 RZ MPU工业控制教程连载(62)Yocto系统添加程序
RZ MPU工业控制教程连载(62)Yocto系统添加程序

14.7
Yocto系统添加程序
14.7.1 快速增加软件包
在Yocto中如果我们期望在rootfs中添加一些软件,例如可能是bash,可能是lsusb等,那么,我们可以有两种方法:
手动添加,一个个文件的拷贝。
或者在bb文件中添加安装项目,让Yocto自动帮助我们添加。
第一种方法需要手动将软件包的所有文件以及依赖都一个个添加进去,耗时耗力且易错,因此使用第二中方法比较合适。
Yocto中Rootfs中添加软件包的步骤
找到打包rootfs的最终bb
如果我们使用的是bitbake myir-image-full编译命令。
那么,我们可以按照如下来搜索myir-image-full这个软件包(任务),使用的是哪个bb文件:

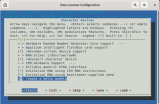
在meta-myir-remi/recipes-images/images/myir-image-full.bb里面添加我们需要的软件包。
我们只需要在IMAGE_INSTALL后面参考添加需要的软件包。
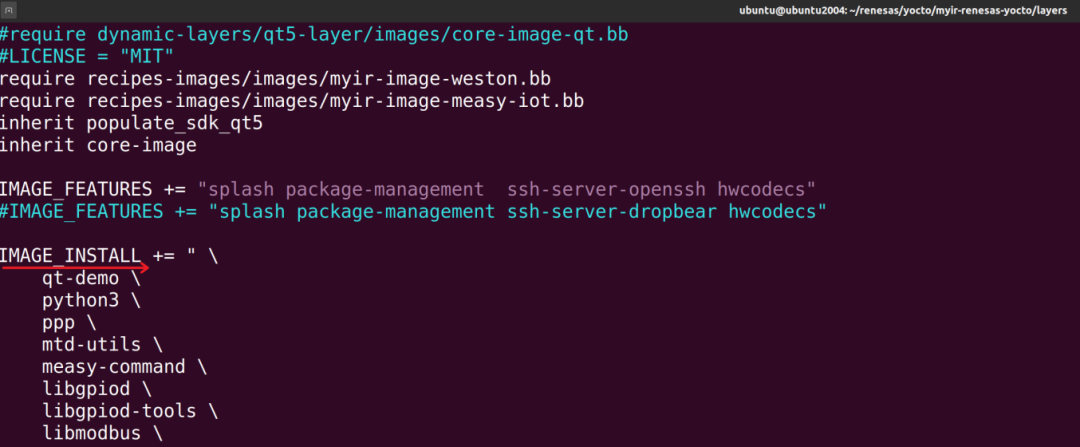
参考下图所示,在最底部增加一个lsusb软件包,增加完成后,保存退出即可。
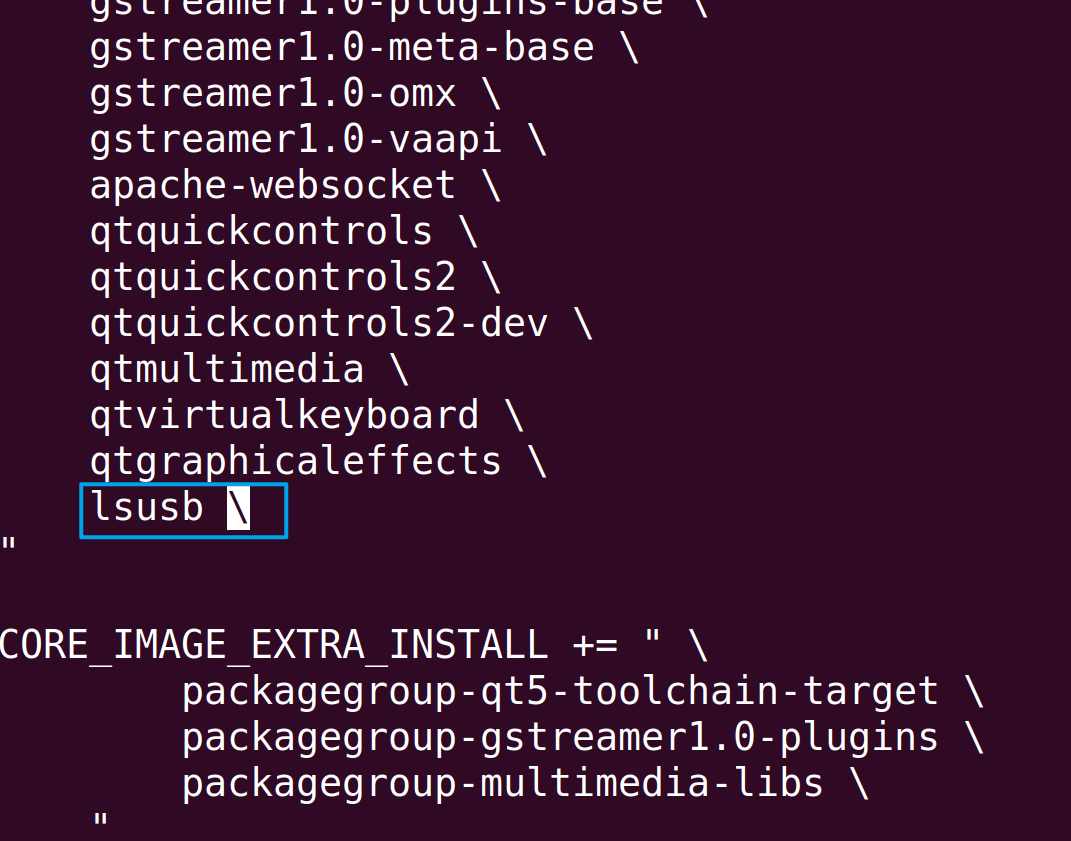
再次回到编译空间~/renesas/yocto/myir-renesas-yocto/build-remi-1g目录内,执行bitbake myir-image-full-k命令就可以自动将我们增加的lsusb编译至最终系统内。
14.7.2 自定义本地bb软件包
Yocto中一个软件包是放在bb文件中的,然后很多的bb 文件集成一个recipe(配方),然后许多的recipe又组成一个meta layer,因此,要添加一个包其实就是在recipe下面添加一个bb(bitbake配置文件)。下面使用helloworld作为一个例子。
1
创建hello bb文件
例如下面就是到了meta-myir-remi layer里面找到一个名为recipes-demo配方增加我们的hello bb文件。
一个软件包的结构使用tree可以看到,其有一个bb文件,然后其中还有一个目录放着Makefile与source code:

2
bb文件内容
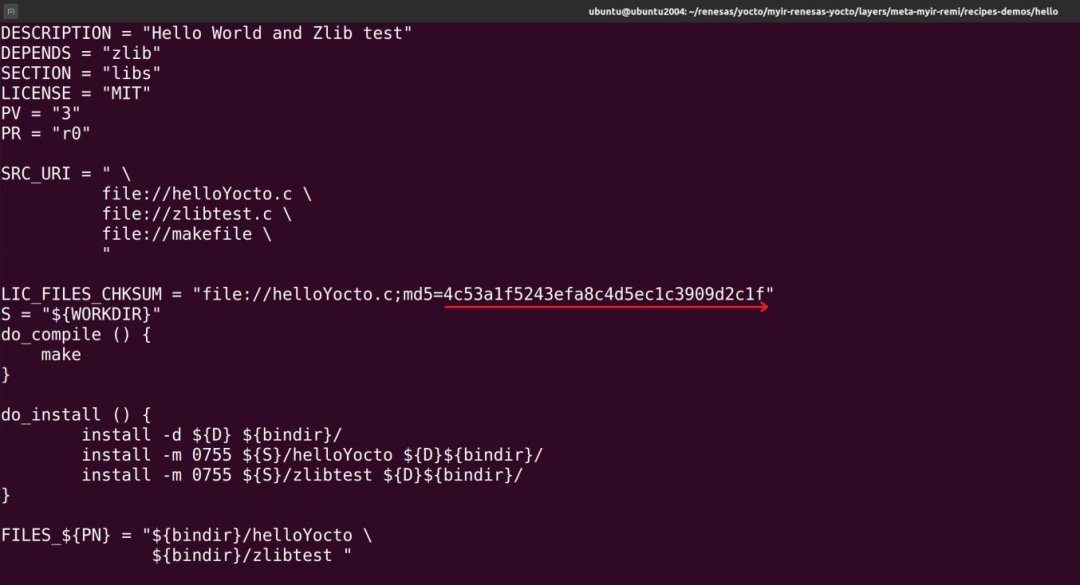
其中的bb文件内容如下:
左右滑动查看完整内容
DESCRIPTION = "Hello World and Zlib test" DEPENDS = "zlib" SECTION = "libs" LICENSE = "MIT" PV = "3" PR = "r0" SRC_URI = " file://helloYocto.c file://zlibtest.c file://makefile " LIC_FILES_CHKSUM = "file://helloYocto.c;md5=4c53a1f5243efa8c4d5ec1c3909d2c1f" S = "${WORKDIR}" do_compile () { make } do_install () { install -d ${D}/usr/bin install -m 0755 ${S}/helloYocto ${D}/usr/bin install -m 0755 ${S}/zlibtest ${D}/usr/bin } FILES_${PN} = " /usr/bin "
可以看到,bb文件中指定了下面几个变量的值:
SRC_URI
LIC_FILES_CHKSUM:这个是checksum,如果是基于版本管理的source,那么不需要,例如git 与svn
FILES_$(PN):PN是Package number,指代软件版本使用的PV与PR结合表示,即前面bitbake -s中看到的3-r0
还有两个方法,这2个方法重载了bitbake中默认方法:
do_compile
do_install
这两个方法,对应了Package中的compile与install task。
3
应用程序编写
左右滑动查看完整内容
ubuntu@ubuntu2004:~/renesas/yocto/myir-renesas-yocto/layers/meta-myir-remi/recipes-d emos/hello$ cd hello/ ubuntu@ubuntu2004:~/renesas/yocto/myir-renesas-yocto/layers/meta-myir-remi/recipes-d emos/hello/hello$ ls helloYocto.c makefile zlibtest.c
左右滑动查看完整内容
ubuntu@ubuntu2004:~/renesas/yocto/myir-renesas-yocto/layers/meta-myir-remi/recipes-d emos/hello/hello$ cat helloYocto.c #include#include #include int main(int argc,char *argv[]) { printf("Hello World Yocto-SDK !!!"); return 0; }
左右滑动查看完整内容
ubuntu@ubuntu2004:~/renesas/yocto/myir-renesas-yocto/layers/meta-myir-remi/recipes-d emos/hello/hello$ cat makefile TARGET=helloYocto zlibtest LDFLAGS= -lz all: $(TARGET) helloYocto: helloYocto.o $(CC) $(CFLAGS) -o $@ $^ zlibtest: zlibtest.o $(CC) $(CFLAGS1) -o $@ $^ $(LDFLAGS) clean: rm -f $(OBJS) $(TARGET)
左右滑动查看完整内容
ubuntu@ubuntu2004:~/renesas/yocto/myir-renesas-yocto/layers/meta-myir-remi/recipes-d emos/hello/hello$ cat zlibtest.c /* gun.c -- simple gunzip to give an example of the use of inflateBack() * Copyright (C) 2003, 2005, 2008, 2010, 2012 Mark Adler * For conditions of distribution and use, see copyright notice in zlib.h Version 1.7 12 August 2012 Mark Adler */ /* Version history: 1.0 16 Feb 2003 First version for testing of inflateBack() 1.1 21 Feb 2005 Decompress concatenated gzip streams Remove use of "this" variable (C++ keyword) Fix return value for in() Improve allocation failure checking
左右滑动查看完整内容
Add typecasting for void * structures Add -h option for command version and usage Add a bunch of comments 1.2 20 Mar 2005 Add Unix compress (LZW) decompression Copy file attributes from input file to output file 1.3 12 Jun 2005 Add casts for error messages [Oberhumer] 1.4 8 Dec 2006 LZW decompression speed improvements 1.5 9 Feb 2008 Avoid warning in latest version of gcc 1.6 17 Jan 2010 Avoid signed/unsigned comparison warnings 1.7 12 Aug 2012 Update for z_const usage in zlib 1.2.8 */ /* gun [ -t ] [ name ... ] decompresses the data in the named gzip files. If no arguments are given, gun will decompress from stdin to stdout. The names must end in .gz, -gz, .z, -z, _z, or .Z. The uncompressed data will be written to a file name with the suffix stripped. On success, the original file is deleted. On failure, the output file is deleted. For most failures, the command will continue to process the remaining names on the command line. A memory allocation failure will abort the command. If -t is specified, then the listed files or stdin will be tested as gzip files for integrity (without checking for a proper suffix), no output will be written, and no files will be deleted. Like gzip, gun allows concatenated gzip streams and will decompress them, writing all of the uncompressed data to the output. Unlike gzip, gun allows an empty file on input, and will produce no error writing an empty output file. gun will also decompress files made by Unix compress, which uses LZW compression. These files are automatically detected by virtue of their magic header bytes. Since the end of Unix compress stream is marked by the end-of-file, they cannot be concantenated. If a Unix compress stream is encountered in an input file, it is the last stream in that file. Like gunzip and uncompress, the file attributes of the orignal compressed file are maintained in the final uncompressed file, to the extent that the user permissions allow it. On my Mac OS X PowerPC G4, gun is almost twice as fast as gunzip (version 1.2.4) is on the same file, when gun is linked with zlib 1.2.2. Also the LZW decompression provided by gun is about twice as fast as the standard Unix uncompress command. */ /* external functions and related types and constants */ #include/* fprintf() */ #include /* malloc(), free() */ #include /* strerror(), strcmp(), strlen(), memcpy() */ #include /* errno */ #include /* open() */ #include /* read(), write(), close(), chown(), unlink() */ #include #include /* stat(), chmod() */
左右滑动查看完整内容
#include/* utime() */ #include "zlib.h" /* inflateBackInit(), inflateBack(), */ /* inflateBackEnd(), crc32() */ /* function declaration */ #define local static /* buffer constants */ #define SIZE 32768U /* input and output buffer sizes */ #define PIECE 16384 /* limits i/o chunks for 16-bit int case */ /* structure for infback() to pass to input function in() -- it maintains the input file and a buffer of size SIZE */ struct ind { int infile; unsigned char *inbuf; }; /* Load input buffer, assumed to be empty, and return bytes loaded and a pointer to them. read() is called until the buffer is full, or until it returns end-of-file or error. Return 0 on error. */ local unsigned in(void *in_desc, z_const unsigned char **buf) { int ret; unsigned len; unsigned char *next; struct ind *me = (struct ind *)in_desc; next = me->inbuf; *buf = next; len = 0; do { ret = PIECE; if ((unsigned)ret > SIZE - len) ret = (int)(SIZE - len); ret = (int)read(me->infile, next, ret); if (ret == -1) { len = 0; break; } next += ret; len += ret; } while (ret != 0 && len < SIZE); return len; } /* structure for infback() to pass to output function out() -- it maintains the output file, a running CRC-32 check on the output and the total number of bytes output, both for checking against the gzip trailer. (The length in the gzip trailer is stored modulo 2^32, so it's ok if a long is 32 bits and the output is greater than 4 GB.) */ struct outd { int outfile; int check; /* true if checking crc and total */ unsigned long crc; unsigned long total;
左右滑动查看完整内容
};
/* Write output buffer and update the CRC-32 and total bytes written. write()
is called until all of the output is written or an error is encountered.
On success out() returns 0. For a write failure, out() returns 1. If the
output file descriptor is -1, then nothing is written.
*/
local int out(void *out_desc, unsigned char *buf, unsigned len)
{
int ret;
struct outd *me = (struct outd *)out_desc;
if (me->check) {
me->crc = crc32(me->crc, buf, len);
me->total += len;
}
if (me->outfile != -1)
do {
ret = PIECE;
if ((unsigned)ret > len)
ret = (int)len;
ret = (int)write(me->outfile, buf, ret);
if (ret == -1)
return 1;
buf += ret;
len -= ret;
} while (len != 0);
return 0;
}
/* next input byte macro for use inside lunpipe() and gunpipe() */
#define NEXT() (have ? 0 : (have = in(indp, &next)),
last = have ? (have--, (int)(*next++)) : -1)
/* memory for gunpipe() and lunpipe() --
the first 256 entries of prefix[] and suffix[] are never used, could
have offset the index, but it's faster to waste the memory */
unsigned char inbuf[SIZE]; /* input buffer */
unsigned char outbuf[SIZE]; /* output buffer */
unsigned short prefix[65536]; /* index to LZW prefix string */
unsigned char suffix[65536]; /* one-character LZW suffix */
unsigned char match[65280 + 2]; /* buffer for reversed match or gzip
32K sliding window */
/* throw out what's left in the current bits byte buffer (this is a vestigial
aspect of the compressed data format derived from an implementation that
made use of a special VAX machine instruction!) */
#define FLUSHCODE()
do {
left = 0;
rem = 0;
if (chunk > have) {
chunk -= have;
have = 0;
if (NEXT() == -1)
break;
左右滑动查看完整内容
chunk--;
if (chunk > have) {
chunk = have = 0;
break;
}
}
have -= chunk;
next += chunk;
chunk = 0;
} while (0)
/* Decompress a compress (LZW) file from indp to outfile. The compress magic
header (two bytes) has already been read and verified. There are have bytes
of buffered input at next. strm is used for passing error information back
to gunpipe().
lunpipe() will return Z_OK on success, Z_BUF_ERROR for an unexpected end of
file, read error, or write error (a write error indicated by strm->next_in
not equal to Z_NULL), or Z_DATA_ERROR for invalid input.
*/
local int lunpipe(unsigned have, z_const unsigned char *next, struct ind *indp,
int outfile, z_stream *strm)
{
int last; /* last byte read by NEXT(), or -1 if EOF */
unsigned chunk; /* bytes left in current chunk */
int left; /* bits left in rem */
unsigned rem; /* unused bits from input */
int bits; /* current bits per code */
unsigned code; /* code, table traversal index */
unsigned mask; /* mask for current bits codes */
int max; /* maximum bits per code for this stream */
unsigned flags; /* compress flags, then block compress flag */
unsigned end; /* last valid entry in prefix/suffix tables */
unsigned temp; /* current code */
unsigned prev; /* previous code */
unsigned final; /* last character written for previous code */
unsigned stack; /* next position for reversed string */
unsigned outcnt; /* bytes in output buffer */
struct outd outd; /* output structure */
unsigned char *p;
/* set up output */
outd.outfile = outfile;
outd.check = 0;
/* process remainder of compress header -- a flags byte */
flags = NEXT();
if (last == -1)
return Z_BUF_ERROR;
if (flags & 0x60) {
strm->msg = (char *)"unknown lzw flags set";
return Z_DATA_ERROR;
}
max = flags & 0x1f;
if (max < 9 || max > 16) {
strm->msg = (char *)"lzw bits out of range";
左右滑动查看完整内容
return Z_DATA_ERROR;
}
if (max == 9) /* 9 doesn't really mean 9 */
max = 10;
flags &= 0x80; /* true if block compress */
/* clear table */
bits = 9;
mask = 0x1ff;
end = flags ? 256 : 255;
/* set up: get first 9-bit code, which is the first decompressed byte, but
don't create a table entry until the next code */
if (NEXT() == -1) /* no compressed data is ok */
return Z_OK;
final = prev = (unsigned)last; /* low 8 bits of code */
if (NEXT() == -1) /* missing a bit */
return Z_BUF_ERROR;
if (last & 1) { /* code must be < 256 */
strm->msg = (char *)"invalid lzw code";
return Z_DATA_ERROR;
}
rem = (unsigned)last >> 1; /* remaining 7 bits */
left = 7;
chunk = bits - 2; /* 7 bytes left in this chunk */
outbuf[0] = (unsigned char)final; /* write first decompressed byte */
outcnt = 1;
/* decode codes */
stack = 0;
for (;;) {
/* if the table will be full after this, increment the code size */
if (end >= mask && bits < max) {
FLUSHCODE();
bits++;
mask <<= 1;
mask++;
}
/* get a code of length bits */
if (chunk == 0) /* decrement chunk modulo bits */
chunk = bits;
code = rem; /* low bits of code */
if (NEXT() == -1) { /* EOF is end of compressed data */
/* write remaining buffered output */
if (outcnt && out(&outd, outbuf, outcnt)) {
strm->next_in = outbuf; /* signal write error */
return Z_BUF_ERROR;
}
return Z_OK;
}
code += (unsigned)last << left; /* middle (or high) bits of code */
left += 8;
chunk--;
if (bits > left) { /* need more bits */
if (NEXT() == -1) /* can't end in middle of code */
左右滑动查看完整内容
return Z_BUF_ERROR;
code += (unsigned)last << left; /* high bits of code */
left += 8;
chunk--;
}
code &= mask; /* mask to current code length */
left -= bits; /* number of unused bits */
rem = (unsigned)last >> (8 - left); /* unused bits from last byte */
/* process clear code (256) */
if (code == 256 && flags) {
FLUSHCODE();
bits = 9; /* initialize bits and mask */
mask = 0x1ff;
end = 255; /* empty table */
continue; /* get next code */
}
/* special code to reuse last match */
temp = code; /* save the current code */
if (code > end) {
/* Be picky on the allowed code here, and make sure that the code
we drop through (prev) will be a valid index so that random
input does not cause an exception. The code != end + 1 check is
empirically derived, and not checked in the original uncompress
code. If this ever causes a problem, that check could be safely
removed. Leaving this check in greatly improves gun's ability
to detect random or corrupted input after a compress header.
In any case, the prev > end check must be retained. */
if (code != end + 1 || prev > end) {
strm->msg = (char *)"invalid lzw code";
return Z_DATA_ERROR;
}
match[stack++] = (unsigned char)final;
code = prev;
}
/* walk through linked list to generate output in reverse order */
p = match + stack;
while (code >= 256) {
*p++ = suffix[code];
code = prefix[code];
}
stack = p - match;
match[stack++] = (unsigned char)code;
final = code;
/* link new table entry */
if (end < mask) {
end++;
prefix[end] = (unsigned short)prev;
suffix[end] = (unsigned char)final;
}
/* set previous code for next iteration */
prev = temp;
左右滑动查看完整内容
/* write output in forward order */
while (stack > SIZE - outcnt) {
while (outcnt < SIZE)
outbuf[outcnt++] = match[--stack];
if (out(&outd, outbuf, outcnt)) {
strm->next_in = outbuf; /* signal write error */
return Z_BUF_ERROR;
}
outcnt = 0;
}
p = match + stack;
do {
outbuf[outcnt++] = *--p;
} while (p > match);
stack = 0;
/* loop for next code with final and prev as the last match, rem and
left provide the first 0..7 bits of the next code, end is the last
valid table entry */
}
}
/* Decompress a gzip file from infile to outfile. strm is assumed to have been
successfully initialized with inflateBackInit(). The input file may consist
of a series of gzip streams, in which case all of them will be decompressed
to the output file. If outfile is -1, then the gzip stream(s) integrity is
checked and nothing is written.
The return value is a zlib error code: Z_MEM_ERROR if out of memory,
Z_DATA_ERROR if the header or the compressed data is invalid, or if the
trailer CRC-32 check or length doesn't match, Z_BUF_ERROR if the input ends
prematurely or a write error occurs, or Z_ERRNO if junk (not a another gzip
stream) follows a valid gzip stream.
*/
local int gunpipe(z_stream *strm, int infile, int outfile)
{
int ret, first, last;
unsigned have, flags, len;
z_const unsigned char *next = NULL;
struct ind ind, *indp;
struct outd outd;
/* setup input buffer */
ind.infile = infile;
ind.inbuf = inbuf;
indp = &ind;
/* decompress concatenated gzip streams */
have = 0; /* no input data read in yet */
first = 1; /* looking for first gzip header */
strm->next_in = Z_NULL; /* so Z_BUF_ERROR means EOF */
for (;;) {
/* look for the two magic header bytes for a gzip stream */
if (NEXT() == -1) {
ret = Z_OK;
左右滑动查看完整内容
break; /* empty gzip stream is ok */
}
if (last != 31 || (NEXT() != 139 && last != 157)) {
strm->msg = (char *)"incorrect header check";
ret = first ? Z_DATA_ERROR : Z_ERRNO;
break; /* not a gzip or compress header */
}
first = 0; /* next non-header is junk */
/* process a compress (LZW) file -- can't be concatenated after this */
if (last == 157) {
ret = lunpipe(have, next, indp, outfile, strm);
break;
}
/* process remainder of gzip header */
ret = Z_BUF_ERROR;
if (NEXT() != 8) { /* only deflate method allowed */
if (last == -1) break;
strm->msg = (char *)"unknown compression method";
ret = Z_DATA_ERROR;
break;
}
flags = NEXT(); /* header flags */
NEXT(); /* discard mod time, xflgs, os */
NEXT();
NEXT();
NEXT();
NEXT();
NEXT();
if (last == -1) break;
if (flags & 0xe0) {
strm->msg = (char *)"unknown header flags set";
ret = Z_DATA_ERROR;
break;
}
if (flags & 4) { /* extra field */
len = NEXT();
len += (unsigned)(NEXT()) << 8;
if (last == -1) break;
while (len > have) {
len -= have;
have = 0;
if (NEXT() == -1) break;
len--;
}
if (last == -1) break;
have -= len;
next += len;
}
if (flags & 8) /* file name */
while (NEXT() != 0 && last != -1)
;
if (flags & 16) /* comment */
while (NEXT() != 0 && last != -1)
;
左右滑动查看完整内容
if (flags & 2) { /* header crc */
NEXT();
NEXT();
}
if (last == -1) break;
/* set up output */
outd.outfile = outfile;
outd.check = 1;
outd.crc = crc32(0L, Z_NULL, 0);
outd.total = 0;
/* decompress data to output */
strm->next_in = next;
strm->avail_in = have;
ret = inflateBack(strm, in, indp, out, &outd);
if (ret != Z_STREAM_END) break;
next = strm->next_in;
have = strm->avail_in;
strm->next_in = Z_NULL; /* so Z_BUF_ERROR means EOF */
/* check trailer */
ret = Z_BUF_ERROR;
if (NEXT() != (int)(outd.crc & 0xff) ||
NEXT() != (int)((outd.crc >> 8) & 0xff) ||
NEXT() != (int)((outd.crc >> 16) & 0xff) ||
NEXT() != (int)((outd.crc >> 24) & 0xff)) {
/* crc error */
if (last != -1) {
strm->msg = (char *)"incorrect data check";
ret = Z_DATA_ERROR;
}
break;
}
if (NEXT() != (int)(outd.total & 0xff) ||
NEXT() != (int)((outd.total >> 8) & 0xff) ||
NEXT() != (int)((outd.total >> 16) & 0xff) ||
NEXT() != (int)((outd.total >> 24) & 0xff)) {
/* length error */
if (last != -1) {
strm->msg = (char *)"incorrect length check";
ret = Z_DATA_ERROR;
}
break;
}
/* go back and look for another gzip stream */
}
/* clean up and return */
return ret;
}
/* Copy file attributes, from -> to, as best we can. This is best effort, so
no errors are reported. The mode bits, including suid, sgid, and the sticky
bit are copied (if allowed), the owner's user id and group id are copied
左右滑动查看完整内容
(again if allowed), and the access and modify times are copied. */
local void copymeta(char *from, char *to)
{
struct stat was;
struct utimbuf when;
/* get all of from's Unix meta data, return if not a regular file */
if (stat(from, &was) != 0 || (was.st_mode & S_IFMT) != S_IFREG)
return;
/* set to's mode bits, ignore errors */
(void)chmod(to, was.st_mode & 07777);
/* copy owner's user and group, ignore errors */
(void)chown(to, was.st_uid, was.st_gid);
/* copy access and modify times, ignore errors */
when.actime = was.st_atime;
when.modtime = was.st_mtime;
(void)utime(to, &when);
}
/* Decompress the file inname to the file outnname, of if test is true, just
decompress without writing and check the gzip trailer for integrity. If
inname is NULL or an empty string, read from stdin. If outname is NULL or
an empty string, write to stdout. strm is a pre-initialized inflateBack
structure. When appropriate, copy the file attributes from inname to
outname.
gunzip() returns 1 if there is an out-of-memory error or an unexpected
return code from gunpipe(). Otherwise it returns 0.
*/
local int gunzip(z_stream *strm, char *inname, char *outname, int test)
{
int ret;
int infile, outfile;
/* open files */
if (inname == NULL || *inname == 0) {
inname = "-";
infile = 0; /* stdin */
}
else {
infile = open(inname, O_RDONLY, 0);
if (infile == -1) {
fprintf(stderr, "gun cannot open %s
", inname);
return 0;
}
}
if (test)
outfile = -1;
else if (outname == NULL || *outname == 0) {
outname = "-";
outfile = 1; /* stdout */
}
else {
左右滑动查看完整内容
outfile = open(outname, O_CREAT | O_TRUNC | O_WRONLY, 0666);
if (outfile == -1) {
close(infile);
fprintf(stderr, "gun cannot create %s
", outname);
return 0;
}
}
errno = 0;
/* decompress */
ret = gunpipe(strm, infile, outfile);
if (outfile > 2) close(outfile);
if (infile > 2) close(infile);
/* interpret result */
switch (ret) {
case Z_OK:
case Z_ERRNO:
if (infile > 2 && outfile > 2) {
copymeta(inname, outname); /* copy attributes */
unlink(inname);
}
if (ret == Z_ERRNO)
fprintf(stderr, "gun warning: trailing garbage ignored in %s
",
inname);
break;
case Z_DATA_ERROR:
if (outfile > 2) unlink(outname);
fprintf(stderr, "gun data error on %s: %s
", inname, strm->msg);
break;
case Z_MEM_ERROR:
if (outfile > 2) unlink(outname);
fprintf(stderr, "gun out of memory error--aborting
");
return 1;
case Z_BUF_ERROR:
if (outfile > 2) unlink(outname);
if (strm->next_in != Z_NULL) {
fprintf(stderr, "gun write error on %s: %s
",
outname, strerror(errno));
}
else if (errno) {
fprintf(stderr, "gun read error on %s: %s
",
inname, strerror(errno));
}
else {
fprintf(stderr, "gun unexpected end of file on %s
",
inname);
}
break;
default:
if (outfile > 2) unlink(outname);
fprintf(stderr, "gun internal error--aborting
");
return 1;
}
return 0;
}
左右滑动查看完整内容
/* Process the gun command line arguments. See the command syntax near the
beginning of this source file. */
int main(int argc, char **argv)
{
int ret, len, test;
char *outname;
unsigned char *window;
z_stream strm;
/* initialize inflateBack state for repeated use */
window = match; /* reuse LZW match buffer */
strm.zalloc = Z_NULL;
strm.zfree = Z_NULL;
strm.opaque = Z_NULL;
ret = inflateBackInit(&strm, 15, window);
if (ret != Z_OK) {
fprintf(stderr, "gun out of memory error--aborting
");
return 1;
}
/* decompress each file to the same name with the suffix removed */
argc--;
argv++;
test = 0;
if (argc && strcmp(*argv, "-h") == 0) {
fprintf(stderr, "gun 1.6 (17 Jan 2010)
");
fprintf(stderr, "Copyright (C) 2003-2010 Mark Adler
");
fprintf(stderr, "usage: gun [-t] [file1.gz [file2.Z ...]]
");
return 0;
}
if (argc && strcmp(*argv, "-t") == 0) {
test = 1;
argc--;
argv++;
}
if (argc)
do {
if (test)
outname = NULL;
else {
len = (int)strlen(*argv);
if (strcmp(*argv + len - 3, ".gz") == 0 ||
strcmp(*argv + len - 3, "-gz") == 0)
len -= 3;
else if (strcmp(*argv + len - 2, ".z") == 0 ||
strcmp(*argv + len - 2, "-z") == 0 ||
strcmp(*argv + len - 2, "_z") == 0 ||
strcmp(*argv + len - 2, ".Z") == 0)
len -= 2;
else {
fprintf(stderr, "gun error: no gz type on %s--skipping
",
*argv);
continue;
}
outname = malloc(len + 1);
左右滑动查看完整内容
if (outname == NULL) {
fprintf(stderr, "gun out of memory error--aborting
");
ret = 1;
break;
}
memcpy(outname, *argv, len);
outname[len] = 0;
}
ret = gunzip(&strm, *argv, outname, test);
if (outname != NULL) free(outname);
if (ret) break;
} while (argv++, --argc);
else
ret = gunzip(&strm, NULL, NULL, test);
/* clean up */
inflateBackEnd(&strm);
return ret;
}
ubuntu@ubuntu2004:~/renesas/yocto/myir-renesas-yocto/layers/meta-myir-remi/recipes-d
emos/hello/hello$
4
单独编译
ubuntu@ubuntu2004:~/renesas/yocto/myir-renesas-yocto/build-remi-1g$ bitbake-v hello
5
解决错误
~/renesas/yocto/myir-renesas-yocto/layers/meta-myir-
remi/recipes-demos/hello/
ubuntu@ubuntu2004:~/renesas/yocto/myir-renesas-
yocto/layers/meta-myir-remi/recipes-demos/hello$ vi hello.bb
-
mcu
+关注
关注
147文章
19265浏览量
405342 -
MPU
+关注
关注
0文章
466浏览量
51667 -
瑞萨电子
+关注
关注
39文章
2990浏览量
74630 -
工业控制
+关注
关注
38文章
1724浏览量
92502 -
yocto
+关注
关注
0文章
10浏览量
5792
发布评论请先 登录
米尔RZ/T2H MPU支持支持多轴实时控制,助力工业以太网
请问在Multisim14中如何为MSP430添加程序啊?
数据库添加程序哪里
yocto项目添加程序和脚本的步骤简析

在RZ/T2M和RZ/N2L中Printf添加方法(使用查询模式实现UART)


工业MPU新标杆,多协议工业以太网+运动控制 - 瑞萨RZ/T2H 新产品




评论