 NVIDIA AI Foundation Models:使用生产就绪型 LLM 构建自定义企业聊天机器人和智能副驾
NVIDIA AI Foundation Models:使用生产就绪型 LLM 构建自定义企业聊天机器人和智能副驾


大语言模型(LLM)正在彻底变革数据科学,带来自然语言理解、AI 和机器学习的高级功能。为洞悉特定领域而定制的自定义 LLM 在企业应用中越来越受到青睐。
NVIDIA Nemotron-3 8B系列基础模型是一套功能强大的全新工具,可用于为企业构建生产就绪生成式 AI 应用,从而推动从客服 AI 聊天机器人到尖端 AI 产品的各种创新。
这些新的基础模型现已加入NVIDIA NeMo。这个端到端框架用于构建、自定义和部署专为企业定制的 LLM。企业现在可以使用这些工具快速且经济高效地大规模开发 AI 应用。这些应用可在云端、数据中心以及 Windows PC 和笔记本电脑上运行。
Nemotron-3 8B 系列现已在 Azure AI Model 目录、HuggingFace 和NVIDIA NGC 目录上的NVIDIA AI Foundation Model中心提供。该系列包含基本模型、聊天模型和问答(Q&A)模型,可解决各种下游任务。表 1 列出了该系列的所有模型。
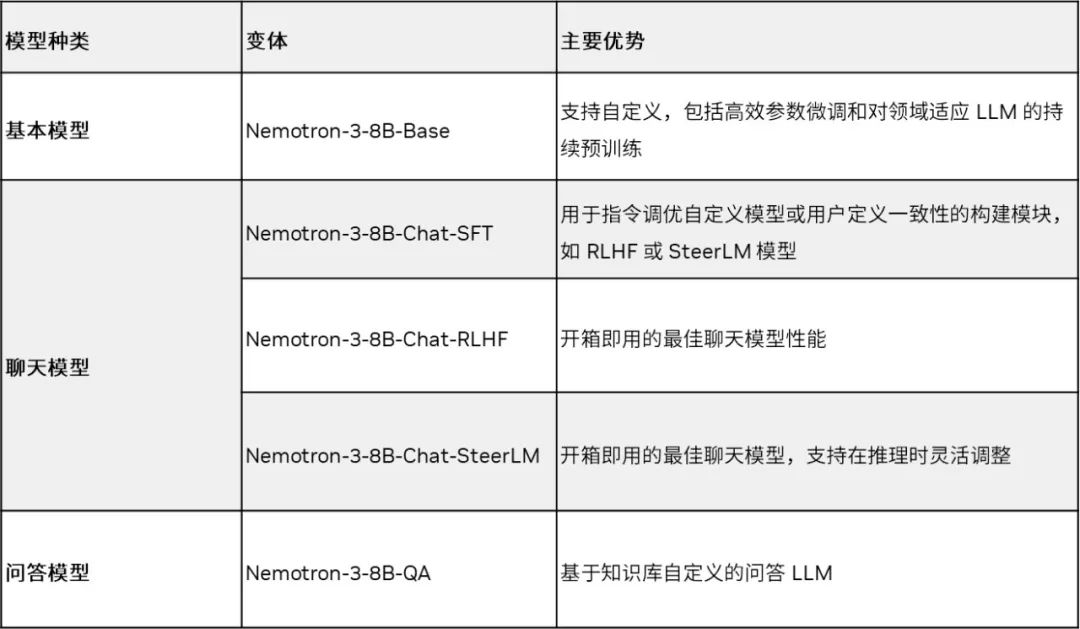
表 1. Nemotron-3 8B 系列基础模型支持多种 LLM 用例
设计用于生产的基础模型
基础模型是强大的构建模块,它减少了构建实用的自定义应用所需的时间和资源。然而,企业机构必须确保这些模型符合其具体需求。
NVIDIA AI Foundation Models 基于来源可靠的数据集训练而成,集合了无数声音和体验。严格监控确保了数据的真实性,并符合不断变化发展的法律规定。任何出现的数据问题都会迅速得到解决,确保企业的 AI 应用既符合法律规范,又能保护用户隐私。这些模型既能吸收公开数据集,也能兼容专有数据集。
Nemotron-3-8B 基本模型
Nemotron-3-8B 基本模型是一种用于生成类人文本或代码的紧凑型高性能模型。该模型的 MMLU 5 样本平均值为 54.4。该基本模型还精通 53 种语言,包括英语、德语、俄语、西班牙语、法语、日语、中文、意大利语和荷兰语,因此能满足跨国企业对多语言能力的需求。该基本模型还经过 37 种不同编码语言的训练。
Nemotron-3-8B 聊天模型
该套件还添加了 Nemotron-3-8B 聊天模型,用于 LLM 驱动的聊天机器人交互。Nemotron-3-8B 聊天模型有三个版本,每个版本均针对特定用户的独特调整而设计:
-
监督微调(SFT)
-
人类反馈强化学习(RLHF)
-
NVIDIA SteerLM(https://blogs.nvidia.com/blog/2023/10/11/customize-ai-models-steerlm/)
Nemotron-3-8B-SFT 模型是指令微调的第一步,我们在此基础上建立了 RLHF 模型,该模型是 8B 类别中 MT-Bench 分数最高的模型(MT-Bench 是最常用的聊天质量指标)。用户可以从使用 8B-chat-RLHF 开始,以获得最佳的即时聊天互动效果。但对于希望与最终用户的偏好保持一致的企业,可以在使用 SFT 模型的同时,应用自己的 RLHF。
最后,最新的对齐方法 SteerLM 为训练和自定义推理 LLM 提供了新的灵活性。借助 SteerLM,用户可以定义其所需的所有属性,并将其嵌入单个模型中,然后就可以在该模型运行时为特定用例选择其所需的组合。
这种方法支持持续的改进周期。自定义模型响应可以作为未来训练的数据,从而将模型的实用性提升到新的水平。
Nemotron-3-8B 问答模型
Nemotron-3-8B-QA 模型是一个问答(QA)模型,该模型在大量数据基础上针对目标用例进行微调。
Nemotron-3-8B-QA 模型的性能一流,在 Natural Questions 数据集(https://ai.google.com/research/NaturalQuestions/)上实现了 41.99% 的零样本 F1 分数。该指标用于衡量生成的答案与问答中真实答案的相似程度。
Nemotron-3-8B-QA 模型已与其他参数规模更大的先进语言模型进行了对比测试。测试是在 NVIDIA 创建的数据集以及 Natural Questions 和 Doc2Dial 数据集上进行的。结果表明,该模型具有良好的性能。
使用 NVIDIA NeMo 框架
构建自定义 LLM
NVIDIA NeMo 通过为多种模型架构提供端到端功能和容器化方案,简化了构建自定义企业生成式 AI 模型的路径。借助 Nemotron-3-8B 系列模型,开发者就可以使用 NVIDIA 提供的预训练模型,这些模型可以轻松适应特定用例。
快速模型部署
使用 NeMo 框架时,无需收集数据或设置基础架构。NeMo 精简了这一过程。开发者可以自定义现有模型,并将其快速部署到生产中。
最佳模型性能
此外,它还与NVIDIA TensorRT-LLM开源库和NVIDIA Triton 推理服务器无缝集成,前者可优化模型性能,后者可加速推理服务流程。这种工具组合实现了最先进的准确性、低延迟和高吞吐量。
数据隐私和安全
NeMo 可实现安全、高效的大规模部署,并符合相关安全法规规定。例如,如果数据隐私是业务的关键问题,就可以使用NeMo Guardrails在不影响性能或可靠性的情况下安全存储客户数据。
总之,使用 NeMo 框架构建自定义 LLM 是在不牺牲质量或安全标准的情况下、快速创建企业 AI 应用的有效方法。它为开发者提供了自定义灵活性,同时提供了大规模快速部署所需的强大工具。
开始使用 Nemotron-3-8B
您可以使用 NeMo 框架在 Nemotron-3-8B 模型上轻松运行推理,该框架充分利用 TensorRT-LLM 开源库,可在NVIDIA GPU上为高效和轻松的 LLM 推理提供高级优化。它内置了对各种优化技术的支持,包括:
-
KV caching
-
Efficient Attention modules (including MQA, GQA, and Paged Attention)
-
In-flight (or continuous) batching
-
支持低精度(INT8/FP8)量化以及其他优化
NeMo 框架推理容器包含在 NeMo 模型(如 Nemotron-3-8B 系列)上应用 TensorRT-LLM 优化所需的所有脚本和依赖项,并将它们托管在 Triton 推理服务器上。部署完成后,它可以开放一个端点,供您发送推理查询。
在 Azure ML 上的部署步骤
Nemotron-3-8B 系列模型可在 Azure ML 模型目录中获得,以便部署到 Azure ML 管理的端点中。AzureML 提供了易于使用的“无代码部署”流程,使部署 Nemotron-3-8B 系列模型变得非常容易。该平台已集成了作为 NeMo 框架推理容器的底层管道。
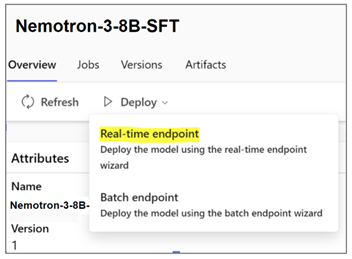
图 1. 在 Azure ML 中选择实时端点
如要在 Azure ML 上部署 NVIDIA 基础模型并进行推理,请按照以下步骤操作:
-
登录 Azure 账户:https://portal.azure.com/#home
-
导航至 Azure ML 机器学习工作室
-
选择您的工作区,并导航至模型目录
NVIDIA AI Foundation 模型可在 Azure 上进行微调、评估和部署,还可以在 Azure ML 中使用 NeMo 训练框架对这些模型进行自定义。NeMo 框架由训练和推理容器组成,已集成在 AzureML 中。
如要微调基本模型,请选择您喜欢的模型变体,单击“微调”,填写任务类型、自定义训练数据、训练和验证分割以及计算集群等参数。
如要部署该模型,请选择您喜欢的模型变体,单击“实时端点”,选择实例、端点和其他用于自定义部署的参数。单击“部署”,将推理模型部署到端点。
Azure CLI 和 SDK 支持也可用于在 Azure ML 上运行微调作业和部署。详细信息请参见“Azure ML 中的 Foundation Models”文档。
在本地或其他云上的部署步骤
Nemotron-3-8B 系列模型具有独特的推理请求提示模板,建议将其作为最佳实践。但由于它们共享相同的基本架构,因此其部署说明很相似。
有关使用 NeMo 框架推理容器的最新部署说明,参见:https://registry.ngc.nvidia.com/orgs/ea-bignlp/teams/ga-participants/containers/nemofw-inference。
为了演示,让我们部署 Nemotron-3-8B-Base-4k。
1. 登录 NGC 目录,获取推理容器。
# log in to your NGC organization
docker login nvcr.io
# Fetch the NeMo framework inference container
docker pull nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10
2. 下载 Nemotron-3-8B-Base-4k 模型。8B 系列模型可在 NGC 目录和 Hugging Face 上获得,您可以选择其中一个下载模型。
NVIDIA NGC
从 NGC 下载模型最简单的方法是使用 CLI。如果您没有安装 NGC CLI,请按照入门指南(https://docs.ngc.nvidia.com/cli/cmd.html#getting-started-with-the-ngc-cli)进行安装和配置。
# Downloading using CLI. The model path can be obtained from it’s page on NGC
ngc registry model download-version "dztrnjtldi02/nemotron-3-8b-base-4k:1.0"
Hugging Face Hub
以下指令使用的是 git-lfs,您也可以使用 Hugging Face 支持的任何方法下载模型。
git lfs install
git clone https://huggingface.co/nvidia/nemotron-3-8b-base-4knemotron-3-8b-base-4k_v1.0
3.在交互模式下运行 NeMo 推理容器,安装相关路径
# Create a folder to cache the built TRT engines. This is recommended so they don’t have to be built on every deployment call.
mkdir -p trt-cache
# Run the container, mounting the checkpoint and the cache directory
docker run --rm --net=host
--gpus=all
-v $(pwd)/nemotron-3-8b-base-4k_v1.0:/opt/checkpoints/
-v $(pwd)/trt-cache:/trt-cache
-w /opt/NeMo
-it nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10 bash
4. 在 Triton 推理服务器上使用 TensorRT-LLM 后端转换并部署该模型。
python scripts/deploy/deploy_triton.py
--nemo_checkpoint /opt/checkpoints/Nemotron-3-8B-Base-4k.nemo
--model_type="gptnext"
--triton_model_name Nemotron-3-8B-4K
--triton_model_repository /trt-cache/
--max_input_len 3000
--max_output_len 1000
--max_batch_size 2
当该指令成功完成后,就会显示一个可以查询的端点。让我们来看看如何做到这一点。
运行推理的步骤
有几种运行推理的方法可供选择,取决于您希望如何集成该服务:
1. 使用 NeMo 框架推理容器中的 NeMo 客户端 API
2. 使用 PyTriton 在您的环境中创建一个客户端应用
3. 鉴于所部署的服务会开放一个 HTTP 端点,使用任何可以发送 HTTP 请求的程序资源库/工具。
选项 1(使用 NeMo 客户端 API)的示例如下。您可以在同一台设备上的 NeMo 框架推理容器中使用,也可以在能访问服务 IP 和端口的不同设备上使用。
from nemo.deploy import NemoQuery
# In this case, we run inference on the same machine
nq = NemoQuery(url="localhost:8000", model_name="Nemotron-3-8B-4K")
output = nq.query_llm(prompts=["The meaning of life is"], max_output_token=200, top_k=1, top_p=0.0, temperature=0.1)
print(output)
其他选项示例可以在该推理容器的 README 中找到。
8B 系列模型指令
NVIDIA Nemotron-3-8B 系列中的模型:所有 NVIDIA Nemotron-3-8B 数据集共享预训练基础,但用于调优聊天(SFT、RLHF、SteerLM)和问答模型的数据集是根据其特定目的自定义的。此外,构建上述模型还采用了不同的训练技术,因此这些模型在使用与训练模板相似的定制指令时最为有效。
这些模型的推荐指令模板位于各自的模型卡上。
例如,以下是适用于 Nemotron-3-8B-Chat-SFT 和 Nemotron-3-8B-Chat-RLHF 模型的单轮和多轮格式:

指令和回复字段与输入内容相对应。下面是一个使用单轮模板设置输入格式的示例。
PROMPT_TEMPLATE = """System
{system}
User
{prompt}
Assistant
"""
system = ""
prompt = "Write a poem on NVIDIA in the style of Shakespeare"
prompt = PROMPT_TEMPLATE.format(prompt=prompt, system=system)
print(prompt)
注意:对于 Nemotron-3-8B-Chat-SFT 和 Nemotron-3-8B-Chat-RLHF 模型,我们建议保持系统提示为空。
进一步训练和自定义
NVIDIA Nemotron-3-8B 模型系列适用于针对特定领域数据集的进一步定制。对此有几种选择,例如继续从检查点进行预训练、SFT 或高效参数微调、使用 RLHF 校准人类演示或使用 NVIDIA 全新 SteerLM 技术。
NeMo 框架训练容器提供了上述技术的易用脚本。我们还提供了各种工具,方便您进行数据整理、识别用于训练和推理的最佳超参数,以及在您选择的硬件(本地 DGX 云、支持 Kubernetes 的平台或云服务提供商)上运行 NeMo 框架的工具。
更多信息,参见 NeMo 框架用户指南(https://docs.nvidia.com/nemo-framework/user-guide/latest/index.html)或容器 README(https://registry.ngc.nvidia.com/orgs/ea-bignlp/containers/nemofw-training)。
Nemotron-3-8B 系列模型专为各种用例而设计,不仅在各种基准测试中表现出色,还支持多种语言。
GTC 2024 将于 2024 年 3 月 18 至 21 日在美国加州圣何塞会议中心举行,线上大会也将同期开放。点击“阅读原文”或扫描下方海报二维码,立即注册 GTC 大会。
原文标题:NVIDIA AI Foundation Models:使用生产就绪型 LLM 构建自定义企业聊天机器人和智能副驾
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
23文章
4113浏览量
99598
原文标题:NVIDIA AI Foundation Models:使用生产就绪型 LLM 构建自定义企业聊天机器人和智能副驾
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
MCUXpresso SDK创建自定义清单
NVIDIA 携手全球机器人领导者,将物理 AI 带入现实世界

NVIDIA 发布开放物理 AI 数据工厂 Blueprint,加速机器人、视觉 AI 智能体和智能汽车开发

Microchip 推出生产就绪型全栈边缘 AI 解决方案,赋能MCU和MPU实现 智能实时决策

基于NVIDIA模组与软件套件推动边缘与机器人AI推理
使用OpenUSD与NVIDIA Halos构建安全物理AI系统
NVIDIA推出面向语言、机器人和生物学的全新开源AI技术
智能硬件通过小聆AI自定义MCP应用开发操作讲解
NVIDIA RTX AI PC为AnythingLLM加速本地AI工作流
KiCad 中的自定义规则(KiCon 演讲)
HarmonyOS应用自定义键盘解决方案
小智 AI 聊天机器人 (XiaoZhi AI Chatbot)

机器人领域领先企业利用NVIDIA技术实现工业AI
NVIDIA 通过云端至机器人计算平台驱动人形机器人技术,赋能物理 AI



评论