 高性能、低延迟的InfiniBand式网络并不是唯一的选择
高性能、低延迟的InfiniBand式网络并不是唯一的选择

正如我们喜欢指出的那样,当谈到高性能、低延迟的 InfiniBand 式网络时,Nvidia 并不是唯一的选择,自 20 世纪 90 年代末 InfiniBand 互连出现以来就一直不是唯一的选择。三年前从英特尔收购了 Omni-Path 互连业务的Cornelis Networks 就是另一种选择。虽然它跳过了 200 Gb/秒一代,但仍在销售改进的 100 Gb/秒 Omni-Path Express 变体,并为未来的 400 Gb/秒一代奠定了基础。
Cornelis Networks 的高管们从 SilverStorm 和 PathScale 的 InfiniBand 开始,最终成为 QLogic 的 TruScale InfiniBand 的基础,而 QLogic 又成为来自 Mellanox Technologies 的 InfiniBand 的替代供应商。早在 2012 年 1 月,英特尔就以 1.25 亿美元的价格从 QLogic 手中收购了 TruScale InfiniBand 业务——这似乎是很久以前的事了?三个月后又斥资 1.4 亿美元从Cray 收购了“Gemini”XT 和“Aries”XC 互连业务,将它们整合起来创建 Omni-Path 互连。
从技术上讲,这是 InfiniBand 主题的三种不同变体,而 Cornelis Networks 正在做的事情在许多方面代表了第四种变体。
InfiniBand 的最初目标是取代 PCI-Express、光纤通道,或许还有以太网,并创建融合结构。TruScale 变体采用了一种称为 Performance Scale Messaging (PSM) 的技术,QLogic 当然认为该技术比 InfiniBand verbs approach更好,并且其创建者认为可以提供更好的扩展性。但 PSM 已有二十多年历史,Cornelis Networks 正在基于 libfabric 驱动程序构建新的软件堆栈,该驱动程序是 Linux 操作系统的一部分,并取代了 QLogic TruScale 和 Intel Omni-Path 中的 PSM 提供程序与Open Fabrics Interfaces 工作组的 OPX 提供商进行堆栈。
这个新堆栈经过开发,可以在 Cornelis Networks 从 Intel 购买的 100 Gb/秒 Omni-Path 硬件上运行(该公司称之为 Omni-Path Express,缩写为 OPX),并且将是未来 400 Gb 上唯一可用的堆栈/sec Omni-Path Express CN5000 系列目前正在开发中。
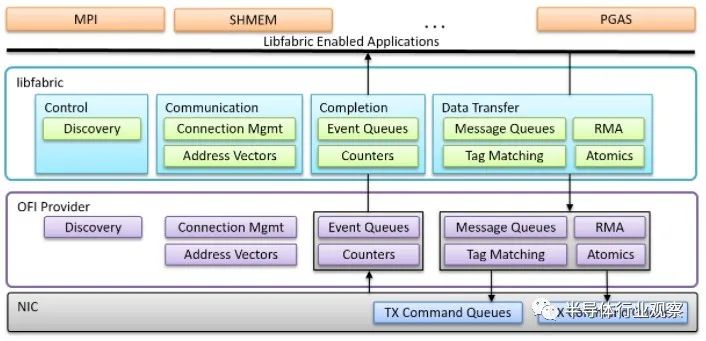
libfabric 库是 OFI 标准的第一个实现,它是一个位于网络接口卡和 OFI 提供程序驱动程序之上的层,位于 MPI、SHMEM、PGAS 和通常在 HPC 分布式计算系统上运行的其他内存共享协议之间和人工智能。它看起来像这样:
以下是 Omni-Path Express 主机软件堆栈现在的样子,其中第二代 PSM2 提供程序和本机 OFI 提供程序并行运行:
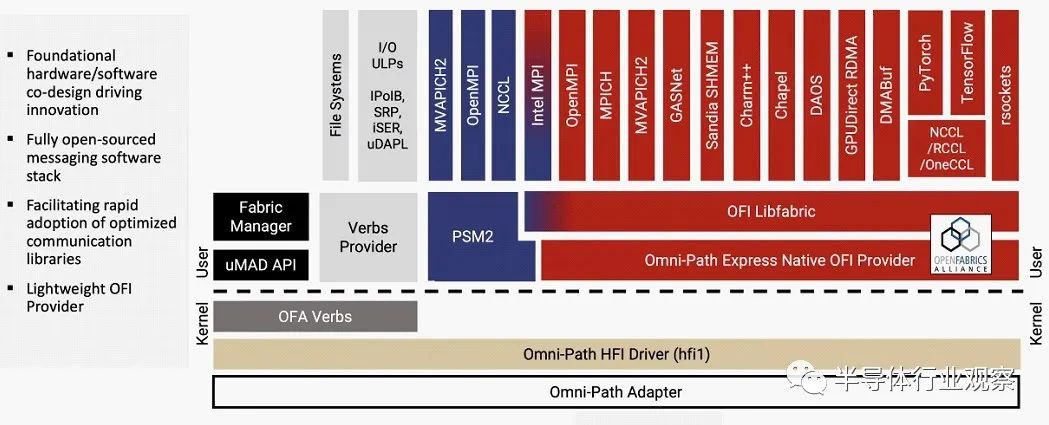
您会注意到,原始 OpenFabrics Alliance Verbs 仍然可以在 Linux 内核模式下使用,以支持旧版协议和框架的 InfiniBand verbs 提供程序,但 PSM2 和 OFI 提供程序都在 Linux 用户空间中运行,其MPI的各种实现也是如此——它们有很多。
在下一代 CN5000 平台中,紫色的 PSM2 内容将消失,我们推测 Verbs 提供程序以及运行在 Linux 内核中的 OFA Verbs 代码之上的内容也会消失。Cornelis Networks 软件工程副总裁 Doug Fuller 本周在Hot Interconnects 30 会议上发表演讲,他表示,OPX 和 Nvidia InfiniBand 之间的主要区别之一是 Cornelis Networks 使用的所有堆栈都将是开放的源并添加到内核的上游。
“我们的 Omni-Path OFI 驱动程序是 Linux 内核的一部分,”Fuller 在演讲中解释道。“我的意思是,我们在内核开发方面也首先处于上游。因此,我们所有的补丁都在上游合并,并且我们有来自 Linus 的火焰来证明这一点。然后我们合并。我们鼓励它向下游合并并集成到各种 Linux 发行版中。因此,在大多数情况下,如果您启动现代 Linux 发行版,您的驱动程序已经存在,无需安装其他软件。我们致力于上游优先开发,我们希望确保回馈我们使用的社区,并为用户提供良好的用户体验。”
三年来我们一直希望看到的,以及 Fuller 向 Hot Interconnects 观众提供的,是备受期待的 Cornelis Network 硬件路线图。话不多说,这里是:

HPC 中心、云构建商和超大规模企业都喜欢可预测的路线图,这些路线图使每一代的比特转移成本越来越低,并且还增加了网络规模,即可以通过合理的响应连接到网络的端点数量时间。这些是 Cornelis Networks 最终公开投入的赌注,众所周知,公司不会购买点产品,而是购买路线图,因为我们都生活在未来。
通过 Omni-Path 100 系列,Cornelis Networks 正在转售由英特尔创建的硬件,该硬件于 2015 年底开始在基于其“Knights”系列多核处理器的早期采用者 HPC 系统中推出。(我们认为 Cornelis 忘记将品牌的“Express”部分放入路线图中。) 该产品系列包括 100 Gb/秒适配器、48 端口边缘交换机、288 端口导向器交换机和 1,152 端口导向器交换机。Omni-Path 100 互连支持 3 米及更短的直连电缆 (DAC) 和 100 米或更短的有源光缆 (AOC)。交换机的基数在fat tree上以全二分带宽支持多达 13,800 个节点,或以半二分带宽支持 27,600 个节点,在网络逐渐变细的情况下最多支持 36,800 个节点。
考虑到其联合创始人多年来推出的产品的悠久历史,凭借 Omni-Path CN5000 CN5000 系列(Cornelis Networks 称之为第五代高性能互连),交换机和适配器中的 ASIC 正在发生变化高达 400 Gb/秒,这将是性能的巨大飞跃。将会有一个 48 端口边缘交换机(看起来像一个普通的披萨盒机器,而不是英特尔在 Omni-Path 100 上做的那种时髦的形状),并且将在导向器交换机上进行差异化,并与单个 576 端口机器一起使用。至于电缆,将支持 DAC 和 AOC,以及将铜电缆拉伸到 5 米或更短长度的有源铜电缆 (ACC),这比 DAC 长 2 米,从而提供更具创意的接线配置。
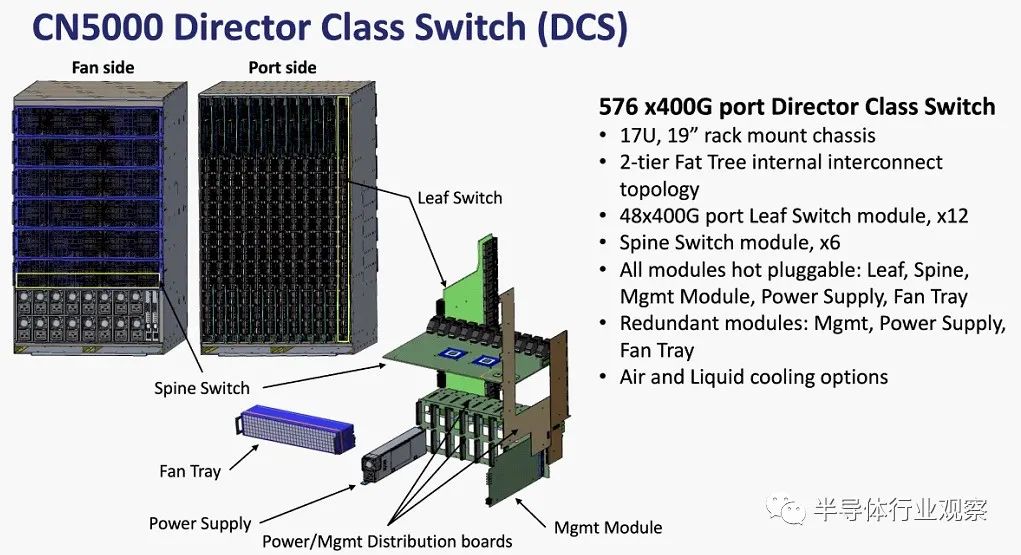
CN5000 系列将支持全二分带宽树和部分二分带宽树,例如 Omni-Path 100,还将支持 Dragonfly 和 Megafly(有时称为 Dragonfly+)拓扑,并且单个集群中最多可扩展至 330,000 个节点。(我们不知道这样的网络中有多少层和跳数,但我们的目标是找出答案。)Cornelius Networks 正在添加基于遥测的动态自适应路由和拥塞控制,这听起来可能基于一些想法是从 Cornelis Networks 通过英特尔获得的 Cray“Aries”技术中挑选出来的。(同样,我们会找到结果。)延迟(我们假设是从节点到节点)承诺低至 1 微秒以下,消息速率预计为每秒 12 亿条。CN5000 导向器交换机将提供风冷和液冷选项。
以下是 CN5000 边缘交换机的一些规格和机械结构:
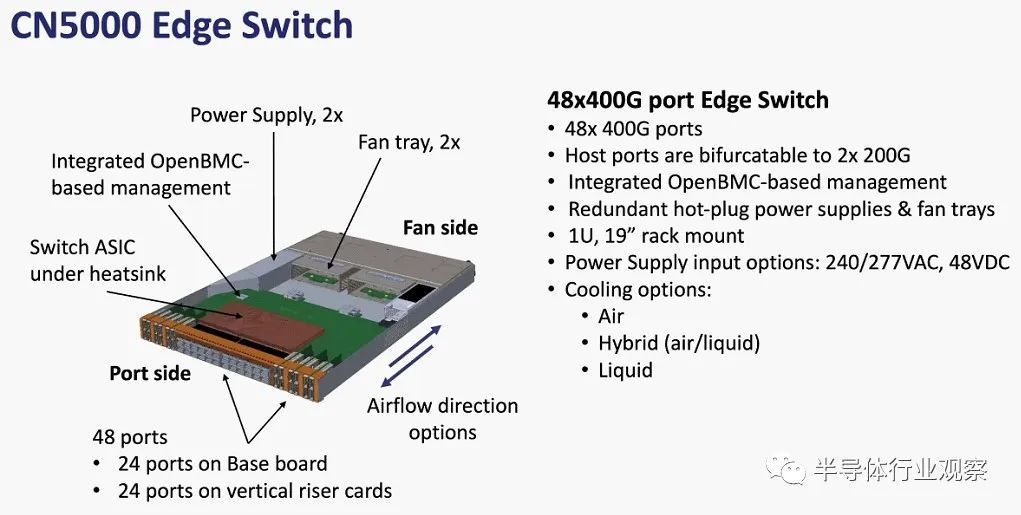
这些是 CN5000 导向器交换机的规格:
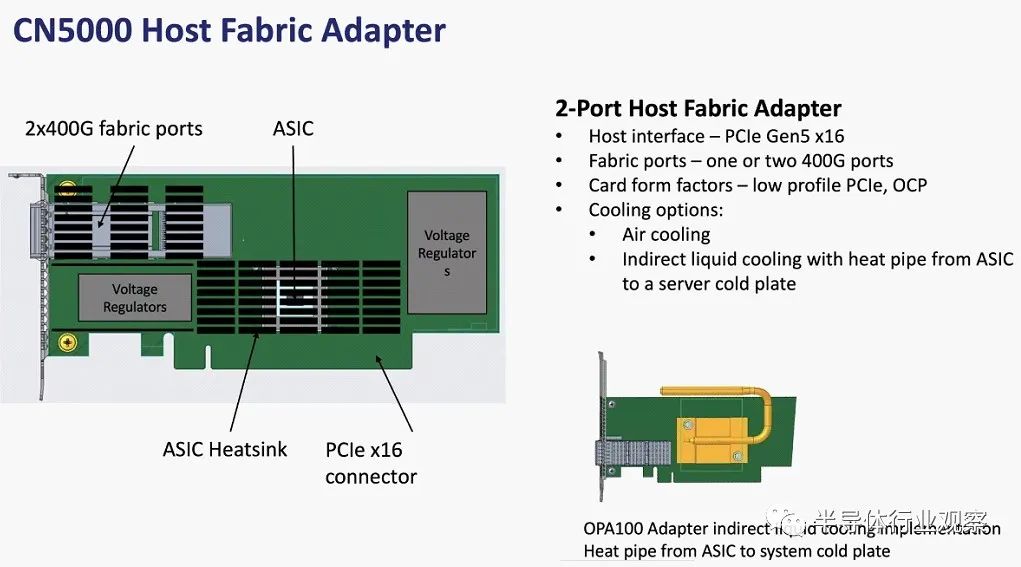
最后,主机结构适配器如下所示:
到 2026 年,Cornelis 路线图将超越 Omni-Path CN6000,后者具有支持 800 Gb/秒的交换机和适配器 ASIC。交换机电缆选项的适配器在二等分带宽、拓扑选项以及 330,000 个节点的规模方面保持不变。这里有趣的变化是使用 RISC-V 内核的 DPU,插入 CXL 端口,并且可能会执行一些集体操作卸载以及安全和存储加速功能。某些结构功能将被卸载,并且可能在交换机和适配器中都有特定于结构的加速器。
随着第七代产品将于 2028 年推出,Cornelis Networks 将把端口速度提高到 1.6 Tb/秒,并将 HyperX 拓扑添加到网络几何结构列表中,并对 DPU 核心以及结构和应用程序卸载进行增强。
我们已经有一段时间没有看到 Nvidia 或 Mellanox 的 InfiniBand 路线图了,而且肯定不会走那么远。但节奏和减速带可能会在某个时刻或多或少同步。
审核编辑:刘清
-
以太网
+关注
关注
41文章
6314浏览量
182000 -
人工智能
+关注
关注
1821文章
50547浏览量
267931 -
InfiniBand
+关注
关注
1文章
31浏览量
9598 -
PSM
+关注
关注
1文章
46浏览量
14159 -
LINUX内核
+关注
关注
1文章
321浏览量
23343
原文标题:InfiniBand的挑战者,来势汹汹
文章出处:【微信号:TenOne_TSMC,微信公众号:芯片半导体】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
探索IDT Tsi578™ Serial RapidIO Switch:高性能嵌入式通信新选择
IDT Tsi572 Serial RapidIO Switch:高性能嵌入式网络的理想选择
IDT Tsi568A Serial RapidIO开关:高性能嵌入式通信解决方案
使用 ISL6160 和 HIP6006 ICs 设计 InfiniBand Class I 电源
LTC2436-1:一款高性能16位无延迟ΔΣ ADC的深度解析
ADM5120 系统级芯片(SoC)网络控制器:高性能与多功能的完美结合
ADAU1372低延迟低功耗编解码器:音频设计的理想之选
从网络接口到 DMA,一套面向工程师的 FPGA 网络开发框架

高性能网络存储设计:NVMe-oF IP的实现探讨
有哪些方法可以降低分布式光伏集群通信网络中的延迟?

DP4363 一款高性能、低电流的Sub-GHz收发芯片
游戏党的福音:支持ALLM自动低延迟模式的HDMI线推荐
延迟低至30ms+ LLSM流媒体传输模块低延迟方案推荐




评论