 Arm最强处理器架构技术解析
Arm最强处理器架构技术解析

知名媒体nextplatform表示,仍在仔细研究最近在同一时间举行的 Hot Interconnects、Hot Chips、Google Cloud Next 和 Meta Networking @ Scale 会议上的大量演示。他们打算采取通常的、有条理的方法来寻找有趣的部分并对我们所听到和看到的内容进行一些分析。
这一次,其将目光投向了即将重新上市的 Arm Ltd. 正式推出的“Demeter”Neoverse V2 内核。
如果 Demeter 核心设计发生在五年前,或者更好的是十年前,这将是一件非常大的事情,因为对于许多想要制造 Arm 服务器芯片的组织来说,设计好的核心非常困难。正如今年 Hot Chips 发布的“Genesis”计算子系统 (CSS) 所示,设计一款好的处理器也许也很困难。超大规模厂商和云构建者一直想做的是针对其工作负载大量定制处理器,而不是设计处理器。大型企业有时也希望如此,并且具有特定工作负载需求的各种规模的企业类别也希望如此。
但处理器销售商(并非所有销售商都是制造商,也并非所有制造商都是销售商)无法提供大规模定制,因为每一代制造多个变体的成本非常昂贵。我们确实看到的变化实际上是关于打开和关闭一些设计中固有的功能,这是由硅片部分的良率所迫使的,因为它是通过功率门控功能人为地创建变化并收取零件费用。
Demeter 核心是第一个实现 2021 年 3 月宣布的 Armv9 架构的核心,是迄今为止 Arm 为服务器设计的最好的核心,这就是为什么 Nvidia 能够仅授权该核心和其他组件其72 核“Grace”服务器 CPU,它是 Nvidia 系统架构不可或缺的一部分,支持传统 HPC 仿真和建模工作负载的全 CPU 计算,并提供辅助内存和计算能力。凭借四个 128 位 SVE2 矢量引擎,Demeter 核心肯定会有一个强大的引擎来运行经典的 HPC 工作负载以及某些 AI 推理工作负载(那些不太胖的工作负载,可能不包括大多数LLM),甚至可能是在某些情况下重新训练人工智能模型。如果设计中可能有 16 到 256 个内核,那么触发器当然可以堆叠起来。
我们只是想知道除了 Nvidia 之外,还有谁会在他们的 CPU 设计中使用 Demeter 核心。
AWS 很可能会在其未来的 Graviton4 服务器处理器中采用 V2 内核,并在其当前的 Graviton3 处理器中使用“Zeus”V1 内核。
目前尚不清楚谷歌在传闻中正在开发的一对定制 Arm 服务器芯片中使用了什么内核——其中一个是与 Marvell 合作,如果传闻属实的话,另一个是与自己的团队合作——但如果我们知道的话,我们也不会感到惊讶。其中之一是使用 V2 内核。
AmpereComputing 已在其 192 核“Siryn”AmpereOne 芯片中从 Arm 的“Ares”N1 内核切换为自己的内核(我们称之为 A1)。
印度高级计算发展中心 (C-DAC) 正在为 HPC 工作负载构建自己的“Aum”处理器,并且它基于Arm的Neoverse V1核心。
正如我们之前指出的,富士通、Arm 和日本 RIKEN 实验室联合为“Fugaku”超级计算机使用的48 核 A64FX 处理器打造的定制 Arm 内核中的 512 位向量可以被视为一种Neoverse V0 核心在于 SVE 设计最初是为 A64FX 创建的。
我们还想知道,除了Arm在Hot Chips 2023上推出的N2核心芯片之外,为什么没有立即推出基于V2核心的CSS服务器芯片设计。为什么CSS设计中不能同时使用N2和V2核心呢?我们意识到一些数据中心运营商需要更多的性价比优化,并且认为他们不需要那么多向量;软件和工作负载是否正确还有待观察。
但 AWS 选择 V1 和 Nvidia 选择 V2 是一个非常有力的指标。AmpereComputing计算 A1 核心在矢量方面更像是 N2 核心,有两个 128 位引擎,因此云上胖矢量核心的这种行为并不普遍。
V2 就像火箭
Arm 于 2020 年 9 月将其 Neoverse 核心和 CPU 设计分为三部分,将 V 系列高性能核心(具有双倍向量引擎)从主线 N 系列核心(专注于整数性能)中分离出来,并添加到 E 系列(入门级)重点关注能源效率和边缘的芯片。多年来,该路线图已经扩展和更新了很多次,最新的路线图(带有 N2 平台添加的 CSS 子系统变体)已在 Hot Chips 上展示:
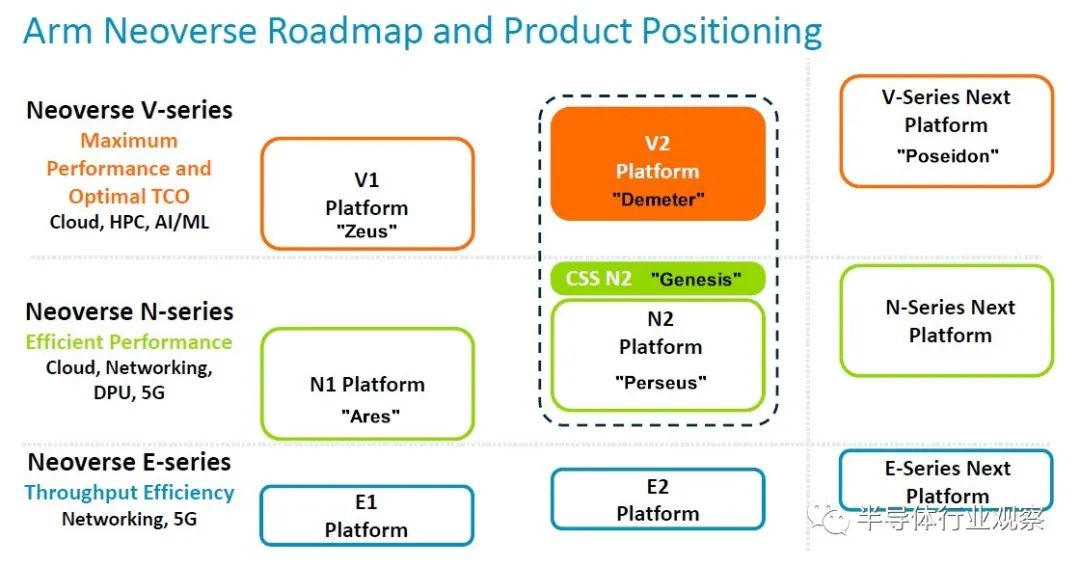
我们在我们熟悉的核心和平台代号中添加了它们,因为我们喜欢同义词。
Arm 院士兼首席 CPU 架构师 Magnus Bruce 在 Hot Chips 上介绍了 V2 平台,谈论了该架构以及与 Zeus V1 平台相比的变化。这张图表很好地总结了这一点:
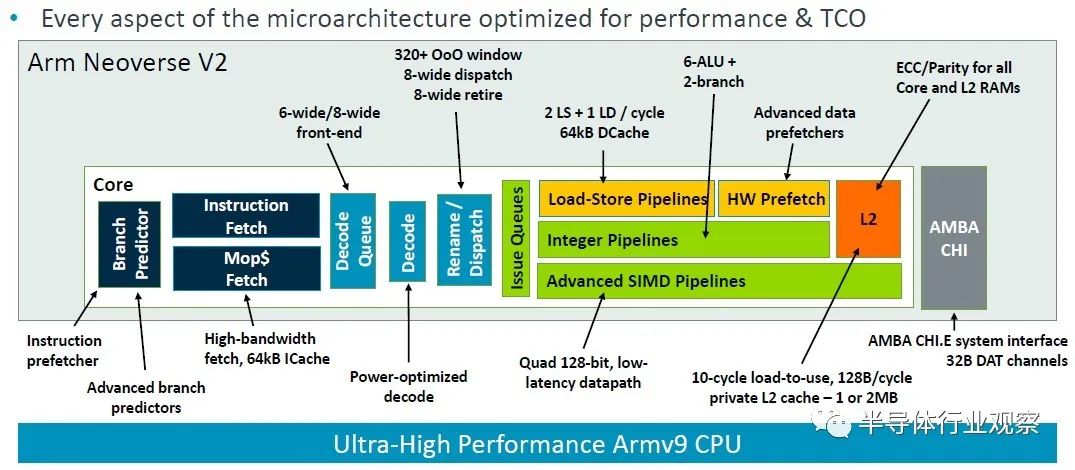
“这个管道的基础是一个提前运行分支预测器,这个分支预测器充当指令预取器,它将提取与分支分离,”Bruce解释道。“大型分支预测结构可以覆盖非常大的现实服务器工作负载。我们使用在发出后读取的物理寄存器文件,允许非常大的发出队列,而无需存储数据的负担。这是解锁 ILP [指令级并行性]。我们使用低延迟和私有 L2 缓存、低延迟 L1 和私有 L2 缓存以及最先进的预取算法和积极的存储到加载转发,以保持内核的气泡和停顿最少( bubbles and stalls)。系统的动态反馈机制允许内核调节攻击性并主动防止系统拥塞。这些基本概念使我们能够扩大机器的宽度和深度,同时保持快速错误预测恢复所需的短管道。”
重要的是,这是一个 Armv9 实现,它旨在颠覆该架构,与十多年来定义 Arm 芯片的多代 Armv8 架构相比,它带来了性能、安全性和可扩展性增强。
V2 芯片的架构调整很微妙,但显然很有效。但同样明显的是,13% 的性能提升距离 Arm 早在 2019 年设定的每时钟指令数 (IPC) 30% 的提升目标还有很长的路要走:
无论如何,这里是对 V2 核心的分支预测器和获取单元以及 L1 缓存的深入分析:

正如您所看到的,V1 核心的很多功能都转移到了 V2 核心,但 V2 核心也有一些更新。许多队列、表和带宽都增加了一倍,但微操作缓存实际上在转向 V2 设计时减少了。根据使用芯片模拟器为 V1 和 V2 建模的 SPEC CPU 2017 整数基准,对 V2 内核的调整使每个时钟指令增加了约 2.9%。
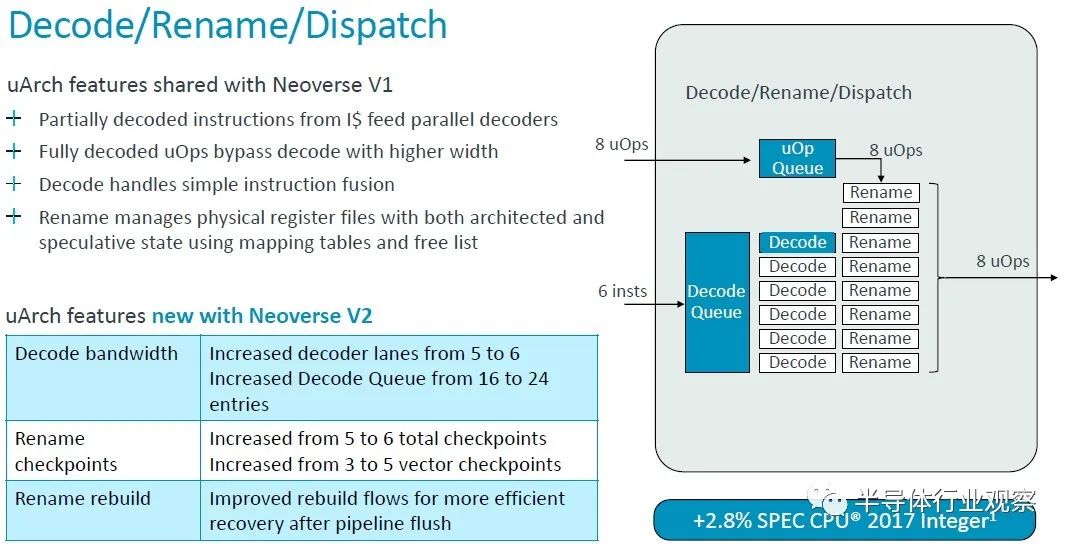
值得一提的是,V1 内核在解码和指令分派方面的一些微架构优点直接传递到 V2 内核,但解码器通道和队列有所提升。总体效果是 IPC 提高了 2.9%,这也是通过 SPEC CPU 2017 整数测试来衡量的。(IPC 通常是使用混合测试来计算的,而不仅仅是 SPEC CPU 评级。但这就是我们得到的。)
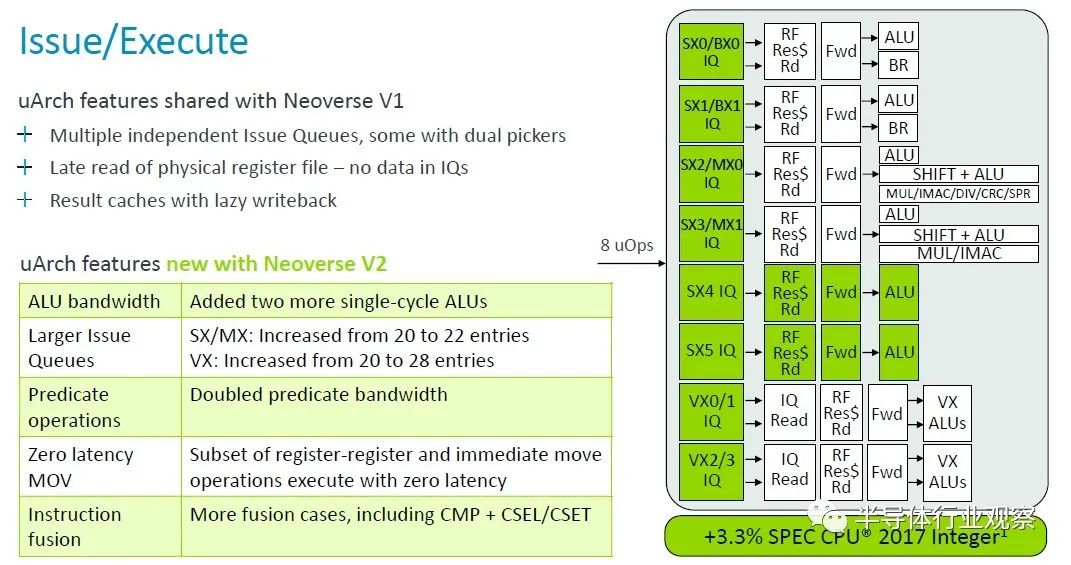
借助 V2 内核,Arm 架构师又添加了两个单周期算术逻辑单元 (ALU),并增加了问题队列的大小,并将谓词运算符的带宽加倍,这些调整加上其他一些调整,又增加了 3.3%核心性能在 2.8 GHz 下归一化。
与 V1 核心一样,V2 核心有两个加载/存储管道和一个加载管道,但表后备缓冲区 (TLB) 上的条目增加了 — 从 40 个条目增加到 48 个条目 — 并且各种存储和读取队列也增加了变得更大。
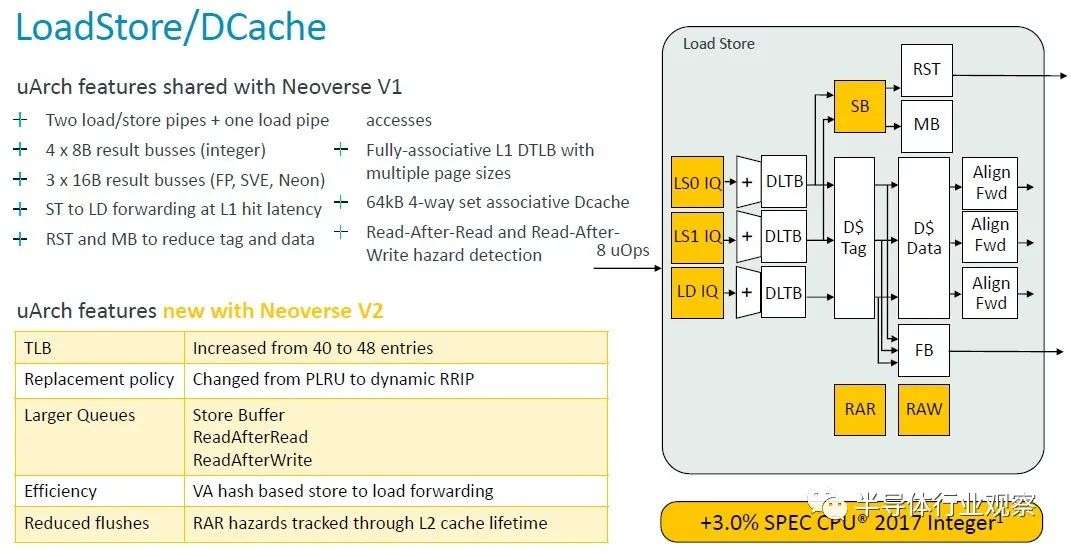
这一变化和其他变化使 V2 核心性能又增加了 3%。
Arm 架构师通过硬件预取数据的变化获得了最大的性能提升:
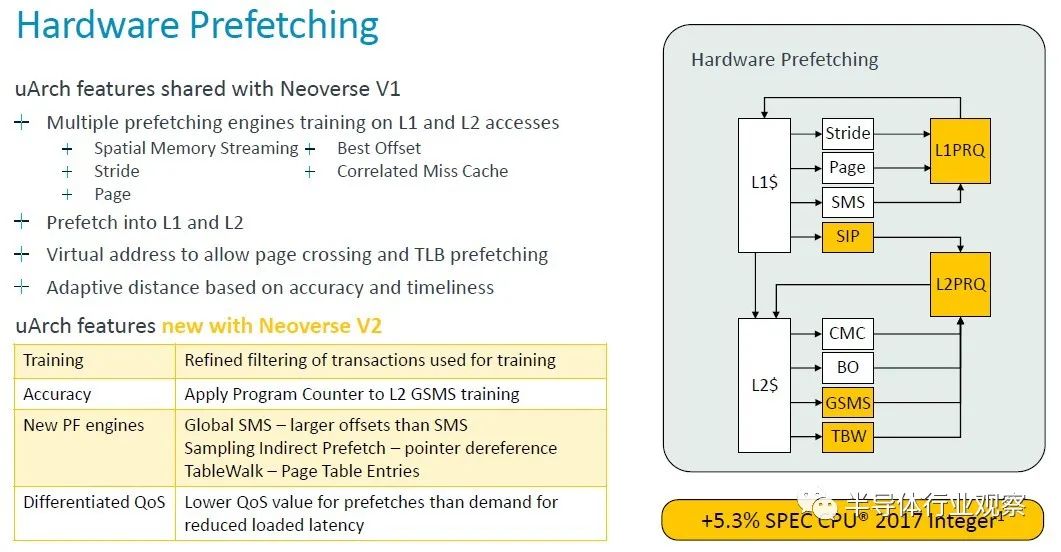
“Neoverse V1 已经具备了最先进的预取功能,”Bruce 解释道,我们将让他带您了解预取增强功能的低级解释。深吸一口气。。。。“通过对 L1 和 L2 misses进行多引擎训练并预取到 L1 和 L2 缓存中,我们的预取器通常使用虚拟地址来允许页面交叉(page crossing),这使得它们也可以充当 TLB 预取。预取器使用来自互连的动态反馈以及 CPU 内部的准确性和及时性测量来调节其主动性。
V2 建立在 V1 硬件的基础上,改进了训练,通过更好的过滤和训练操作提高准确性,并在更多预取器中使用程序计数器以实现更好的关联和更好地防止混叠。还添加了新的预取引擎。L2 获得了全局空间内存流引擎,增加了它可以覆盖的预取器的偏移范围,并且比旧的标准 SMS 引擎有了很大的改进。我们添加了一个采样间接预取器( sampling indirect prefetcher),用于处理指针解除引用场景。
这不是数据预测,而是学习数据消耗模式作为其他负载的指针。我们还添加了一个表遍历预取器(table walk prefetcher),可以将页表条目预取(page table entries)到二级缓存中。现在,所有这些添加的预取器及其攻击性都会造成系统拥塞。特别是在系统级缓存DRAM等共享资源上。我们为需求和预取提供差异化的 QoS 级别。这使我们能够进行积极的预取,而不会影响需求请求的加载延迟。
动态预取动态反馈将预取器的攻击性调节到可持续的水平。这些变化加起来使规格管理器增加了 5.3%,但更重要的是,我们同时看到 SLC 缺失减少了 8.2%,因此我们可以用更少的 DRAM 流量获得更高的性能。”
以下是二级缓存如何发挥其魔力:
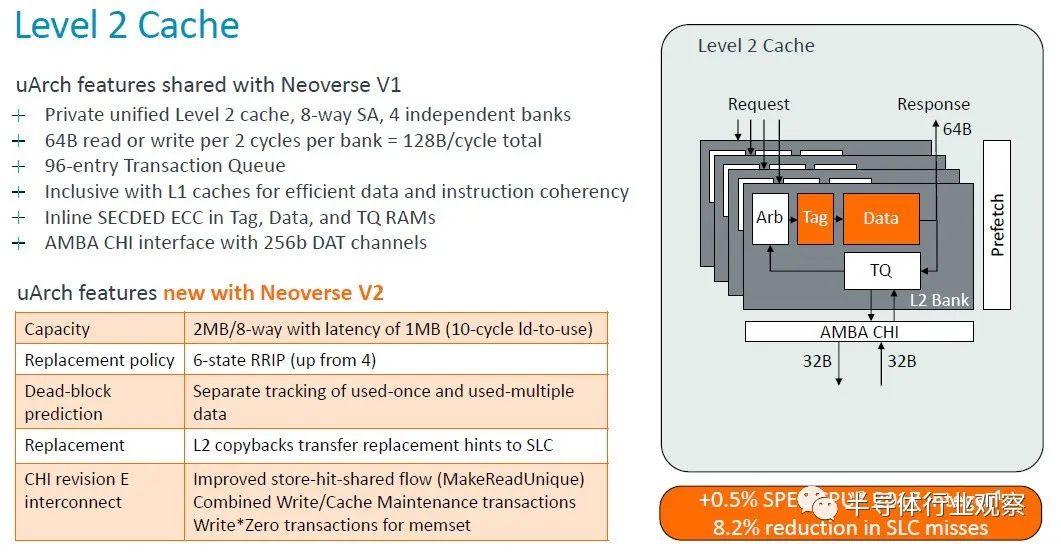
二级缓存加倍对性能来说并没有太大变化,但系统级缓存misses的减少确实间接提高了性能。
以下是 IPC 的总和:
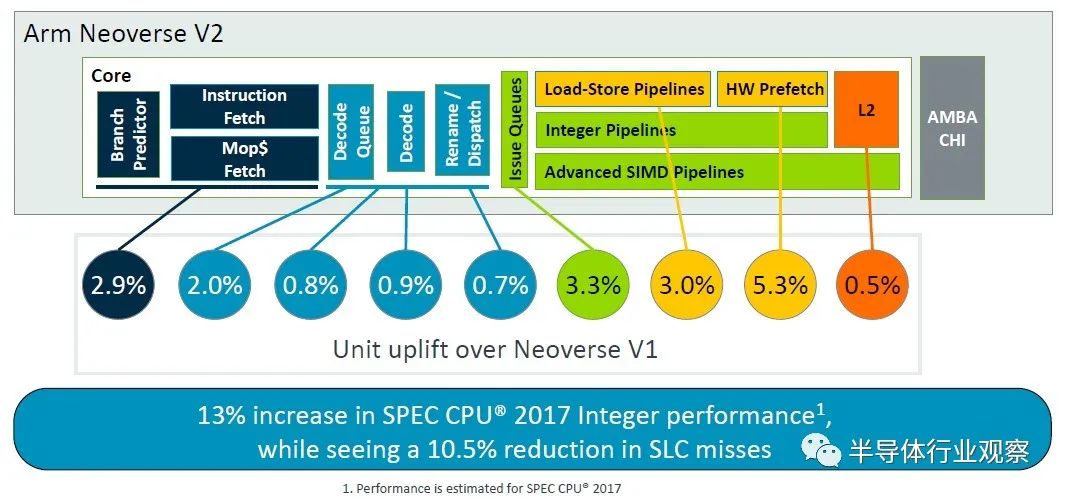
这些是加法效应,而不是乘法效应,V2 核心的整数性能提高了 13%——这也是经过建模的,而且这只是使用 SPEC CPU 2017 整数测试——同时将系统级缓存缺失减少了 10.5%总体百分比。
每当新的核心或芯片问世时,该核心或芯片都会根据性能、功耗和面积的相互作用进行分级。以下是 V1 和 V2 核心的堆叠方式:
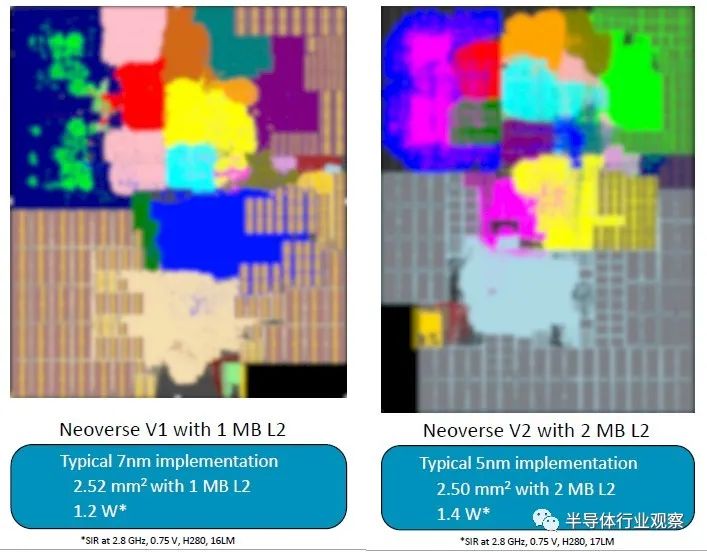
采用 7 纳米工艺实现的 V1 核心面积为 2.5 平方毫米,二级缓存为 1 MB,功耗约为 1.2 瓦。V2 核心的面积稍小一些,L2 缓存是 2 MB 的两倍,功耗提高了 17%。这些比较均以 2.8 GHz 时钟速度进行标准化。
当然,V2 不仅仅是一个核心,而是一个可以授权的平台规范:
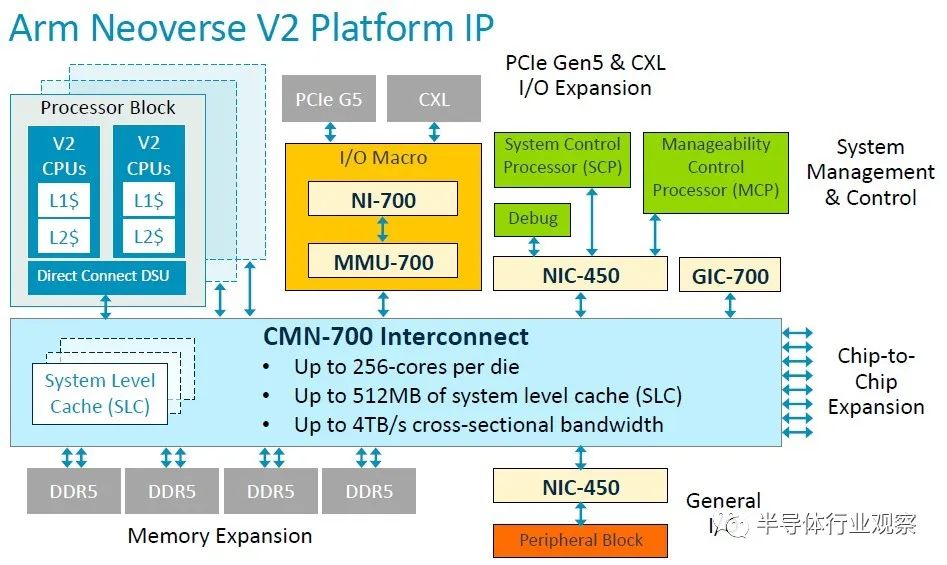
借助 CMN-700 互连,Arm 被许可人可以构建可扩展至 256 个内核和 512 MB 系统级缓存的 V2 CPU,该互连可在所有内核、内存和内存中提供 4 TB/秒的横截面带宽。位于网格上的 I/O 控制器。
V2 核心的很多演示都集中在整数方面,但在演讲的问答中,Bruce 确实说了一些关于矢量性能的有趣内容。V1 核心有一对 256 位 SVE1 矢量引擎,但 V2 核心有四个 128 位 SVE2 矢量引擎。正如布鲁斯所说,这样做是因为将混合精度数学分散到四个单元比尝试分散到两个单元更容易(而且我们认为更有效)。
但正如我们所说,除了 Nvidia 和可能的 AWS 之外,谁将获得 V2 核心的许可?也许任何打算使用 V2 的人都已经在进行自定义设计,因此没有理由制作 CSS 变体?
编辑:黄飞
-
处理器
+关注
关注
68文章
20392浏览量
255713 -
ARM
+关注
关注
135文章
9618浏览量
394595 -
cpu
+关注
关注
68文章
11378浏览量
226509 -
服务器
+关注
关注
14文章
10463浏览量
91885 -
人工智能
+关注
关注
1821文章
50547浏览量
267924
原文标题:Arm最强处理来袭,谁会用
文章出处:【微信号:wc_ysj,微信公众号:旺材芯片】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
基于ARm架构的嵌入式微处理器
ARM公版架构 真的是麒麟处理器的槽点吗?





评论