 镕铭微电子VPU如何降本增效
镕铭微电子VPU如何降本增效

当前视频行业环境下,硬件芯片的机遇与挑战并存,如何使得硬件芯片产品及方案设计更好地贴近用户、服务用户及满足用户更深层次需求?本次LiveVideoStackCon 2022 北京站邀请到镕铭微电子解决方案架构总监——蔡媛Amy,为大家介绍镕铭微电子VPU如何帮助客户实现极致增效降"本",并介绍基于新一代Quadra VPU的全球首个硬件智能极速高清产品,如何将历来成本高企的AI增强视频产品带入到规模应用中。
文/蔡媛Amy 编辑/LiveVideoStack 大家好,我是镕铭微电子解决方案架构团队负责人的蔡媛 Amy,本次分享的题目是镕铭微电子VPU极致降本增效实践,主要介绍在生产实践中,如何使用镕铭VPU产品在规模化应用中帮助客户实现极致降本增效,给大家带来新的应用方案和启发。我会从以下几个方面进行介绍:
-01-
镕铭微电子公司及产品介绍
NETINT是一家专注于新型智能存储和视频/图像编解码解决方案的科技公司,在国内的上海、北京、济南,加拿大的温哥华和多伦多都设有研发中心。NETINT自主设计的VPU可提供基于ASIC的超大规模、超高密度、超低延迟的视频解决方案,我们的视频转码器产品已被全球众多顶级大公司所使用。
镕铭微电子的使命是为云和数据中心提供强大的算力,长期愿景是成为世界上最好的数据中心芯片公司。我们的产品主要包括视频处理芯片VPU和软硬件结合的视频处理解决方案,前者在功能上提供视频编解码能力,辅助视频编解码的AI处理能力以及2D图像引擎的处理能力,后者包括三种产品形态,第一种是VPU服务器板卡,第二种是搭载芯片的视频处理一体机,第三种是基于视频处理一体机的端到端视频解决方案。
镕铭微电子是视频处理芯片 VPU 定义者和视频处理方案创新企业,镕铭微电子设计出了多款高度创新的芯片产品,被广泛应用于云数据中心、边缘计算公司及媒体内容提供商,最大程度地降低视频处理和数据储存的成本。VPU产品技术位居全球第一,并且已经成功研发两代芯片,第一代产品已经在全球头部客户处大规模验证和应用部署,同时也是数据中心大芯片领域的创业公司中出货量最大的独角兽企业。

图中展示了两代产品,第一代是Logan芯片,对应Codensity T408单芯片产品和T432 4芯片产品,于2019年发布并量产。同时具备U.2/AIC的形态,来适配兼容不同型号的服务器。U.2形态的编解码卡,和2.5寸 NVMe SSD的外形一样,可以直接使用NVMe SSD的卡槽。除外,大部分服务器都具备PCIe卡槽,可以使用AIC形态的编解码卡。
第二代是Quadra芯片,基于Quadra发布了T1A、T1U和T2A产品,在海外的客户已有过万片的部署,这两代芯片无论是在应用性、稳定性还是在实际业务中都经过了客户规模化部署的验证。
-02-
镕铭微电子VPU增效降“本”实践
鉴于目前全球经济形势处于下行状态,我会重点介绍“增效降本”部分。
NETINT VPU是面向数据中心和边缘计算设计的视频/图像编解码处理芯片。那么,通常对于面向数据中心的芯片,在大规模应用部署的时候,需要考虑的几个重要因素:包括性能、成本、同构性、稳定性。性能就是字面意思,我们需要关注峰值性能、平均性能等。比如人工智能芯片,我们会非常关注他的计算能力(吞吐量):通常关心的是32位浮点计算能力。做推理预测的话也可以用8位整数,我们会关注INT8 的计算能力。显存大小:当模型越大,或者训练时的批量越大时,所需要的GPU内存就越多。对于CPU来说,我们关注芯片提供的核数,芯片的频率。对于VPU 而言,因为主要提供的是视频/图像的编解码处理,所以性能上主要是指芯片可以并发处理的编解码的路数、协同做视频处理的AI计算能力、编码延迟水平(最大延迟/平均延迟)等。
而成本和我们今天讨论的降本增效是直接相关的,成本包括TCO(整体拥有成本)、人力成本以及时间成本。
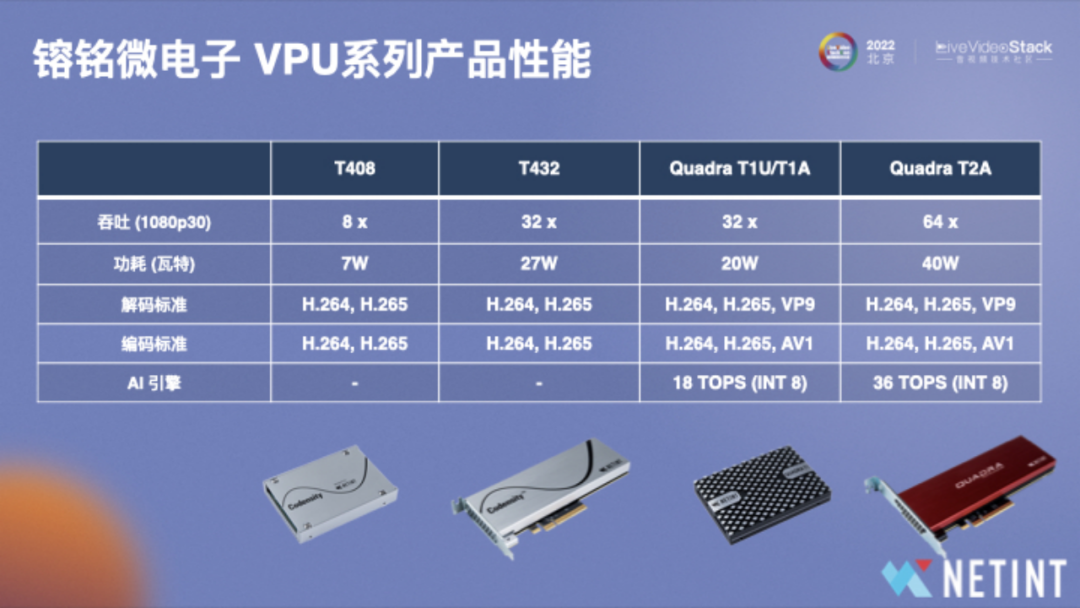
图中列举了VPU系列产品性能,T408 吞吐支持8路1080P/30fps,功耗是所有产品中最低的,只有7W,而国产人工智能芯片的功耗大致在70w-100w,对于CPU,高配CPU的功耗大概是240w,对比下来,T408功耗相当低,它支持H.264/H.265 转码。T432是4芯片产品,相当于T408 4倍能力,相当于32路。
2022年发布的Quadra系列,其特点是性能相对于T408提升了4倍,单芯片支持32路1080P,T2产品是两芯片的Quadra,可以支持64路1080P30。Quadra还支持8K/60fps单路的实时转码,T2相当于支持两路的1080P/60fps的实时转码。Quadra的功耗是20w,在编解码标准上,Quadra增加了支持VP9的解码标准及AV1的编码标准,海外的应用快于国内,比如META、Google,尤其是前者超过70%的流量走AV1。国内头部公司目前更多以H.265标准为主。
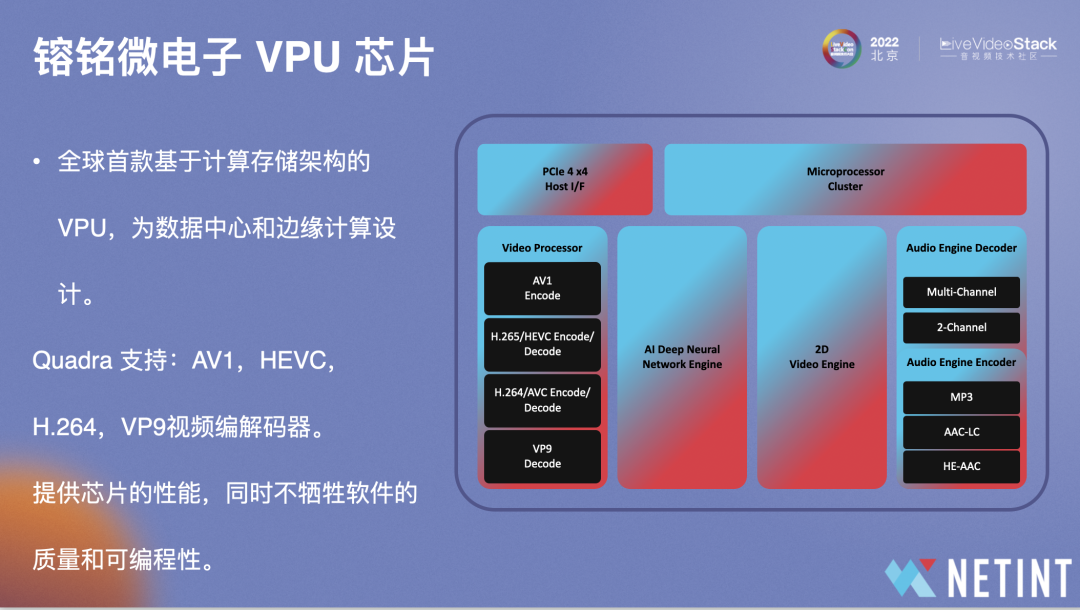
图中展示的是Quadra关键的视频处理单元,包括编码模块、解码模块、AI推理引擎、2D图像处理引擎,以及可用于音频处理的DSP模块。芯片集成的AI 推理引擎,与视频编/解码器集成于同一芯片上,这可以让用户在同一个芯片上实现一些复杂的AI辅助编码,比如ROI辅助编码,窄带高清编码、在同一芯片上完成AI推理,编解码所有数据处理流程,这将极大地提升工作效率并显著减少延迟。
我们是全球首款基于可计算存储架构的VPU,专门为数据中心和边缘计算所设计,使用NVMe协议作为主机到硬件加速器的设备接口。NVMe是非易失性内存接口协议,旨在用于基于PCIe的存储设备,例如SSD(固态磁盘),它还可以扩展到支持可计算型存储。这样的优势包括免驱动,能够避免许多与服务器的兼容性问题,同时达到更好的延迟和数据交换能力。
除了性能之外,大家还会非常关注编码的比特效率,Quadra的比特效率在快速档上能够达到Fast和Medium之间的水平,在慢速档能够达到H.265 Slow的水平。
行业中较好的H.265软件编码器,在Super Fast档位上,开到4个线程,8K分辨率时能够达到17fps,之后即使线程数增加,其fps也无法随之提高,且CPU利用率也无法达到满载利用率。所以要用软件编码器实现8K/60fps,需要在转码系统上实现比较复杂的并发架构。而利用Quadra硬件编码器,就能够实现单芯片8K/60fps实时转码,并且单线程达到92%以上的loading,这是VPU在高分辨率视频处理上的极大优势。
在画质处理的对比结果上,相较于Nvidia T4硬件编码器,在类似档位lookahead-4,相同的PSNR下能够节省23-25%的码率,rdo开到3时,可以进一步将码率节省提高30-31%。
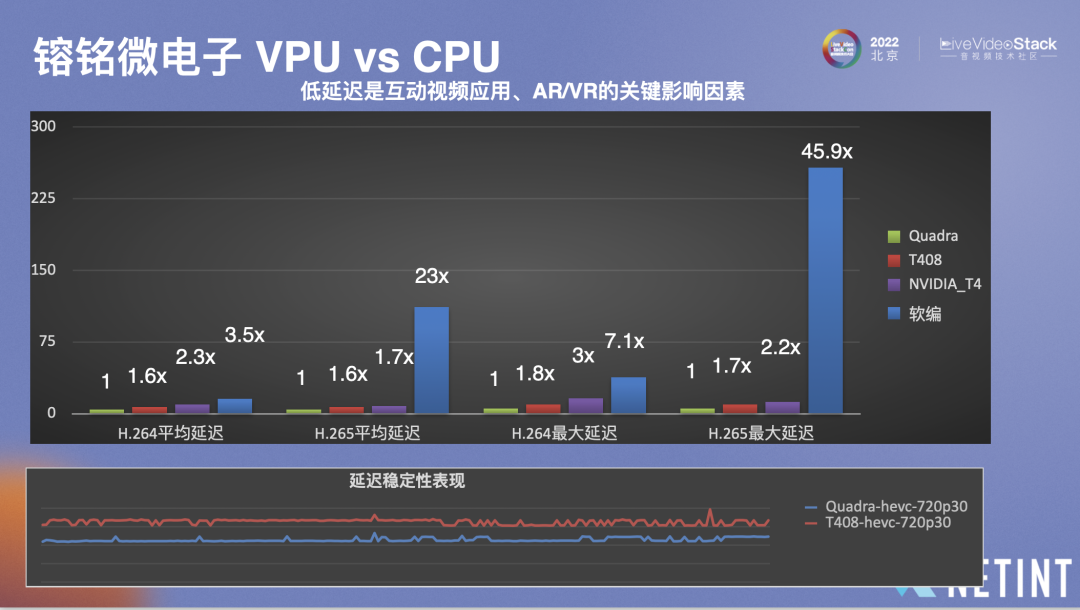
另一个编解码的重要指标是延迟,Quadra的延迟对比T408有了更高的提升,1080p的编码延迟大概是4ms,这是单路延迟,将路数提升到32路,延迟也只增加1-2ms,大概是5-6ms,对于互动型应用如云游戏、RTC等,其QoE及QoS参数极易受延迟影响。图中可以看到Nvidia T4延迟大概是Quadra的两倍,H.264大概是三倍,达到15ms左右,X.265大概是20多倍,接近100ms,当然这都是开源的H.264及H.265,但即使对比行业内优化非常好的软件编码器,两者的差距也达到3-4倍。
最大延迟相差更明显,这是因为软件编码器的延迟波动相较于硬件编码器来说大很多。下图显示Quadra的延迟波动基本处于稳定状态,而延迟稳定对于云游戏等场景非常重要,波动较大时会影响客户体验,码率和延迟不能突然增大,显然Quadra能够更好满足需求。
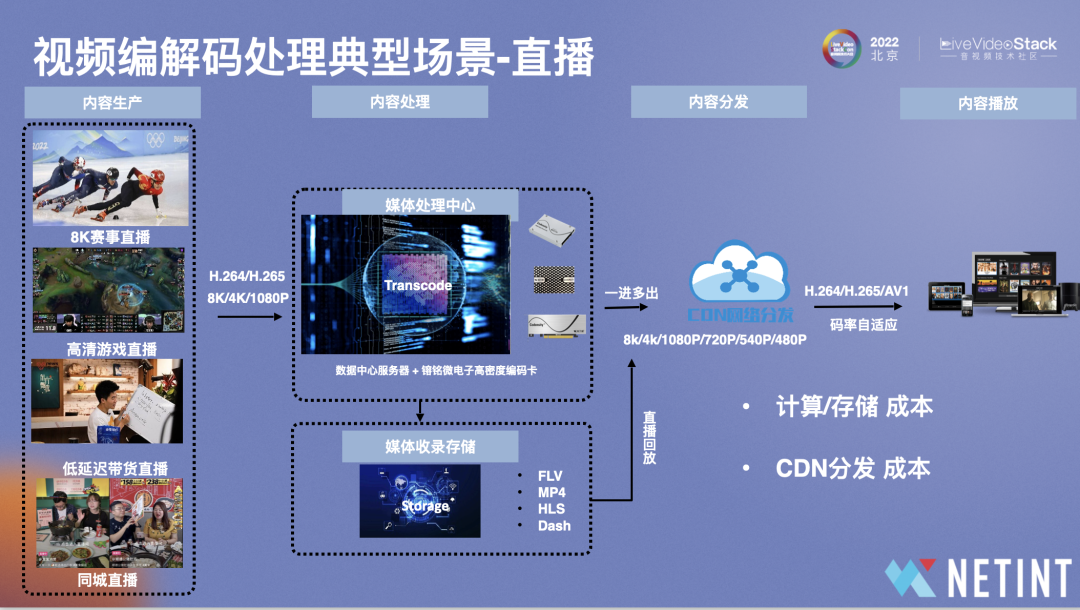
性能和成本息息相关,在计算成本时需要考虑哪些因素?以直播场景为例,直播整个业务流程包括内容生产、内容处理、内容分发及内容播放,编解码卡位于内容处理环节,除了本身的计算成本,其码率也会影响到内容分发的CDN成本及计算/存储成本。

计算成本时需要考虑密度、折旧及功耗:
①密度:如一台32核服务器,单个服务器只能跑6路左右的H.265 1080P30FPS转码,前提还是行业内较优秀的软件编码器。64个thread的服务器可以跑12路,128个thread能够跑24路。对于T408而言,在一台机器插上24个U.2卡,能够实现整机跑200多路,密度是原来的20/30倍。
②折旧成本:如一台64核(vCPU)服务器加上编解码卡后,整机成本并不会上升很多,但其密度能够提升20倍左右,这便降低单路折旧成本。
③功耗成本:功耗会影响机柜成本支出,一个16A机柜能够容纳7台400-500w的机器,插上卡后,单个机柜能够容纳的机器数量并不会有明显变化,但其整机可运行的密度能够提升许多。
除了计算成本外,还有分发成本和存储成本,影响两者的因素是比特效率。Quadra H.265在VITS2021SmallSet dataset 基准测试集上, 最高挡的rdo level的配置下相对fast挡位能够得到8.9%的码率节省,相对于medium挡位得到4.1%的码率节省。对于直播冷流来说,使用VPU产品主要是为了降低转码的计算成本。但对于热流而言,使用VPU高画质模式可以在带宽和存储成本上获得更大的收益。
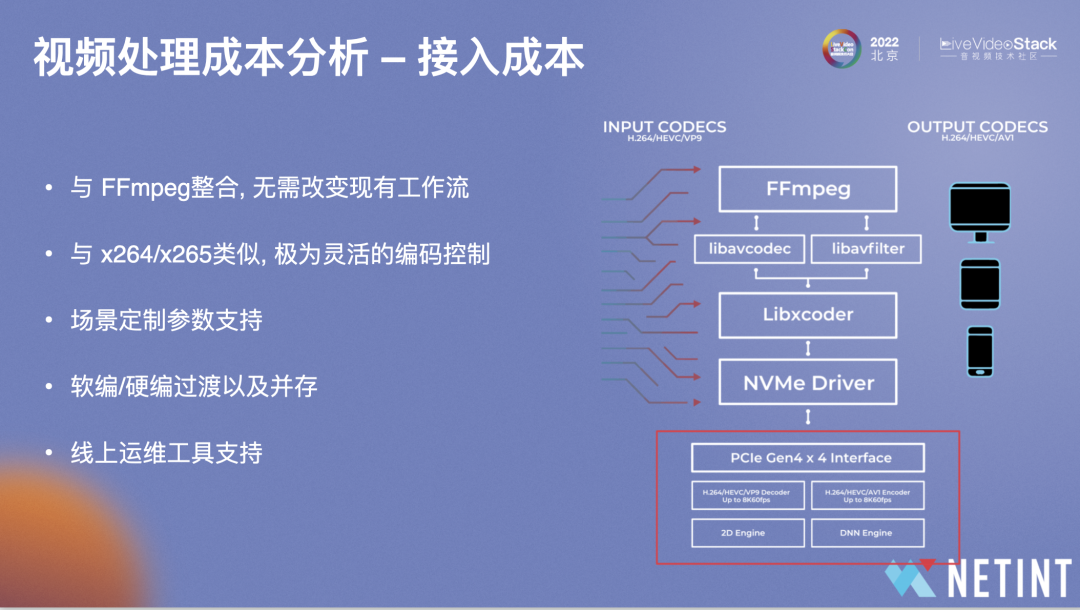
成本还包括人力成本,即接入所付出的人力代价,T408和Quadra都基于FFmpeg架构,为用户提供FFmpeg框架的lib,客户只需接入libavcodec的API即可整合现有的FFmpeg流程,无需对现有的架构做太大变更。部分用户会基于NETINT提供的Libxcoder API。在接入上和X 264/X265类似,并提供了极为灵活的编码控制,场景的定制参数。此外,在规模化运维时,为用户提供了运维工具及线上debug工具,以便帮助用户快速排查问题。
-03-
镕铭微电子VPU规模化部署实践
我们是数据中心大芯片领域出货量最大的独角兽公司,接下来为大家介绍大规模部署的相关实践。

规模化部署需要考虑两点,第一是同构性,如何将一张编解码卡与现有的基础设施进行简单的兼容,并在现有的算力如现有的服务器基础上进行算力扩展,从而方便地接到系统簿上进行算力扩展。第二是稳定性,也就是说在进行规模化部署时,硬件、固件/软件层的稳定性如何?

在兼容性上,我们采用的是NVMe协议,是免驱动的,一般来说,Windows、Linux、Android系统都会自带稳定高效的NVMe驱动程序,在装编解码卡时无需用户装驱动,我们基于NVMe 1.3的协议,能够向下兼容。在系统支持上,我们能够较好兼容Windows、Linux、Android,U.2产品还支持热插拔。规模化扩容方面,能够利用现有存储机型直接插上U.2的Quadra或T408,将一台只有几路的服务器扩展为支持200路或300路编解码卡的服务器。
而传统驱动需要自动定义其驱动程序,并存在对不同操作系统的兼容问题,尤其是Windows系统的兼容更为困难,在规模化部署时,会凸显稳定性相关的问题,如掉卡,无法识别卡等。我们采用的NVMe接口及驱动能够极大程度避免此类问题的发生。

关于同构性,我们提供U.2和AIC形态的卡,可以进行选择而无需配件转换,U.2和NVMe SSD的形态及协议都一致,能够复用机型。
此外,我们的功耗非常低,单卡T408是7W,单卡的Quadra U.2是20W,一般情况下插上卡后,一个机柜原来是7个服务器,现在还是7个服务器,不需要改动机架,这样有利于机器的运维。
图中右侧是Quadra的AIC形态,我们同时了提供服务器整机方案,展台有7张卡的服务器样例。

算力扩展能力利用的是NVMe over fabric协议,通过高速的网卡实现服务器之间的高速数据通道,即使服务器和卡不在一台机器上,也可以实现低延迟高数据带宽的连接和访问。

这是规模化落地的实例,左图是在海外的24*U.2,联合SuperMICRO提供的T408服务器整机。右图是服务器利旧实例,利旧一般采用T408,其规模化稳定性部署已经非常成熟。

在大规模部署过程中,大家可能会考虑到硬件或固件稳定性,比如接入业务后会不会导致业务有损。
在硬件稳定性上,我们有Spike/Lt-loop/DCpower反复过万次的稳定性验证、超负载、过热保护等稳定性验证,进行了严格的跌落测试,做出掉卡率、坏卡率 SLA承诺以及RMA流程承诺,从而保证问题的闭环。
在固件稳定性上,我们经过了数万片线上规模化部署验证,对解码场景能够达到业界最好的兼容性支持,并且有超7w个test case支持固件升级。
-04-
Quadra硬件智能极速高清产品

大家应该非常熟悉极速高清产品,如阿里的窄带高清,腾讯的极速高清等,我们的产品也是基于AI技术与图像处理技术,通过深度学习网络,对视频画面进行感知,优化主观体验,追求较好的人眼感受,节省带宽。
而不同于其他极速高清产品,Quadra基于硬件芯片的AI推理引擎及编码做无缝配合,从而达到更好的处理效率和规模化应用的成本优势。
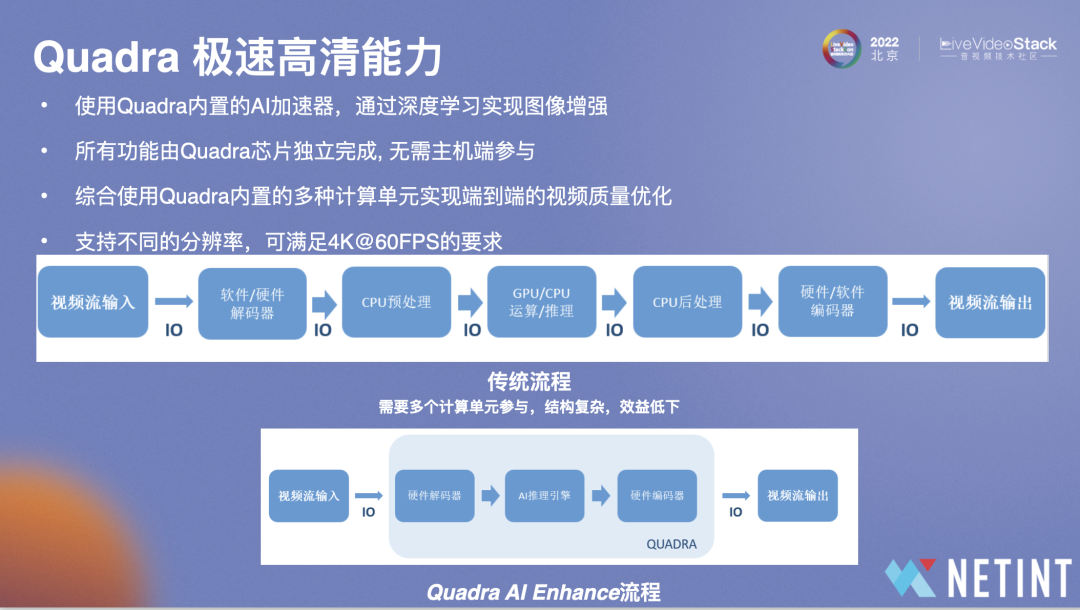 图中对比了Quadra的处理流程和传统处理流程
图中对比了Quadra的处理流程和传统处理流程
传统处理流程是在视频输入后通过解码,到CPU进行处理,再给到CPU/GPU做推理运算等前处理,再给CPU做后处理,再给到硬件/软件做编码,整个流程实际上非常复杂,延迟无法达到最好的效果,而且成本较高。
Quadra AI Enhance流程都在卡内完成,在卡内解码,将数据推到AI推理引擎、编码器再输出视频,相较于传统流程来说简单了许多,无需主机侧参与,利用Quadra本身的AI计算单元实现端到端的视频质量优化。
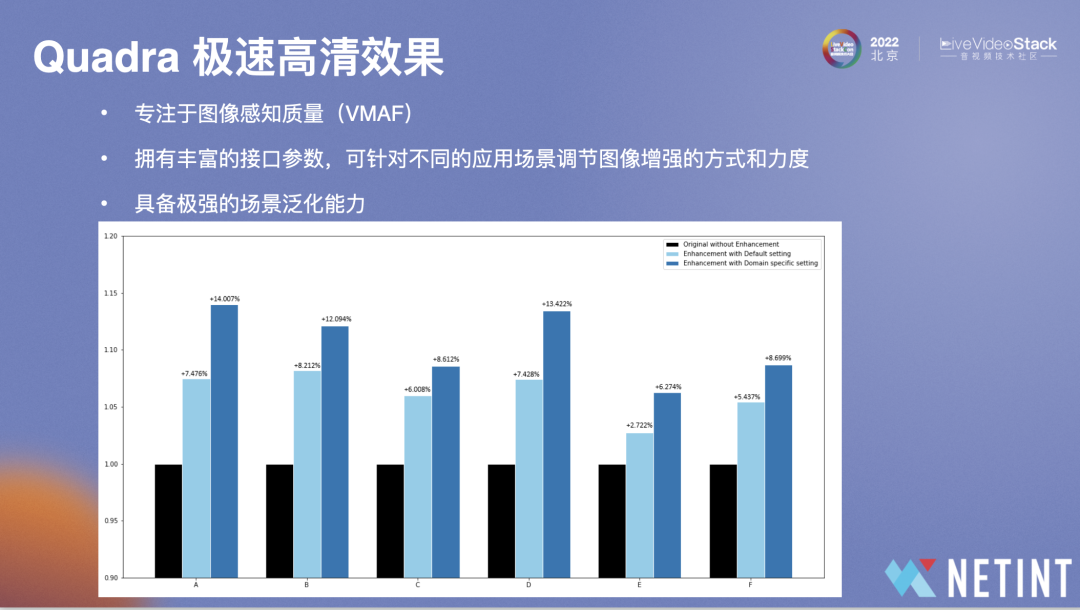

我们专注于VMAF,提升人眼主观效果。图中是处理前后效果对比,可以看到使用极速高清后的VMAF能够提升14%左右,Quadra还具备极强的场景泛化能力。

在成本方面,首先,云服务对极速高清的定价是普通媒体处理的4倍,成本昂贵。通过Quadra以及提供的极速高清开关可以实现25%的转码比例,在无额外成本下支持极速高清,并且主观效果提升明显,大概达到4K@60FPS、1080P@240FPS及720P@480FPS的极速高清性能。我们希望帮助客户将历来成本高企的AI增强视频产品带入到规模应用中。
责任编辑:彭菁
-
芯片
+关注
关注
463文章
54644浏览量
471027 -
asic
+关注
关注
34文章
1282浏览量
125087 -
vpu
+关注
关注
0文章
16浏览量
12103
原文标题:镕铭微电子VPU 极致降本增效实践
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
助力电子产业降本增效!华秋亮相第四届中国模拟半导体大会
UWB科技赋能降本增效,实现智能化转型
NVIDIA China SAE帮助客户更好的利用GPU实现降本增效
循图降本增效,予力企业上云成本降!降!降!
制造业降本增效的关键策略与实践
软硬件免费提供,360安全云助力企业降本增效


直线电机模组:米思米如何以“磁”之力,引领降本增效新风尚?
AR眼镜:医药厂商降本增效新利器
戴尔科技助力企业实现科学的降本增效
停车场照明焕新记:晶映节能改造的降本增效实践

千方集团持续推动公路货运实现降本增效
智慧能源管理的技术手段如何实现降本增效?




评论