 基于国产FPGA的运动控制加速卡
基于国产FPGA的运动控制加速卡

现阶段,大部分的工业运动控制平台和数控运动中的控制中心为PC端控制器,通过PC端控制器控制伺服驱动器,从而实现机械系统中一个或多个坐标上的运动以及运动之间的协调,实现精确的位置控制、速度和加速度控制、转矩和力的控制等。同时,PC端控制器还需要控制其他传感器或运动单元。这种PC端控制器直接控制上述设备的方案,存在效率低、难以做到指令发送或接收的同步处理、延时较大、采集的数据无法做到准确同步等问题。因此需要简化PC端控制器的数据通信量、降低指令延迟、提升控制效率,同时需要获取同步后的数据。中科亿海微研制的FPGA运动控制加速卡主要完成PC端与伺服驱动器、相机、压力及柔性传感器等模块之间的数据通信、数据融合与数据监测。FPGA运动控制加速卡将复杂的控制卸载到FPGA中实现,简化了PC端控制器的控制流程,极大地减小了数据链路通信时间消耗。同时FPGA将同步后的数据发送到PC处理,使得数据处理流程更合理。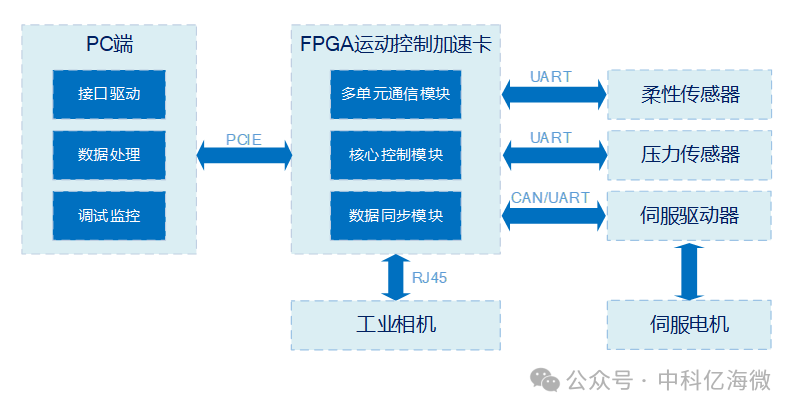
图 基于FPGA的运动控制加速方案系统构成框图
基于FPGA的运动控制加速方案主要由两块板卡构成:以EQ6HL130为核心的同步采集板、以EQ6HL9为核心的柔性传感器采集板。
以EQ6HL130为核心的同步采集板控制伺服驱动器,产生驱动控制伺服电机的指令,同时接收其应答指令,将指令解析处理后结果传输给PC端控制器作进一步操作;接收柔性传感器采集器采集的数据,解析后传输给控制器;接收压力传感器的数据,解析后传输给控制器。对所有接收数据打上时间戳,便于后续使用。
以EQ6HL9为核心的柔性传感器采集板通过AD采集柔性传感器的数据并组帧传输给同步采集板控制;将采集数据转换为压力值显示到显示屏上。
FPGA运动控制加速卡经测试,PC端控制器方案的系统指令延迟大于50ms。基于FPGA的运动控制加速方案的系统指令延迟小于100us,同时伺服电机应答数据、多传感器数据、相机数据能做到完全同步,更具使用意义。
-
FPGA
+关注
关注
1664文章
22504浏览量
639308 -
驱动器
+关注
关注
54文章
9116浏览量
156522 -
控制器
+关注
关注
114文章
17879浏览量
195162 -
运动控制
+关注
关注
5文章
839浏览量
34671
发布评论请先 登录
选择AMD Alveo V80加速卡的五大理由
AMD Alveo MA35D媒体加速卡的AMA SDK 1.4.0版本发布
FPGA硬件加速卡设计原理图:1-基于Xilinx XCKU115的半高PCIe x8 硬件加速卡 PCIe半高 XCKU115-3-FLVF1924-E芯片

推理<2ms!Ultralytics最新YOLO26+树莓派+国产AI加速卡实现 500 FPS 端侧 AI 性能巅峰!

新品 | LLM-8850 Kit,高性能AI加速卡套件 DinMeter v1.1,1/32DIN标准嵌入式开发板
高速信号处理设计方案:413-基于双XCVU9P+C6678的100G光纤加速卡

昆仑芯R200 AI加速卡技术规格解析

迈向云端算力巅峰:昆仑芯K200 AI加速卡全面解读

深圳光量子工厂启示:PCI 加速卡为何偏向 25MHz 2016 有源晶振?

算力密度翻倍!江原D20加速卡发布,一卡双芯重构AI推理标杆

虚拟电厂加速卡不是噱头!万点规模VPP的性能分水岭
智算加速卡是什么东西?它真能在AI战场上干掉GPU和TPU!


边缘AI运算革新 DeepX DX-M1 AI加速卡结合Rockchip RK3588多路物体检测解决方案




评论