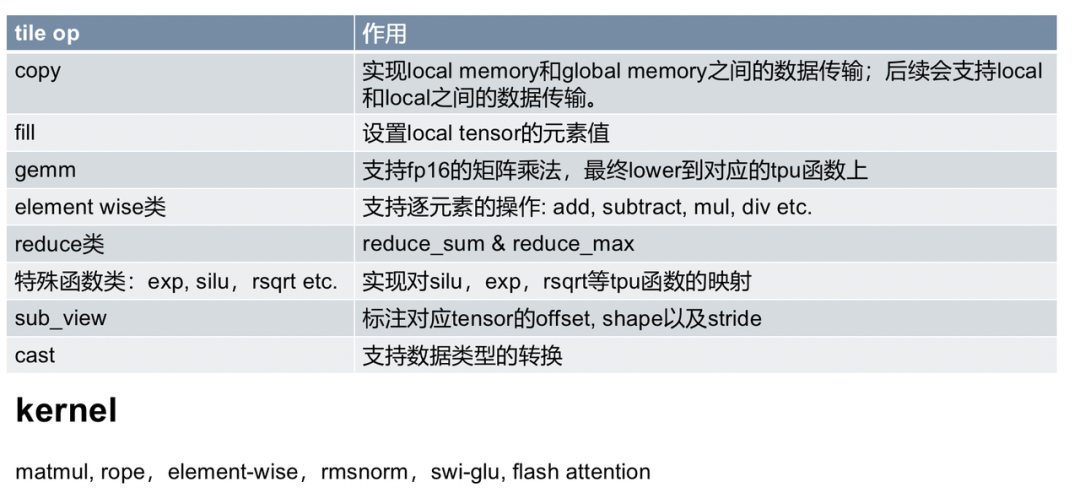
该路径已在典型大模型算子上跑通,涵盖常见的 GEMM、归一化与位置相关变换等,完成从算子表达、代码生成、到 hostdevice 数据搬运和执行的全链路打通。由此,TileLang 的一次建模、多后端复用能力在国产 TPU 场景获得验证,为后续开源与规模化交付奠定了基础。
极致简洁|三步实现 TPU后端支持
TileLang-TPU的核心工作聚焦三点:前端原语扩展。于 TileLang/language/customize.py 增补自定义 tile op 接口,使 GEMM、RMSNorm、RoPE、SwiGLU 等算子可以以更贴近数学定义的方式表达,并在 Tile-IR 层明确迭代空间、数据复用与流水线切分,减少手写索引与 bank 冲突的偶然性。

代码生成映射。于 src/target/codegen_ppl.cc 完成原语到算能 TPU 专用执行单元的映射,将GEMM 一类算子对齐到 BDC 的矩阵乘路径(如 tpu_bdc_fp_mm.v 等),同时根据设备层级内存模型生成指令序列与局部缓存策略,确保计算与搬运(GDMA)管线化协同。以matmul在BM1684x上的计算为例,使用TileLang撰写的算子跟PPL手写算子性能持平,代码更加简洁。
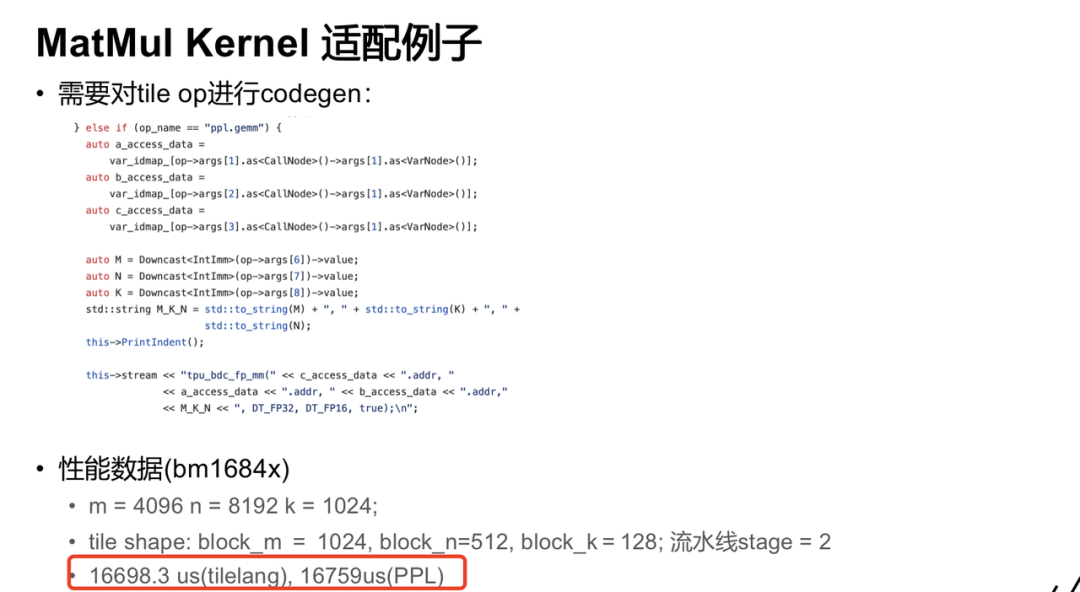
运行栈整合。生成的 device 侧 C 代码与元信息并入 PPL 体系,完成 kernel 注册、调度入口与形参绑定,保证 host 侧装载、形状检查、dtype/stride 处理与 device 侧执行一致;必要时补充 tiling 规则与长短轴对齐策略,以兼顾大shape与批处理场景。当前已实现TileLang 前端 → PPL/TPU 设备端 C → PPL 运行期可执行的完整链路,关键算子具备可对齐的性能基线与可定位的优化,便于后续按模型族进行系统化补全与压测。
持续开源 | 一次改写多处复用
TileLang开源的价值不止于“又多了一个后端”,更在于“少了成倍的重复移植”。在国产芯片生态日益多样化的现实下,统一的 tile 级前端抽象能把算子资产沉淀在可组合、可验证的语义层;迁移到新后端时,仅需围绕 CodeGen 与 runtime 这条窄口补齐映射与 ABI,可继承既有的表达、调度与测试体系。
这种“前端统一、后端定制”的方式,有机会在工程维度缓解国产芯片的碎片化,让差异化架构以最小成本共享同一套高质量算子实现与基准。后续开发团队将优先确保DeepSeek等主流模型链路的端到端可用,再面向长尾算子逐步补全,并在流水线深度、访存回填、缓存复用等细节上持续优化最佳实践。
TileLang-TPU 正在做开源前的代码清理与文档化的工作,它的意义并不在于“多了一个后端”,而在于“少了很多重复”,当同一套算子前端可以映射到更多芯片时,碎片化就不再是阻力,而会成为竞争力,让不同架构以各自所长服务更大的模型与更广的场景,而不是把资源消耗在移植与改写上。
再次感谢来自北大、复旦、山大等高校的研发团队在TileLang-TPU上所做的前瞻性工作,后续的开源仓库将附带清晰的示例与文档,支持以标准化方式扩展原语、以严谨的工程标准实现“一次改写、多平台复用”的目标。TileLang-TPU的成功验证,将进一步加深算能与高校、开源社区的合作深度,为完善国产芯片软件栈打造一个经典范式。
-
AI
+关注
关注
91文章
41060浏览量
302568 -
TPU
+关注
关注
0文章
172浏览量
21716 -
DeepSeek
+关注
关注
2文章
837浏览量
3396
发布评论请先 登录
DeepSeek V3.1发布!拥抱国产算力芯片

沐曦股份GPU产品正式接入华佗开源生态

国产算力生态拥抱开源AI智能体:光合组织全国OpenClaw体验“龙虾局”正式启动

摩尔线程正式开源TileLang-MUSA项目
北大团队最新研究:AI芯片算力提升数倍,能效提升超90倍
中北大学以开源技术铺就人才与产业共赢之路
东北大学开源鸿蒙技术俱乐部正式揭牌成立

复旦大学探索开源人才发展新模式

沐曦曦云C系列产品已支持TileLang

边缘计算AI硬件如何接入DeepSeek吗?需要具备哪些条件?

【「DeepSeek 核心技术揭秘」阅读体验】--全书概览
【「DeepSeek 核心技术揭秘」阅读体验】书籍介绍+第一章读后心得
TPU编程竞赛系列|2025中国国际大学生创新大赛产业命题赛道,算能11项命题入选!




评论