 双卡锐炫来助阵,本地部署DeepSeek也能性价比
双卡锐炫来助阵,本地部署DeepSeek也能性价比

对于“AI模型是显存杀手”这事,我想就算那些没有本地部署过,甚至没有特别关注过我们显卡和笔记本评测中的AI体验部分的玩家应该也知道这个事实——毕竟从年初到现在,DeepSeek已经足够火爆,以至于公园下棋老大爷都能给您编排出一段AI界的三国演义出来.....回到本文的主题,今天我们还是聊聊本地部署DeepSeek模型这事。

首先还是要说明的是,我们部署的是DeepSeek-R1蒸馏模型,而不是DeepSeek-R1 671B。老实说,671B的满血版确实超出普通玩家的范畴了,和个人范畴内的“性价比”更是毫不相关。不过,蒸馏模型还是能做不少事情的,比如用于翻译服务,而且本地部署有很多好处,除了老生常谈的隐私问题外,还能避免“服务器繁忙,请稍后再试”这种情况发生。
然而就算是蒸馏模型,对于显卡的要求也是相当高。这里不说DeepSeek-R1蒸馏模型中最大的DeepSeek-R1-Distill-Llama-70B了,就算是排第二的DeepSeek-R1-Distill-Qwen-32B,要想单卡运行的话您至少需要一张RTX 5090或者RTX 4090。考虑到它俩现时的价格,这仍然算不上是很“性价比”。那么,还有什么便宜大碗的方案呢?
那当然还是有的,而且可能比买二手显卡这事还要稳——两张英特尔锐炫A770 16GB便是个值得尝试的方案。别被双卡这个概念吓到,以显存容量去评判的话,两张锐炫A770加一块也就3600元,可是要比RTX 4070还要实惠。唯一有要求的可能是您的主板和电源,前者是PCIe速度,后者自然是两张A770的功耗了。

“大显存支持:16GB GDDR6显存(显存带宽560GB/s)为大型模型训练和推理提供了充足的资源,尤其适合需要高显存容量的AI应用和内容创作场景。”——节选自DeepSeek-R1对锐炫A770 16GB的评价。
测试平台
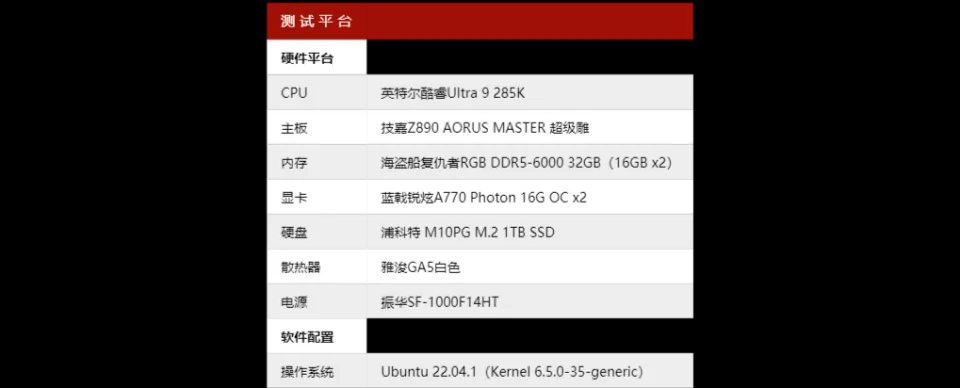
本次测试的平台是英特尔大全套,处理器是酷睿Ultra 9 285K。其实在这次测试中,CPU反而不太重要,拿颗酷睿Ultra 5也行。重点反而是主板,最好选一些两个PCIe 5.0 x8插槽的主板。

您也许会问为什么我给出这样的建议但是却用了技嘉Z890 AORUS MASTER这块配置为PCIe 5.0 x16(CPU)、PCIe 4.0 x1(芯片组)和PCIe 4.0 x4(芯片组)各一个的主板。原因也很简单,本来打算用的Z890主板的Killer网卡比较新,在本次系统里似乎暂时缺乏驱动支持,于是就这样了。
前期准备
目前这个方案只能在Linux环境下面用,因此安装系统便成了首先要解决的问题。根据英特尔树外驱动的要求,我安装了Ubuntu 22.04.1(内核是Kernel 6.5.0-35-generic)。因为Linux基本离不开终端操作,所以接下来我会说得简要一点,毕竟要把一大段命令当成正文颇有种水字数的感觉,不利于阅读(我就假定在读本文的各位和我一样略懂点Ubuntu就好了,反正也就用到sudo apt install这些命令)。
装完系统之后便是树外驱动了。反正照着英特尔的文档添加软件源,然后装上intel-i915-dkms和intel-fw-gpu这两个软件包,把当前用户分到渲染组就可以了。
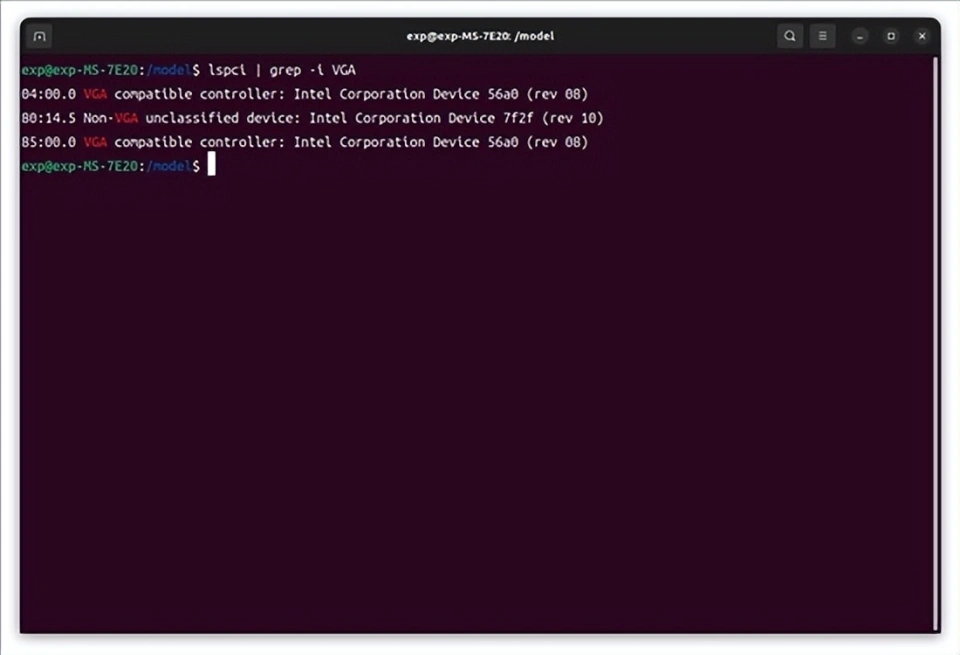
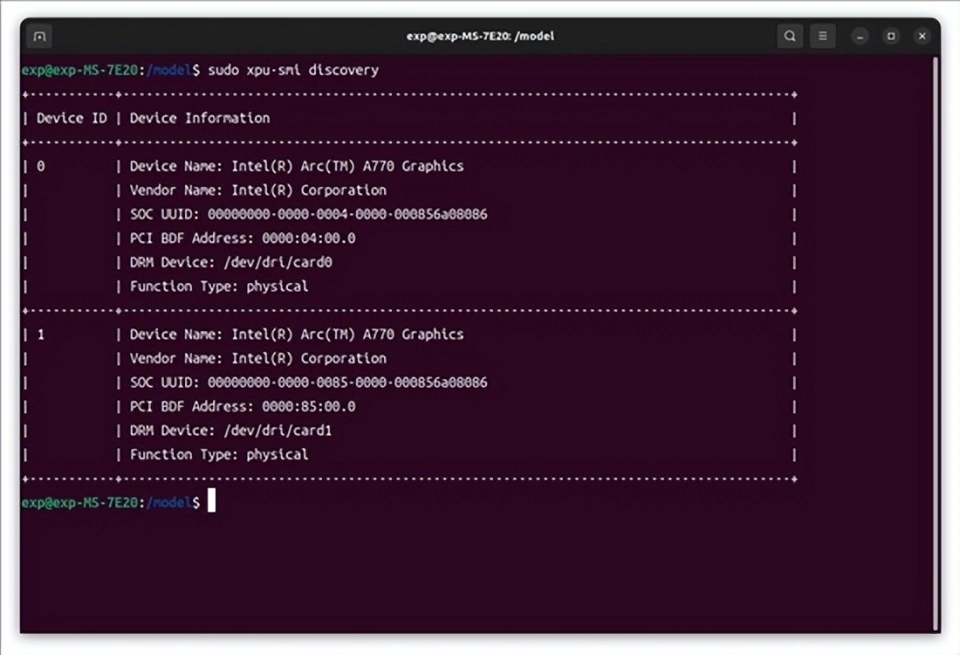
重启后,用lspci或者xpu-smi(这个需要额外安装)可以看到两张锐炫A770 16GB已经就位。至于多出来的那个non-VGA设备则是酷睿Ultra的NPU,不用去管它。
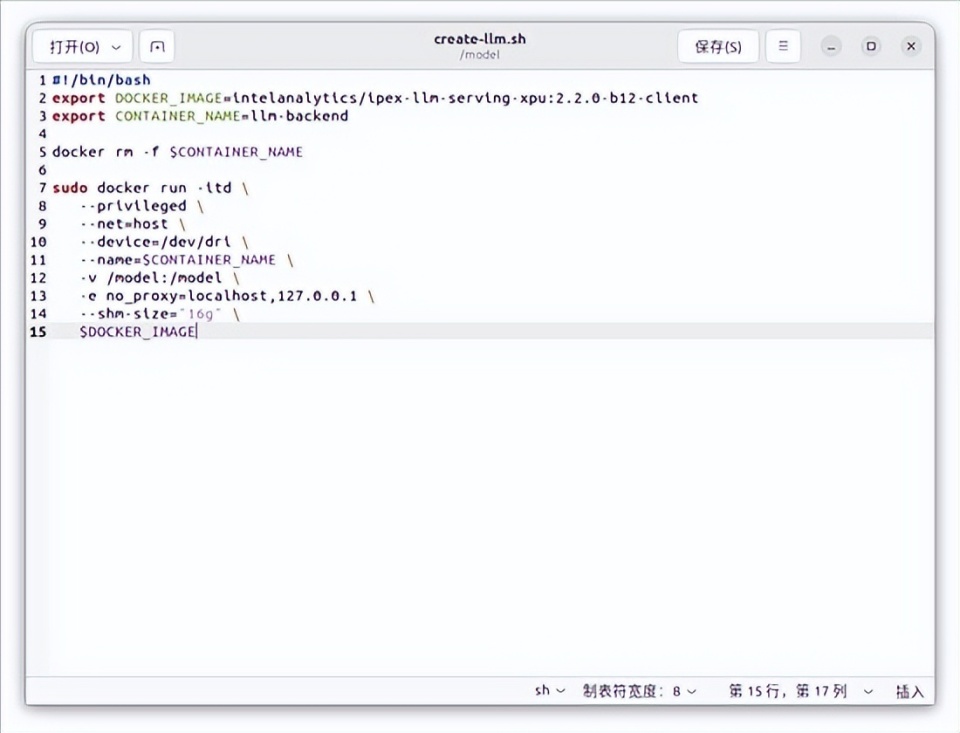
接下来的操作就很简单了,毕竟我们是通过docker来运行前后端的,如果玩过NAS的话应该知道docker有多好用——只要您有一个足够良好的网络。不过我们有现成的镜像和脚本,倒不用进行拉取这一步,如果您要照做的话,请拉取open-webui(前端)和intelanalytics/ipex-llm-serving-xpu:2.2.0-b12-client(后端)这两个镜像。脚本的话可以结合最下面的链接,同时参考下面的截图。
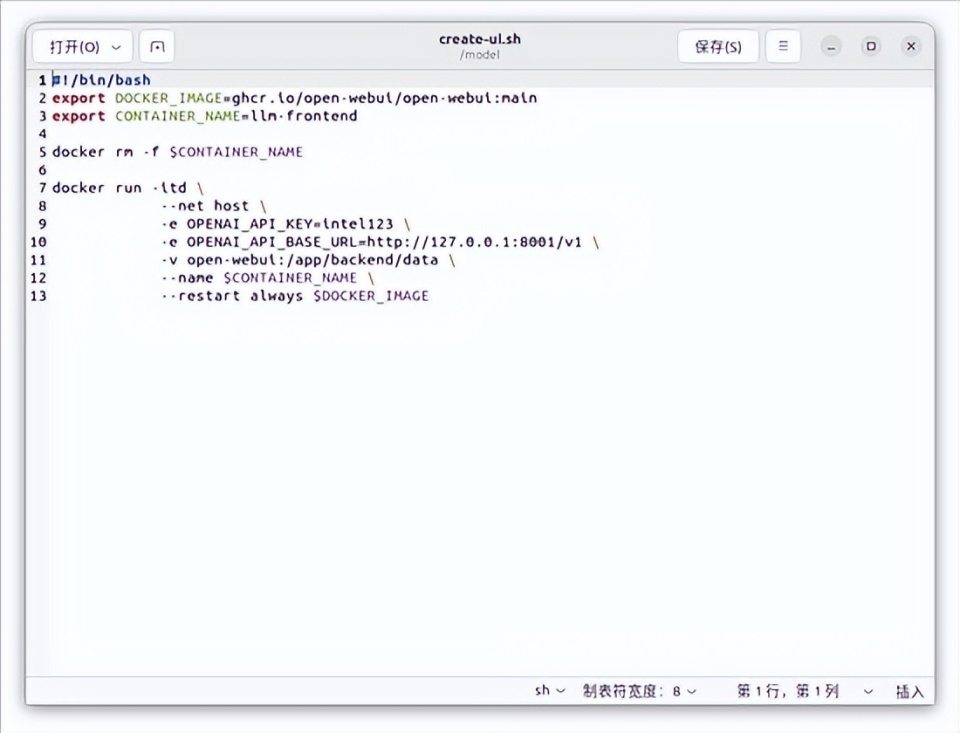
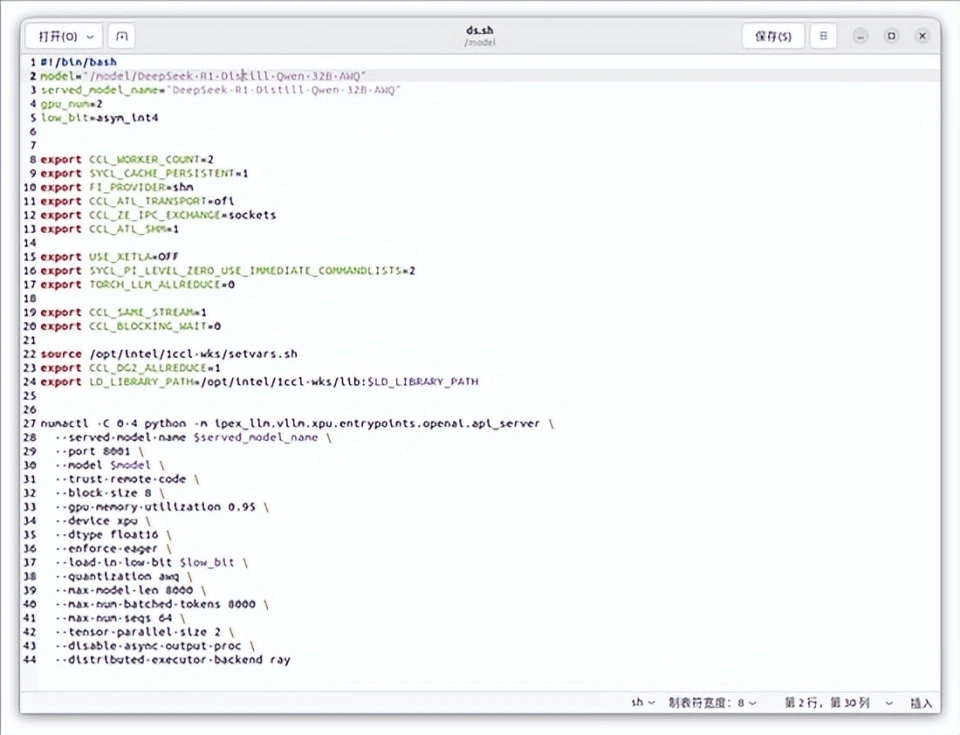
这里顺便说一下ipex-llm是什么,它是一个为英特尔GPU打造的LLM加速库,支持核显、锐炫独立显卡和数据中心显卡等设备,并已经和llama.cpp、Ollama和vLLM等框架无缝集成。
最后是AI模型DeepSeek-R1-Distill-Qwen-32B-AWQ,这个用huggingface-cli下载就行。记得把环境变量改成镜像站hf-mirror.com,可以提高下载速度;还有就是把模型下到本地文件夹里面,不使用huggingface-cli的缓存系统。
对了,如果您不打算更改上面的脚本内容,这里建议把下载的所有东西都扔到根目录下的/model文件夹中。
参考阅读1:树外驱动安装《Installing Data Center GPU: LTS Releases》
参考阅读2:通过docker部署AI服务《vLLM Serving with IPEX-LLM on Intel GPUs via Docker》
实际体验
准备工作完了之后,接下来就非常简单了,用脚本启动前后端容器,并启动后端应用即可。
在本地机上访问127.0.0.1:8080就能见到Open WebUI的主界面了,这个服务是对局域网开放的,所以我们也可以用连到同一个网络的设备去访问它,比如手机和平板。


接下来的界面相信大家就很熟悉了,就和平时用的网页chatbot一样。只不过这一次所有的服务都运行于本地,不受网络波动的影响,拔掉路由器的WAN口也一切如常。

来看看它的运行速度。单个用户访问时,平均生成速度在26 tokens/s左右。在上图的演示里面,我们让它用HTML写了个贪吃蛇,完成后右侧就出现了窗口,可以马上进行游玩。另外,还可以根据需求叫AI修改代码,比如这次我叫它把贪吃蛇改成自动运行,这样截图会方便一点。
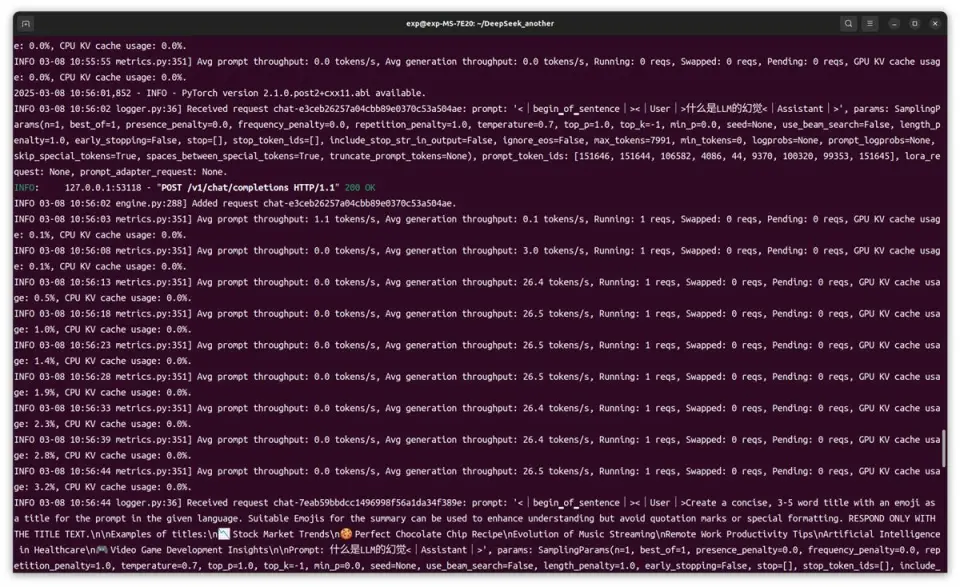
单用户使用
但这显然还不是这套平台的极限。我们试了试在三台设备(本机 + 另一台电脑 + 手机)上同时访问AI服务,平均生成速度可以达到66tokens/s。无论在哪台设备上,AI都没有出现卡壳的现象,输出文字的速度很快。
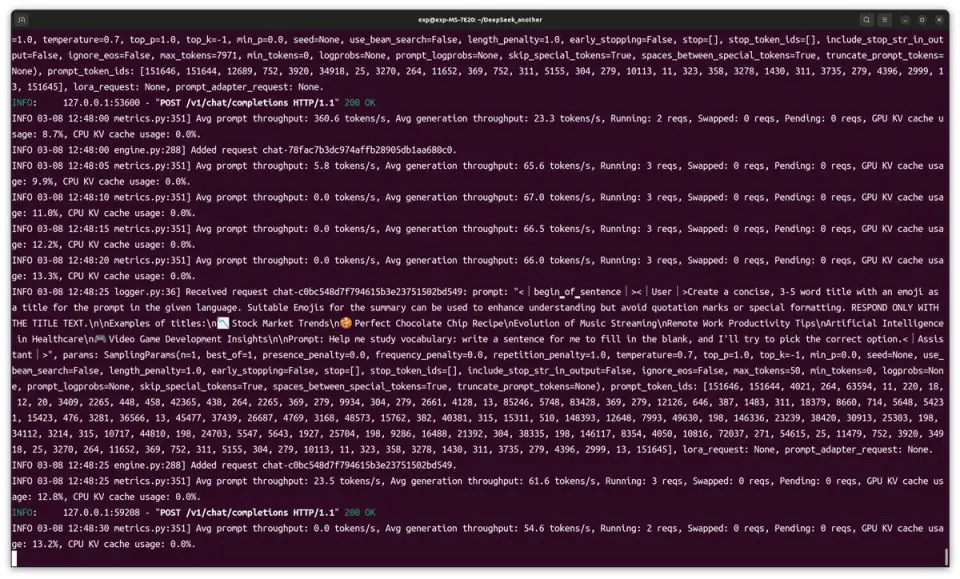
多用户使用
附加内容:如何切换模型?
正当我们体验DeepSeek-R1蒸馏模型的时候,国内另一家实力同样强劲的大模型团队通义发布了他们的推理模型QwQ-32B。该模型在AIME24、LiveBench等多个基准测试中表现出不弱于DeepSeek-R1 671B也就是满血版DeepSeek-R1的实力,更是要比上面运行的蒸馏模型要强得多。因此我们也在这里介绍一下如何把模型切换成QwQ-32B(以及其他你想体验的模型)。
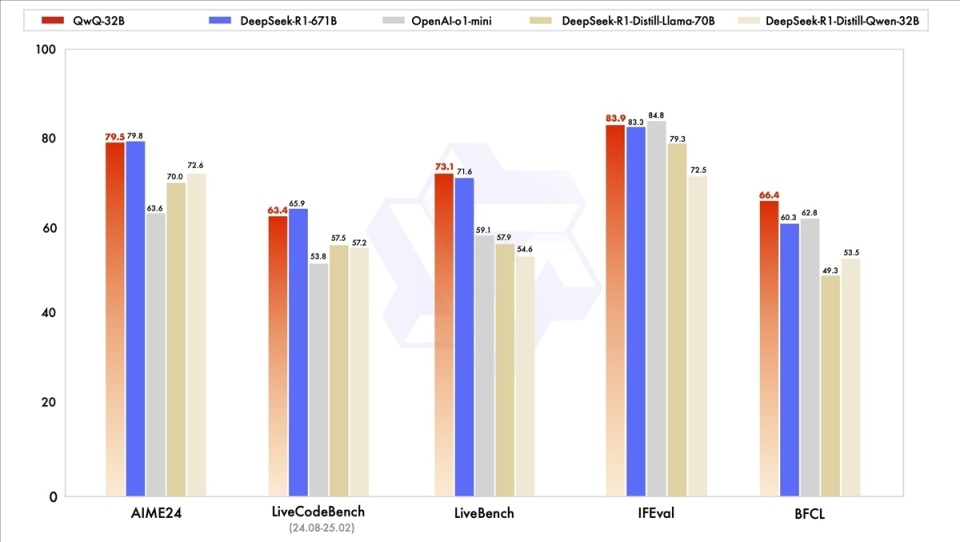
来源:Qwen博客
首先还是用huggingface-cli把QwQ-32B的模型拖到/model文件夹中,我们这次选择的是QwQ-32B-AWQ,也就是用AWQ量化的版本。
接下来只需要修改上面图片中的ds.sh脚本就行,当然,这里建议直接复制一份并重命名为QwQ.sh再进行修改,便于日后操作。要修改的地方不多,就是前面两行的路径和命名而已。做好这部分工作后重启一下后端容器,用脚本启动即可。
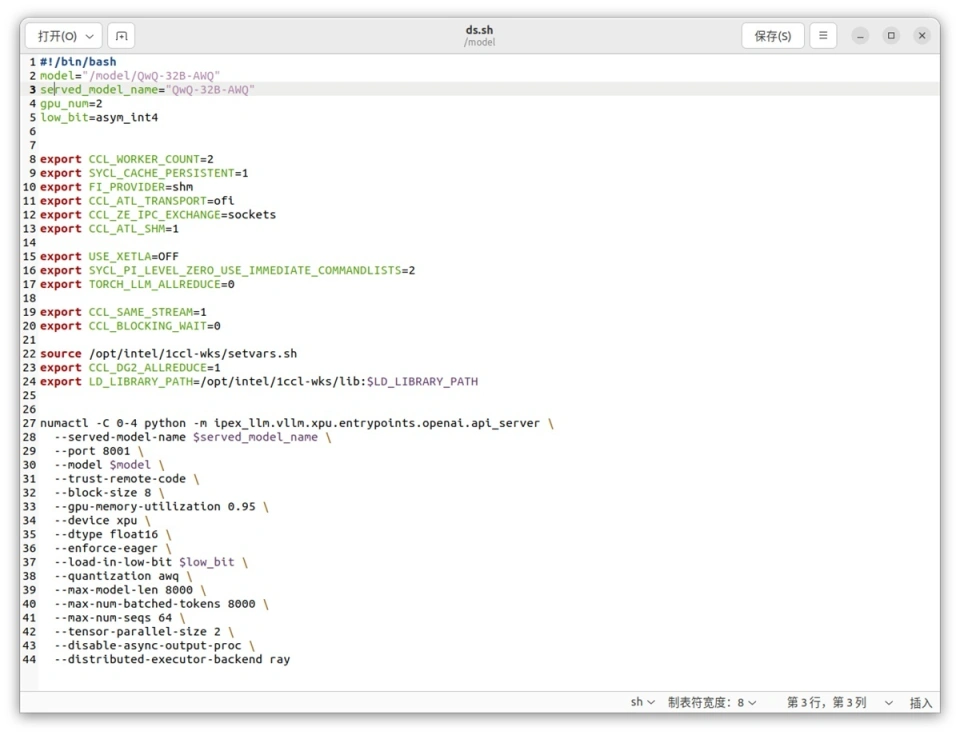
我这里没有改名,直接保存了
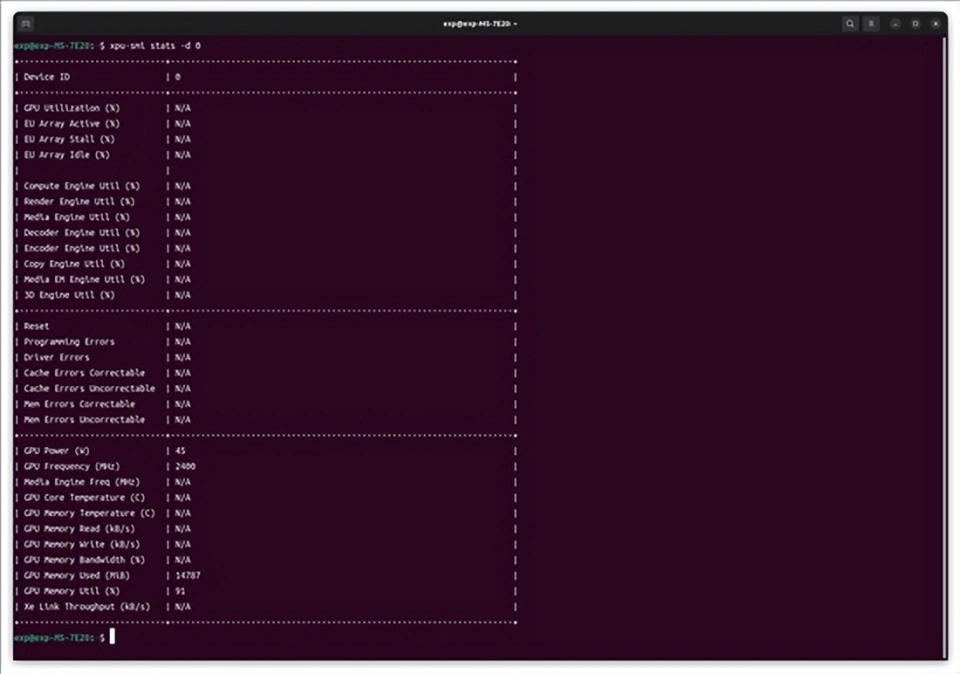
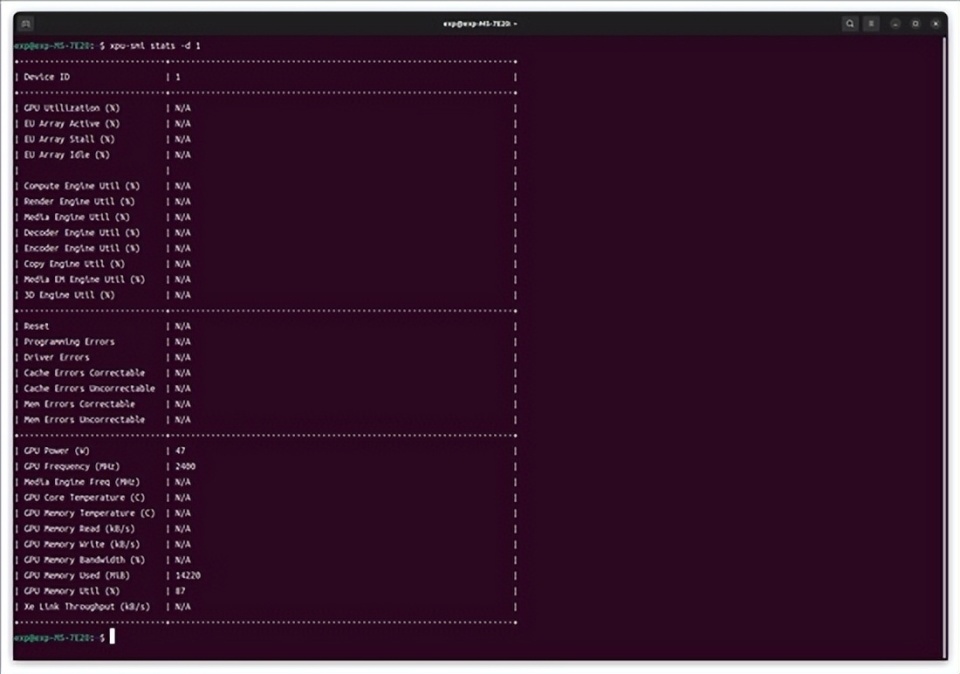
至于QwQ-32B-AWQ在这套平台上的运行情况和蒸馏模型时类似,平均生成速度也是26 token/s。另外我们特意用xpu-smi监测了两张显卡的显存占用情况,每张显卡各消耗了14GB显存左右,合起来大约是28GB。如果要仅用一张卡处理这么大的模型,那预算真的要花上不少。
总结
总的来说,两张锐炫A770 16GB确实是一个性价比较高的本地部署AI方案。正如我在开头所说,不把二手设备算在内的话,现在3600元您真的很难买到一张NVIDIA或者AMD的大显存显卡,但是一口气买两张锐炫A770 16GB(甚至还是OC版)是完全有可能的,更进一步地说,由于单卡价格的足够实惠,你还可以买更多张去运行参数量更大的模型(当然,这时候主板和处理器会比锐炫A770要贵得多)。除了硬件上足够有性价比外,我们还要强调一下软件上的优势:锐炫显卡有着来自英特尔完善的驱动和加速库支持,部署时docker镜像一拉就完事,然后运行时双卡都能拼尽全力,这些点也是相当重要的。

接下来也说说这个方案的一些注意的点。首先就是功耗和发热了,虽然您不会每分钟都向AI提问,但是如果把它当作一台全时运行的AI服务器的话,累积下来的耗电(还有制造的热量)还是挺“可观”的。其次就是部署的难度问题,如果您不是从事计算机方面的工作,用Ubuntu这些Linux发行版还是一件蛮有挑战性的事——事实上在测试过程中,我也因为太久没捣鼓路由器和NAS而忘掉一些命令的用法,只好不停地“--help”。
不过话说回来,这两种情况在未来都是可以改变的。英特尔表示在未来,玩家将可以用2块锐炫B580搭建AI服务器,以及加入对Windows 11的支持,对于绝大部分的玩家来说,后者尤其是好事。当然,如果你只是想简单体验英特尔硬件的AI性能,也可以直接下载英特尔AI Playground这个应用就是了。
审核编辑 黄宇
-
英特尔
+关注
关注
61文章
10321浏览量
181079 -
DeepSeek
+关注
关注
2文章
839浏览量
3397
发布评论请先 登录
本地部署OpenClaw,只要500元的开发板?

免费本地部署的数据库 DevOps 工具,能覆盖多少日常工作场景?以 NineData 社区版为例

如何在ZYNQ本地部署DeepSeek模型

工业物联网平台适合私有本地部署还是云端部署?
锐能微RISC-V双核MCU芯片在智能电表中的应用
DeepSeek模型如何在云服务器上部署?
广和通成功部署DeepSeek-R1-0528-Qwen3-8B模型
本地部署openWebUI + ollama+DeepSeek 打造智能知识库并实现远程访问

【「DeepSeek 核心技术揭秘」阅读体验】+混合专家
能源监测管理平台是本地化部署好还是云端部署好?





评论