 Stanford编译原理详解
Stanford编译原理详解

第二部分的作业是语法分析,通过编写cool.y(这个assignment的任务),利用bison将其自动生成语法分析LALR(1)的代码。
语法分析,就是将词法分析阶段已经识别好的token,按照语法的规则,构建抽象语法树的过程。
比如以下的代码:
x=(a+b)*(c-d);
可以构成下图的抽象语法树:
=
/
x *
/
+ -
/ /
abcd
具体在cool.y 中,

这部分定义了非终结符non-terminal对应的semanticvalue. Union中的每一个field都可以是parsing动作的结果。
在stanfordcompiler的教学语言cool中,这就对应了AST的一个node。每一个non-terminal,都有其对应的semanticvalue。
左侧的各种类型在cool-tree.aps中都有对应定义,比如Features:
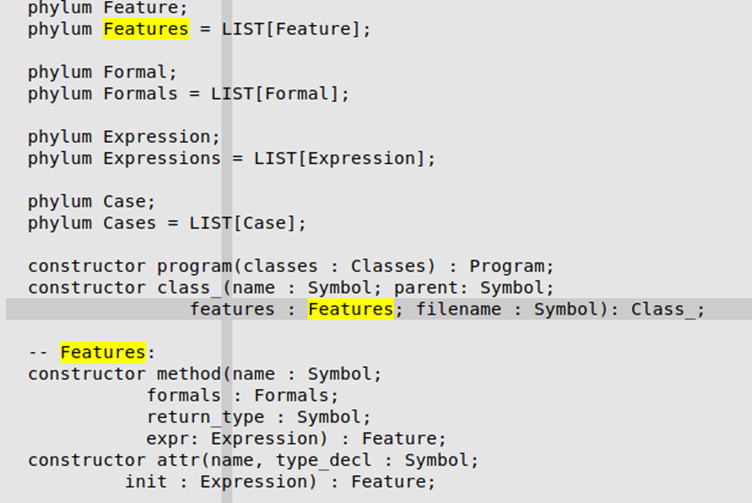
Feature即为class中的成员函数或者成员变量。因为可以有多个Feature,所以存在Features,即LIST[Feature].
下面则具体定义了所有的非终结符对应的AST节点类型。<>内部的,比如classes是在union中定义的value,而右侧的,比如class_list,我们需要定义规约该非终结符时,需要进行的操作。
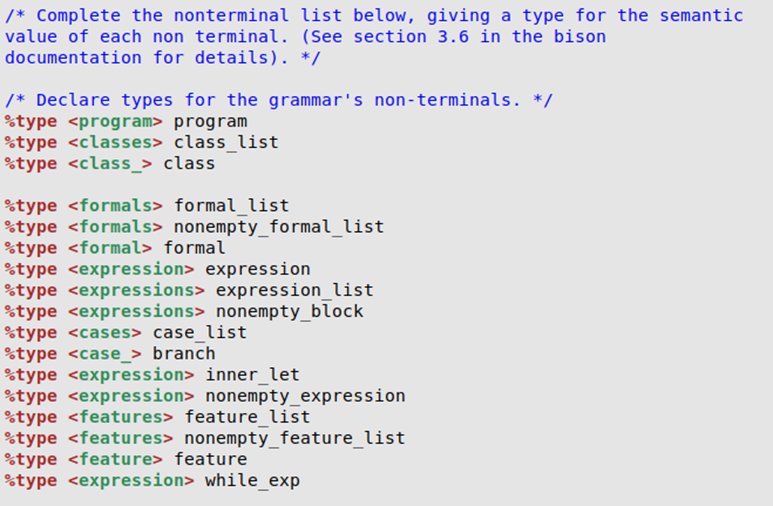
上图中$$即为action的返回值,对应该抽象语法树AST对应的node。
下面介绍如何声明非终结符对应的规约操作。

具体如何对类的声明构建抽象语法树节点,即class的规则:
1)
CLASS TYPEID '{' feature_list '}' ';'
{
/*对应动作 action*/
$$=class_($2,
idtable.add_string("Object"),
$4,
stringtable.add_string(curr_filename));
}
其动作对应cool-tree.aps中生命的constructor,

传给class_的参数即为
1)类名称 2)父类名称 3)成员变量/成员函数
4)文件名
对应的位置如类名称即为TYPEID,对应$2, feature_list对应$4,因此其动作action写成了如上图所示的样子。
cool语法中,如果class类没有继承自其他类,那么默认继承自Object类型,因此parent设置为Object。
2)
CLASS TYPEID INHERITS TYPEID '{' feature_list '}' ';'
{$$=class_($2,$4,$6,
stringtable.add_string(curr_filename));}
这里唯一不同的即为该类继承自父类,因此其第2个参数,父类名称传入了$4。具体的序号可以参考第205行的注释。
审核编辑:汤梓红
-
函数
+关注
关注
3文章
4421浏览量
67826 -
代码
+关注
关注
30文章
4976浏览量
74373 -
编译
+关注
关注
0文章
696浏览量
35279
原文标题:Stanford 编译原理 编程作业2
文章出处:【微信号:处理器与AI芯片,微信公众号:处理器与AI芯片】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一文详解SystemC仿真库的编译

一文详解编译系统
WinCE系统的编译过程详解
Vivado中的Incremental Compile增量编译技术详解
Linux内核编译过程详解
编译器是如何工作的_编译器的工作过程详解

Php+mysql+apache编译安装详述

详解OpenHarmony的编译和烧录
C语言中条件编译详解
Stanford编译的原理是什么?
斯坦福(Stanford)锁相放大器故障修复





评论