 如何取替英伟达?如何颠覆英伟达?
如何取替英伟达?如何颠覆英伟达?

随着生成式AI的火热以及英伟达市值冲破万亿美元,如何取替英伟达,成为AI芯片市场新贵,又成为了一个热门话题。
以下为文章原文摘录:
看到英伟达这个万亿美元的市值,我想没有任何人敢说他不想要。。。。。。想要,就得琢磨琢磨怎么才能造他娘的反。
王侯将相宁有种乎!
你得盘个逻辑,提个口号才能举旗,得想办法证明旧社会的不足和新社会的先进性才有机会。
不知道多少人分析过Nvidia的GPU的成本,我们以最新的Hopper H100为例。大致上,为了跑AI大模型,你从Nvidia手上购买到的是如下这样的一张卡,他叫做SXM5模组,单手就能拿捏的样子。
这个模组附带了大量的供电VRM,也通常会使用相对高阶的PCB保证供电的铜损最小。最中间的差不多就是一颗Hopper GPU芯片,看得出由7颗Die用chiplet方式封装,分别是1颗logic Die和6颗HBM。
把他的成本打开,SXM的成本不会高于300$,封装的Substrate及CoWoS大约也需要$300,中间的Logic Die最大颗,这是一颗看起来非常高贵的die,使用4nm工艺打,尺寸为814mm2,TSMC一张12英寸Wafer大致上可以制造大约60颗这个尺寸的Die,Nvidia在Partial Good上一向做得很好(他几乎不卖Full Good),所以这60颗大致能有50颗可用,Nvidia是大客户,从TSMC手上拿到的价格大约是$15000,所以这个高贵的Die大约只需要$300。哦,只剩下HBM了,当前DRAM市场疲软得都快要死掉一家的鬼样了,即使是HBM3大抵都是亏本在卖,差不多只需要$15/GB,嗯,80GB的容量成本是$1200。
你掐指一算……
凸(艹皿艹 ),你花钱到底买到的是什么?这居然是一个投机倒把倒卖DRAM的货,整颗GPU物料成本中DRAM占了~60%,而且这DRAM的容量,80GB,它是个啥?够个屁啊,老黄还骗我买8张卡来存放一个GPT3大模型。
高贵的黄教主啊,想不到你是个高价倒卖DRAM的二手贩子啊........Grace把LPDDR也集成进去了,是不是这集成的LPDDR不得也比标准DDR DIMM贵个几倍?
所以,要革Nvidia命的第一步,就应该从DRAM出手,如果我做把DRAM成本做到更合理的结构,并且再把容量做大到更少的芯片数量就能存放大模型。
这天,我能翻。
就前几天,聪明绝顶的GraphCore联合创始人兼CTO为众多竞争者指出了一条路,如下:
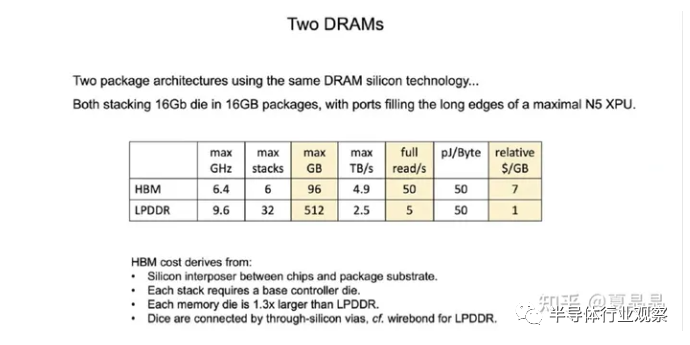
看到没,LPDDR定制一下是可以做到50% HBM的带宽,但是容量远大于HBM的,剩下你只要在AI大模型的存/算带宽容量比上做到最好就行。
不过。。。。。。。他自己为啥不做?
因为一颗H100 GPGPU虽然成本只有 ~$2000,但它在市场上的售价是 ~$30000,在15倍的暴利面前,你想用降成本的方式来获取竞争力。嗯,假设你做一颗成本$1000,比H100性价比更高的DSA,能打赢吗?
客户他又不是傻子,他愿意用$30000的价格买一个$2000成本的东西,他真的会图你的成本能再降低$1000 ?
这个巨大的溢价空间,并非源自GPGPU本身,而来自于其背后的巨大黑手,一个复杂的系统,这个系统本身,甚至潜移默化影响了用户的算法。
Nvidia是一个伪装成卖Device,但真实是在卖一个system的公司。Apple也是。
只有打掉这个系统才有可能破解其成本,想一想,iOS有Android,Windows有Linux,cuda却没有开源路径……
一计不成,再生一计。我再治他一个system的阉人之罪。
回到中国本土市场,你注意到老黄最近在呼吁,美国政府对中国的技术管制要三思而后行。嗯,网传老黄差点就来大陆炒光模块的A股了。
逻辑是没问题的,美国的技术管制大概率Nvidia是参与了,所以他才那么在美国发布管制时,第一时间推出了A800、H800这样的数字对中国人是好意头的芯片型号,这种体贴AMD苏妈妈就慢了一拍(苏妈妈推出了mi388……)。
美国技术管制的约束大致是芯片总带宽要小于600GB/s(双向)。
GPU A100的Nvlink带宽是600GB/s,考虑到PCIe不能裁,A800的Nvlink被限制到400GB/s(12Lane降低到8Lane)。
这还好,洒洒水啦。
H100相比A100算力FP16从300T增加到接近1P,Nvlink带宽从600GB/s提升到900GB/s,咔嚓一刀,H800的Nvlink带宽还是得降低到400GB/s。
有点憋屈,但是我作为骄傲的中国客户,为了图8这个吉利,连4这个数字都能忍了。
我记得我列过几次大模型训练的结构,以GPT3为例,大致上用1024张A100训练GPT,8P一个Node,在Node内模型并行, 然后按8个8P(64P)做8级流水并行,然后16组8x8做Batch 16的数据并行。。。。。。
H100的下一代是B100,它的FP16算力大致上从900T提升到了~2P Flops附近。
哦豁,在这个算力下如果B800只有400GB/s的Nvlink带宽,基本上Tensor并行这个训练行为就没法正常执行了,各大厂商走过路过想一下啊,B800你还要再下10亿美元的单吗?
大概Nvidia和US政府定规则的时候,只考虑了Ampere和Hopper,没把摩尔定律算进去。
所以这个破绽很简单,坏人不让我们做的,我们就越要发展。单芯片的IO能力怼上去啊,600GB不够就上1TB,把互联做得大大的,8P的模型并行不够,直接来16P、32P的大互联。
有人会说:这样是不是有点不公平?嗯,美国卡中国是公平的,反过来利用一下反而不公平了?如果能给老黄一个猴子偷桃就一定要偷。
黄教主近期在台北发布了GH200,就有很多黄粉大吹特吹不是?然后呢?这块芯片的带宽是超标美国对中国技术管制的……嗯,老黄在中国发布了不能卖给中国的产品。很公平?
还有人会说:如果真这么做了,美国就会放松技术管制了。我只能说,如果你不做,技术管制不会凭空的放开,你只有做了,才有放开的一天。
当然,你说,革命之事,你求的本就是天下,不是一城一池。那是。
Nvidia看长远,最大的破腚,其实是基尼系数太高,不患贫而患不均。
TSMC曾经讲过一个故事。台湾同胞辛辛苦苦攒钱建厂,一张4nm那么先进的工艺哦,才能卖到$15000,但是那某个客户拿去噢,能卖出$1500000($30000*50)的货啦,机车,那样很讨厌耶。你懂我意思吗?
就如最开始说的,在这个世界的商业规则下,$2000成本的东西卖$30000,只有一家,销售量还很大,这是不符合逻辑的,这种金母鸡得有航母才守得住。
天下财共一石,老黄独占八斗。
这是对全天下IT产业的伤害,包括TSMC,一个健康的产业,其整个环节是需要一个合理的分配比例的,你要说Logic制造的技术含量最高,但是分成的收益却不到1%,这种分配关系不足以长期维系,tsmc的工艺演进是需要钱的(靠的就是大家共筹,利益均分),如果全世界IT就这么多钱,英伟达你是可以通过系统优势拿走更多,但产业链中tsmc及其他各个环节就会更加艰难。三星的HBM其实同理,操了白粉的心,卖个白菜的价,不值得。
嗯,不过tsmc没钱发展工艺对我们也不是坏事。或者说把芯片制造行业打到毛利接近零,那全世界只有中国人能做,也挺好。
摩尔定律之下,长期稳定地挤牙膏才是发展的王道(当然Intel最终也没挤好,但如果Intel如果过早把牙膏都挤了,死得更早)。
一个人过早获得了超额的财富,剩下就看他能不能守得住了 :) 从历史来看,很难的。
AI这个行业,也终将,昔日王榭堂前燕 飞入寻常百姓家。这是大势。
审核编辑:刘清
-
pcb
+关注
关注
4418文章
23979浏览量
426309 -
VRM
+关注
关注
0文章
32浏览量
13567 -
英伟达
+关注
关注
23文章
4116浏览量
99645 -
AI芯片
+关注
关注
17文章
2166浏览量
36869 -
chiplet
+关注
关注
6文章
499浏览量
13653
原文标题:如何颠覆英伟达?
文章出处:【微信号:ZYNQ,微信公众号:ZYNQ】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
硅光成AI胜负手?英伟达20亿美元战略投资Marvell
施耐德电气与英伟达深化合作以构建高效吉瓦级AI工厂
新思科技与英伟达多项硬核科技成果亮相GTC 2026

英伟达重磅出手!AI 推理存储全面觉醒

黄仁勋:英伟达AI芯片订单排到2026年 英伟达上季营收加速增长62%再超预期
NVIDIA新闻:英伟达10亿美元入股诺基亚 英伟达推出全新量子设备

传英伟达自研HBM基础裸片
国家网信办约谈英伟达



评论