 国产AI算力:从DeepSeek V4与华为昇腾协同看全栈自主之路
国产AI算力:从DeepSeek V4与华为昇腾协同看全栈自主之路

电子发烧友网报道(文/李弯弯)2026年4月24日,DeepSeek V4 - Pro和DeepSeek V4 - Flash正式发布并开源。模型上下文处理长度从128K大幅提升至1M,新增KV Cache滑窗和压缩算法,显著降低计算与访存开销,在Agent能力、世界知识和推理性能上处于国内及开源领域领先地位。
与此同时,华为宣布昇腾超节点全系列产品全面支持DeepSeek V4系列,这场芯模协同不仅彰显技术实力,更标志着国产AI算力在摆脱海外依赖、构建全栈自主生态上迈出关键一步。
生态迁移:从CUDA到CANN的跨越
DeepSeek V4与华为昇腾的合作,核心在于从英伟达CUDA生态向华为自研的CANN异构计算架构迁移,这一过程远非简单的代码移植。
过去,中国大模型开发高度依赖英伟达GPU和CUDA生态,从训练到推理都面临卡脖子风险。此次迁移需重写数十万行底层代码,重构通信协议、显存管理等核心模块,攻克算子对齐、通信优化、内存管理三大技术壁垒。
据传,DeepSeek团队耗时14个月攻坚,华为工程师驻场支持,反复调试精度、优化算子。最终,经深度优化,DeepSeek V4在昇腾950PR上的推理速度较初期版本提升35倍,能耗降低40%。第三方评测显示,昇腾950PR单卡推理性能达到英伟达特供版H20芯片的2.87倍。这一成果表明国产AI芯片正加速从“可用”迈向“好用”,在特定场景下已具备超越国际主流产品的竞争力。
华为计算官微显示,华为昇腾950超节点通过融合kernel和多流并行技术,结合多种量化算法,实现了DeepSeek V4模型的高吞吐、低时延推理部署。具体而言,昇腾950超节点实现了DeepSeek V4 - Pro 20ms和DeepSeek V4 - Flash 10ms的极低时延推理。在8K输入场景下,单卡Decode吞吐分别可达4700TPS(V4 - Pro)和1600TPS(V4 - Flash)。这一成就得益于昇腾950底层架构的三大升级:原生精度加速支持FP8、MXFP8等数据格式,内存占用降低50%以上;稀疏访存优化解决MoE模型带宽瓶颈;Vector与Cube共享Memory设计消除数据搬运开销。
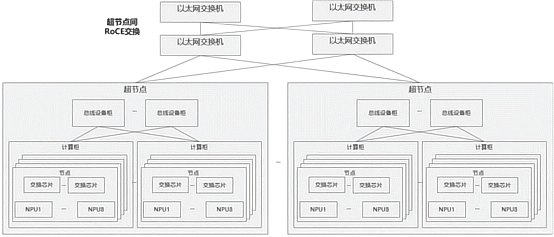
此外,Atlas 900 A3 SuperPoD液冷超节点及Atlas 800 A3风冷超节点采用平等架构、全局内存统一编址、点对点互联带宽达784GB/s。提供32到384多种规格满足不同业务需求,昇腾超节点是国内唯一成熟规模商用的超节点产品,满足互联网、运营商、金融等行业对大模型推理超高吞吐、超大并发的极致性能需求。
基于昇腾A3 64卡超节点结合大EP模式部署,DeepSeek V4-Flash模型,8K/1K输入输出场景,基于vLLM推理引擎可实现2000+TPS的单卡Decode吞吐,单卡吞吐持续提升。针对DeepSeek V4-Pro模型,昇腾A3同步支持推理部署,性能持续优化中。
此次合作意义重大,彻底打破了国产AI对海外技术的依赖。DeepSeek V4成为首个在华为昇腾平台上完成从训练到推理完整闭环的万亿级模型,中国首次拥有了从顶级大模型到自主算力基础设施的完整、可控的AI技术栈。这不仅是技术上的胜利,更是产业生态的转折点,向市场证明国产算力有能力承载全球顶尖AI模型,且能实现性能与成本的双重优势。
国产大模型与算力的协同共进
在DeepSeek V4发布当天,寒武纪宣布基于自研NeuWare软件生态与vLLM框架,完成对DeepSeek V4的“Day 0”适配,并将适配代码开源至GitHub社区。这是寒武纪连续第二次在DeepSeek新模型发布首日推出国产芯片适配方案,通过自研高性能融合算子库Torch - MLU - Ops和BangC编程语言,充分释放硬件底层潜力。
天数智芯也完成了与DeepSeek - V4的Day 0级适配,以天垓系列训练芯片与智铠系列推理芯片为核心,承接DeepSeek - V4的全场景应用。此外,DeepSeek V4 - Flash还已经在海光信息、沐曦、摩尔线程(FP8)、昆仑芯、平头哥真武等国产AI芯片平台上实现适配。
近年来,随着先进大模型的发布和开源,国产AI芯片厂商纷纷发布Day 0适配消息。如MiniMax M2.7全球开源时,华为昇腾、摩尔线程、沐曦股份、昆仑芯等厂商就宣布推理平台已完成Day0适配,即在开源首日完成模型接入与推理适配工作。
MiniMax M2.7开源当日,华为昇腾AI基础软硬件实现首日适配,基于vllm - Ascend推理引擎在Atlas800A3、Atlas800IA2系列产品上为模型推理部署提供全流程支持;摩尔线程技术团队基于MUSA架构,针对M2.7的模型特点完成深度调优,成功在MTTS5000上实现模型高性能推理;沐曦曦云C系列GPU凭借全栈自研的MXMACA软件栈,首日完成深度适配,实现“模型发布即算力就绪”的Day0体验;昆仑芯依托自研架构,通过底层算子优化与软硬件协同加速,保障M2.7在平台上的稳定、高效运行。
此外,近日腾讯混元Hy3preview语言模型发布并开源,依托全栈自研技术优势,壁仞科技基于vLLM主流开源框架实现Hy3preview模型的Day0适配及推理验证。月内该公司旗舰GPU产品适配国内多家大模型,包括月之暗面Kimi K2.6模型、阿里(BABA)Qwen3.6-35B-A3B大模型等。
在AI大模型和芯片领域,适配是关键技术术语,指让软件在特定硬件或软件平台上顺利、高效运行的一整套技术工作。国产AI芯片在支持大模型推理上已呈现全面发展态势,此次华为昇腾对DeepSeek V4的全面支持,让DeepSeek V4摆脱CUDA生态依赖,使用CANN,国产AI算力实力更上一层楼。
国产AI算力的未来展望
DeepSeek V4与华为昇腾的深度融合,不仅是技术上的成功适配,更是深刻的战略转型,标志着中国AI产业从依赖海外技术迈向全链路自主可控。
性能上的反超和成本上的巨大优势,为国产AI的商业化落地铺平道路。随着下半年昇腾950超节点的批量上市,DeepSeek V4 - Pro的服务价格有望大幅下调,这将加速AI技术在金融、政务、法律等关键领域的普及应用。
从数据上来看,全球智能计算芯片市场预计2029年达到5857亿美元,2024-2029年年符合增长率37.5%;中国市场增长更快,复合增长率达46.3%,国产AI芯片厂商市场份额有望持续提升。
展望未来,一个由国产芯片、国产框架、国产大模型构成的完整AI生态闭环正在加速形成。这不仅体现了国家科技自立自强的战略要求,也为全球AI产业发展提供了新的思路和模式。
-
AI算力
+关注
关注
1文章
169浏览量
10033
发布评论请先 登录
DeepSeek V3.1发布!拥抱国产算力芯片

长江计算G940K V2超节点服务器完成对DeepSeek V4模型极速适配
【硬核发布】昇腾310B算力盒上新赋能2026集创赛华强x昇腾赛道玩转新创意!

国产算力出海元年开启

华为发布全新昇腾950PR,Atlas 350单卡算力接近3倍于H20
【赛题解析】2026集创赛华强x昇腾企业命题!用国产AI算力重塑未来数字幻境!
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
香橙派昇腾系列开发板如何部署OpenClaw
华为发布全球最强算力超节点和集群
高达2070TFLOPS算力|腾视科技基于NVIDIA Jetson Thor系列模组,重磅推出全栈AI边缘智算大脑解决方案

高达2070TFLOPS算力|腾视科技基于NVIDIA Jetson Thor系列模组,重磅推出全栈AI边缘智算大脑解决方案
高达2070TFLOPS算力腾视科技基于NVIDIA Jetson Thor系列模组,重磅推出全栈AI边缘智算大脑解决方案

有关 AI 算力,华为昇腾刷新行业记录



评论