 OpenVINO™助力谷歌大语言模型Gemma实现高速智能推理
OpenVINO™助力谷歌大语言模型Gemma实现高速智能推理

大型语言模型(LLM)正在迅速发展,变得更加强大和高效,使人们能够在广泛的应用程序中越来越复杂地理解和生成类人文本。谷歌的Gemma是一个轻量级、先进的开源模型新家族,站在LLM创新的前沿。然而,对更高推理速度和更智能推理能力的追求并不仅仅局限于复杂模型的开发,它扩展到模型优化和部署技术领域。
OpenVINO 工具套件因此成为一股引人注目的力量,在这些领域发挥着越来越重要的作用。这篇博客文章深入探讨了优化谷歌的Gemma模型,并在不足千元的AI开发板上进行模型部署、使用OpenVINO 加速推理,将其转化为能够更快、更智能推理的AI引擎。
此文使用了研扬科技针对边缘AI行业开发者推出的哪吒(Nezha)开发套件,以信用卡大小(85x56mm)的开发板-哪吒(Nezha)为核心,哪吒采用Intel N97处理器(Alder Lake-N),最大睿频3.6GHz,Intel UHD Graphics内核GPU,可实现高分辨率显示;板载LPDDR5内存、eMMC存储及TPM 2.0,配备GPIO接口,支持Windows和Linux操作系统,这些功能和无风扇散热方式相结合,为各种应用程序构建高效的解决方案,适用于如自动化、物联网网关、数字标牌和机器人等应用。
什么是Gemma?
Gemma是谷歌的一个轻量级、先进的开源模型家族,采用了与创建Gemini模型相同的研究和技术。它们以拉丁语单词 “Gemma” 命名,意思是“宝石”,是文本到文本的、仅解码器架构的LLM,有英文版本,具有开放权重、预训练变体和指令调整变体。Gemma模型非常适合各种文本生成任务,包括问答、摘要和推理。
Gemma模型系列,包括Gemma-2B和Gemma-7B模型,代表了深度学习模型可扩展性和性能的分层方法。在本次博客中,我们将展示OpenVINO 如何优化和加速Gemma-2B-it模型的推理,即Gemma-2B参数模型的指令微调后的版本。
利用OpenVINO 优化和加速推理
优化、推理加速和部署的过程包括以下具体步骤,使用的是我们常用的OpenVINO Notebooks GitHub仓库 中的254-llm-chatbot代码示例。
由安装必要的依赖包开始
运行OpenVINO Notebooks仓库的具体安装指南在这里。运行这个254-llm-chatbot的代码示例,需要安装以下必要的依赖包。
选择推理的模型
由于我们在Jupyter Notebook演示中提供了一组由OpenVINO 支持的LLM,您可以从下拉框中选择 “Gemma-2B-it” 来运行该模型的其余优化和推理加速步骤。当然,很容易切换到 “Gemma-7B-it” 和其他列出的型号。
使用Optimum Intel实例化模型
Optimum Intel是Hugging Face Transformers和Diffuser库与OpenVINO 之间的接口,用于加速Intel体系结构上的端到端流水线。接下来,我们将使用Optimum Intel从Hugging Face Hub加载优化模型,并创建流水线,使用Hugging Face API以及OpenVINO Runtime运行推理。在这种情况下,这意味着我们只需要将AutoModelForXxx类替换为相应的OVModelForXxx类。
权重压缩
尽管像Gemma-2B这样的LLM在理解和生成类人文本方面变得越来越强大和复杂,但管理和部署这些模型在计算资源、内存占用、推理速度等方面带来了关键挑战,尤其是对于这种不足千元级的AI开发板等客户端设备。权重压缩算法旨在压缩模型的权重,可用于优化模型体积和性能。
我们的Jupyter笔记本电脑使用Optimum Intel和NNCF提供INT8和INT4压缩功能。与INT8压缩相比,INT4压缩进一步提高了性能,但预测质量略有下降。因此,我们将在此处选择INT4压缩。

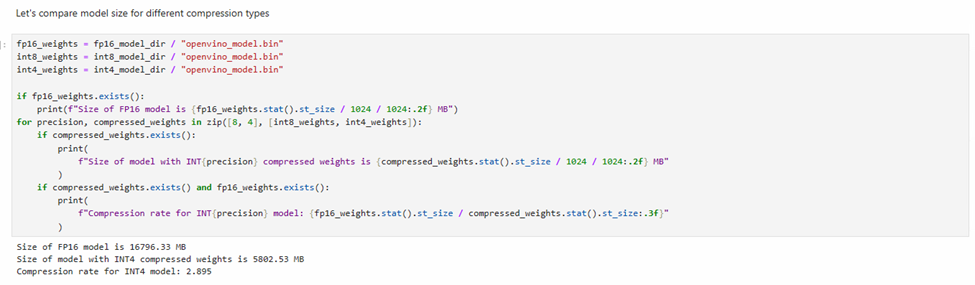
我们还可以比较模型权重压缩前后的模型体积变化情况。
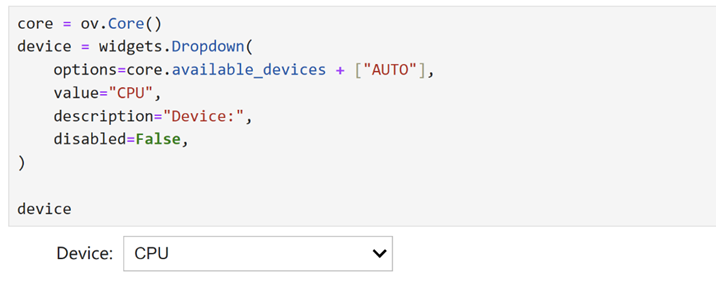
选择推理设备和模型变体
由于OpenVINO 能够在一系列硬件设备上轻松部署,因此还提供了一个下拉框供您选择将在其上运行推理的设备。考虑到内存使用情况,我们将选择CPU作为推理设备。
运行聊天机器人
现在万事具备,在这个Notebook代码示例中我们还提供了一个基于Gradio的用户友好的界面。现在就让我们把聊天机器人运行起来吧。
小结
整个的步骤就是这样!现在就开始跟着我们提供的代码和步骤,动手试试用OpenVINO 在哪吒开发板上运行基于大语言模型的聊天机器人吧。
审核编辑:刘清
-
处理器
+关注
关注
68文章
20333浏览量
255031 -
机器人
+关注
关注
213文章
31455浏览量
223678 -
物联网
+关注
关注
2950文章
48131浏览量
418529 -
GPIO
+关注
关注
16文章
1333浏览量
56459 -
OpenVINO
+关注
关注
0文章
118浏览量
818
原文标题:千元开发板,百万可能:OpenVINO™ 助力谷歌大语言模型Gemma实现高速智能推理 | 开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Google正式推出最新开放模型Gemma 4

谷歌推出TranslateGemma全新开放翻译模型系列
解锁谷歌FunctionGemma模型的无限潜力

晶晨携手谷歌,助力端侧大模型Gemini的硬件落地
谷歌正式发布Gemma Scope 2模型
LLM推理模型是如何推理的?

谷歌推出AI模型Gemma 3 270M
谷歌Gemma 3n模型的新功能



评论