 用于密集、在轨、基于边缘的计算的微处理器和 FPGA
用于密集、在轨、基于边缘的计算的微处理器和 FPGA

卫星运营商越来越多地获取越来越多的在轨数据,并且更愿意在有效载荷上处理这些数据以提取增值洞察力,而不是将大量信息下行传输到云端进行地面后处理。现有空间级半导体技术和/或 RF 带宽限制限制了可实时处理的数据量。我知道有几个客户由于这两个原因不得不取消他们的使命愿望,因为他们的下行链路需求会违反 ITU 规定。
相比之下,尽可能靠近原始数据源(即在边缘)的本地化处理是基于对来自多个传感器的大量信息的实时计算,这些信息是使用低延迟、确定性的接口在一个小的、具有独特散热和可靠性要求的低功耗外形。在轨提取分析显着减少了延迟和 RF 下行链路带宽——我们正在有效地将数据中心移动到原始数据的!
在这篇文章中,我想讨论和比较微处理器和 FPGA 在边缘进行密集的板载处理。一些应用程序从具有不同带宽的多个传感器(例如RF、LIDAR、成像和 GNSS)获取大量数据,并且需要实时做出关键决策,例如,物体的识别和分类以实现航天器态势感知,即,敌我识别、空间碎片碰撞规避、高清视频原位对地观测与太空探索、资源利用。使用机器学习技术提取在轨分析的自主机载处理也有增加的趋势。
现有解决方案和局限性
当前的机载处理基于微处理器或 FPGA,两者都没有针对物体的 AI在轨表征进行优化。前者有利于控制、复杂的决策制定和操作系统支持,而后者可以处理各种计算要求苛刻的算法,在数据移动、自定义加速、面向位的功能和接口方面表现出色。然而,现有解决方案无法有效地处理线性代数、矩阵或矢量处理,也无法以低功耗利用并行性进行自主机器学习、AI 推理以及神经网络的实施以进行特征检测和分类。
在商业领域,初为游戏玩家开发的 GPU 正被用于加速各种计算任务,包括加密、金融建模、网络和人工智能。GPU 使用多核和并行处理来同时执行数千个线程,与微处理器相比运行速度明显更快且更具成本效益,允许在毫秒而不是秒、分钟或小时内计算来自多个传感器的数据密集型分析。GPU 针对大量存储信息非常快速地反复执行相同的操作进行了优化,而 CPU 往往会到处跳跃。
虽然有近三十种空间级微控制器、微处理器、FPGA 和专用 DSP 引擎,但只有一小部分可以考虑用于在轨基于边缘的应用程序。许多现有设备不具备计算能力或低延迟内存/I/O 接口。有些消耗太多功率,需要大型且昂贵的热管理解决方案:之前我描述了如何使您的空间级半导体保持冷却,以确保它们的安全运行并限度地提高可靠性。表 1 列出了我考虑过的遗留标准处理产品。对于下面列出的 FPGA,指定性能是基于资源数量和时钟频率的理论峰值。V5QV 不包含标准的微处理器 IP。
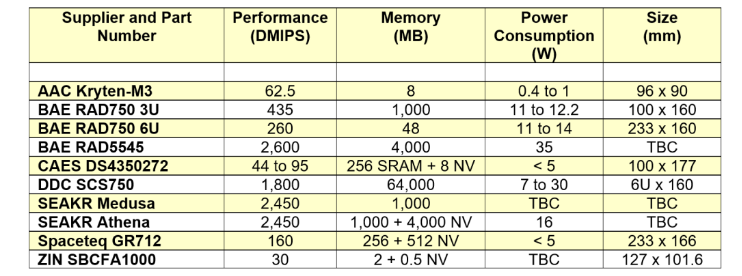
表 1现成的航天级机载处理解决方案。
随着机载数据量预计呈指数级增长,您应该使用哪种类型的处理器来进行密集型、基于边缘的机载计算?MPU 好还是 FPGA 好?ESA 近关于机载数据处理的 研讨会强调了当前的担忧、趋势和未来的需求。
阻碍在轨边缘处理的基本技术限制是:
缺乏大容量、低延迟、低功耗的太空级内存。目前,快速空间级存储仅限于易失性 DDR3/DDR4 SDRAM。之前,我解释过要实现 1Tb 的板载存储需要 64、16Gb 的芯片,总共消耗 17W 的功率,需要 152.3cm 3 的物理空间和 468,060 英镑的财务成本。这在任何级别上都不是一个可行的实现,并且空间限定的非易失性内存非常慢。
缺乏用于提供所需处理能力的空间应用的高能效微处理器或 FPGA。在过去十年中,基于 65 和 20 纳米 SRAM 的 FPGA 提供了消耗 20 W 的有效负载处理,而基于 28 纳米闪存的设备提供了更低功耗的解决方案。超深亚微米性能、逻辑密度和资源导致消耗增加。具有所需原始性能的空间级 MPU 的功耗超过 30 W。
现有的航天级微处理器或 FPGA 无法有效地融合和处理来自多个传感器的输入。将大量信息移入和移出处理器会造成数据密集型计算的性能瓶颈。
现有的太空级微处理器或 FPGA 无法有效地实施用于对象识别和分类的深度学习算法。
基于边缘处理的新解决方案
为了实现那些需要在轨、基于边缘、机载处理的应用,的 FPGA 和微处理器正在解决上述限制:
快速(高达 2,400 MT/s)、4 GB、空间级 DDR4 内存的小尺寸可用性,我在之前的文章中对此SDRAM的硬件设计进行了介绍。
低功耗 28 nm 闪存 FPGA 的可用性降低了功耗,更节能的微处理器提高了 GFlops / W 指标。
自 2020 年以来,Teledyne e2v 的耐辐射 QLS1046-4GB 计算密集型微处理器包括数据路径加速架构 (DPAA),以增加数据包解析、队列管理、硬件缓冲区管理和加密,并支持 IEEE 1588 精度时间协议。同样自 2020 年以来,Xilinx 的XQRKU060改进了信息流和吞吐量,数据路径、I/O 和内存接口针对低延迟进行了优化。
下一代 7 纳米 FPGA 包含专为处理线性代数而优化的 AI 模块,可加速深度学习算法的性能。QLS1046-4GB 的四个内核均包含原生矢量协处理器,例如。氖。
表 2 包括的航天级 FPGA 和微处理器:前者结合了可重构逻辑、MPU,而下一代部件将包含用于高效矢量处理的 AI 块。对于以绿色列出的 FPGA/MPSoC,指定性能是基于资源数量和时钟频率的理论峰值。实际计算水平会较低,具体取决于这些计算的使用方式、实现方式、内存和 I/O 使用情况,但表 2 提供了一个有用的比较,包括软核 RISC CPU。KU060 和 Versal 器件的高度并行特性反映在它们的大 TOPS 值中。
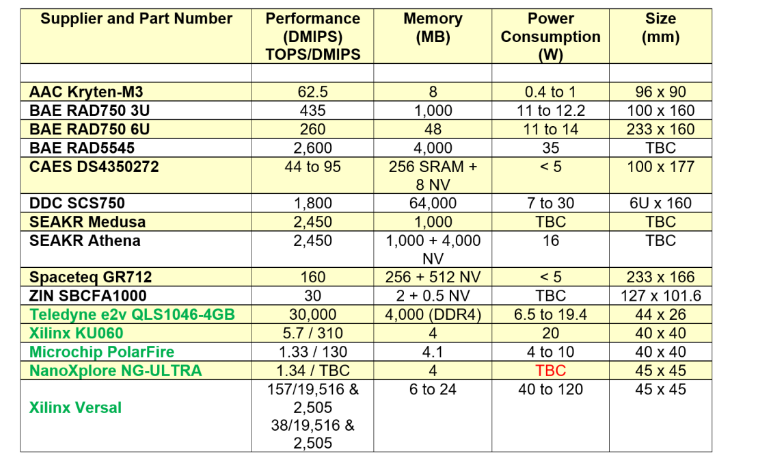
表 2航天级机载处理解决方案的比较。
随着机载数据量的显着增加,使用人工智能和机器学习技术进行自主有效载??荷处理的趋势越来越明显,可以为时序关键型和非实时应用提取在轨分析。例如,在其地面站覆盖范围之外的空间碎片回收航天器将无法接收到启动避碰操作的延迟命令。从多个传感器获得机载态势感知,然后进行对象检测和分类,将允许实时做出这种时间关键的决定,而无需人工干预。同样,高清 SAR 图像生成大量地球观测数据,而不是阻塞宝贵的 RF 下行链路,在轨人工智能推理和神经网络的实施将允许进行特征识别、场景分割和表征。
传统计算侧重于处理已知问题,即可以轻松描述的问题。另一方面,深度学习就是解决你无法解释的问题,例如,识别图像中的对象,并且随着时间的推移会变得更好。机器学习通常分为两个阶段:训练和推理。精心策划的数据被输入模型,并调整变量以产生特定的预测。这需要线性代数、矩阵和矢量运算,然而,现有的解决方案无法有效地执行这些操作,也无法在低功耗下利用并行性。虽然的微处理器和 FPGA 的原始处理能力可能已经足够,但这些设备在关键的延迟方面存在不足。在存储和 CPU 之间移动数据会给数据密集型应用程序带来性能瓶颈。
Teledyne e2v 提供其耐辐射Qormino QLS1046-4GB 四核处理器,结合了四个运行频率高达 1.8 GHz 的 ARM ? Cortex A72 内核和 4 GB 快速 DDR4 SDRAM,外形小巧,44 x 26 毫米,如下图所示. 将片外存储器与多个 CPU 集成到单个基板上,无需设计这种复杂的时序关键接口,提供显着的尺寸、重量和功率 (SWaP) 优势,以实现在轨边缘处理。该部件提供 30,000 DMIPS 或超过 45,000 CoreMarks 的计算性能。
四个 MPU 执行 ARMv8-A 架构,每个都有自己的 L1 32KB 数据缓存和 48KB 指令缓存,并共享一个公共的 2MB L2,如图 2 所示。频率为 1.2 GHz,电源电压为1 V 和 1.6 GT/s 的 DDR 速率,QLS1046-4GB 的总功耗范围为 6.5 至 12 W(不包括外围设备),具体取决于允许结温。同样,在 1.8 GHz、1 V 的电源和 2.1 GT/s 的 DDR4 速率下,该设备的功耗为 9.3 至 19.4 W。其原始计算性能与内存带宽一起避免了 I/O 瓶颈和小尺寸差异化QLS1046-4GB 来自表 1 中列出的解决方案。

图 1 Qormino QLS1046-4GB 处理器和内存 [Teledyne e2v]。
Teledyne e2v 的耐辐射处理器路线图将包括新的、多核、基于 ARM ?的 MPU,能够连接到更大量的快速 DDR4 SDRAM。更多的将允许计算与并行执行的任务分开。可在此处查看描述使用 QLS1046-4GB 进行深度学习的个用例。
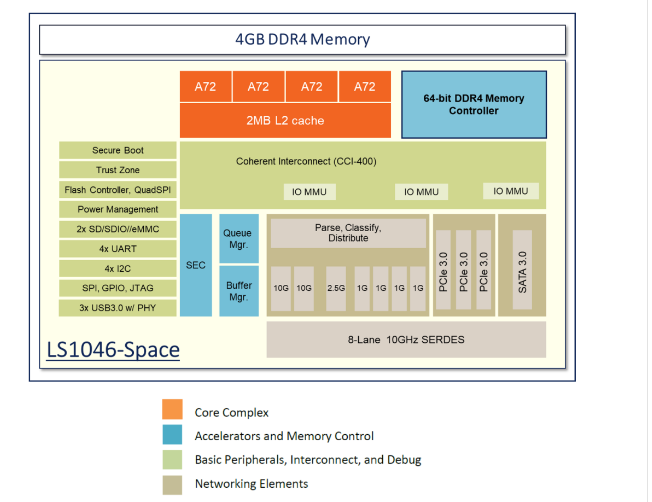
图 2 Qormino QLS1046-4GB 框图。
9 月,Xilinx 宣布将发布其 Versal ACAP(自适应计算加速平台)的抗辐射版本。该器件包含一系列 AI 引擎,包括 VLIW SIMD 高性能内核,包含用于定点和浮点运算的矢量处理器、标量处理器、专用程序和数据存储器、专用 AXI 通道以及对 DMA 和锁的支持。
AI tile 提供多达 6 路指令并行性,包括两个/三个标量操作、两个向量读取和一个写入,以及每个时钟周期的一个固定或浮点向量操作。数据级并行性是通过矢量级操作实现的,其中可以在每个时钟周期的基础上操作多组数据。与的 FPGA 和微处理器相比,AI 引擎将机器学习算法的性能分别提高了 20 倍和 100 倍,功耗仅为其 50%。与表 1 中列出的现成处理解决方案相比,AI 块是实现智能、自主、在轨边缘处理的关键区别特征。
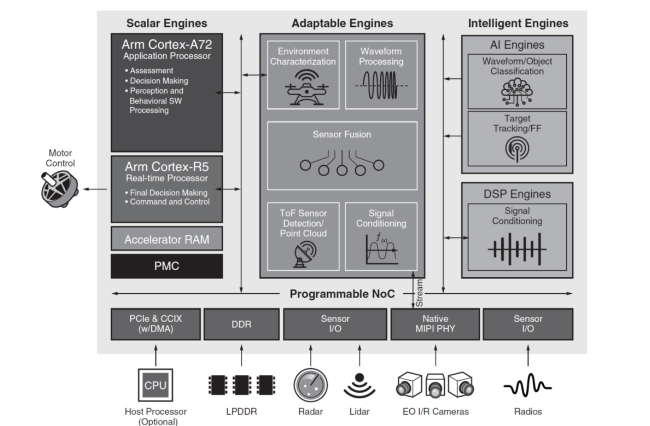
图 3 Xilinx 的 Versal ACAP [Xilinx] 的框图。
结论
对于我目前正在开发的应用程序,哪种类型的板载处理器更好?FPGA、微处理器还是 ACAP?很大程度上取决于算法的实现方式,例如片上缓存的使用、外部存储器访问的数量和频率、流水线、并行化和缓冲。的太空级设备可以超越商用 GPU,同时还能实现更高的功率和价格效率。
对于高清 SAR 视频,QLS1046-4GB 的原始计算性能及其快速的内存接口和小巧的外形使其适合从地球观测成像数据中提取实时信息。高达 2.1 GHz 的 DDR4 速率避免了传统的 I/O 瓶颈。
对于态势感知,例如,为了识别朋友或敌人,或避免空间碎片碰撞,的 FPGA(如 KU060)能够实时摄取和处理来自多个传感器的 Tbps 数据,低延迟,以交付 ASIC一流的系统级性能。同样对于原位太空探索,资源利用。FPGA 处理一组不同的计算要求高的算法,在数据移动、自定义加速、面向位的功能和接口方面表现出色。
对于对象分类、AI 推理和自主决策制定,以实现特征识别,以便根据实时交通需求对碎片回收航天器或可重新配置的认知转发器进行后期指挥,Xilinx 的 ACAP 将产生效的基于边缘的矢量计算解决方案。神经网络的实施需要 Versal 提供的 TeraOPS 性能和特定领域的并行性。这些 7 nm 设备可能会耗电,因此请检查早期的功率预测电子表格以确保它们符合您分配的预算。QLS1046-4GB 可以以更低的功耗和更少的财务成本提供深度学习。
航天级微处理器、FPGA 和 ACAP 是互补的机载处理技术,每种技术都具有独特的优势。在轨,基于边缘的处理需要实时计算从数据源处的多个传感器获取的大量信息,需要低延迟、确定性的接口,采用小型、低功耗外形,具有独特的散热和可靠性要求.
在为密集型在轨边缘计算选择合适的机载处理器时,还需要考虑上市时间、实施和采购方面的考虑,例如,FPGA 通常需要比微处理器更多的电源轨,这意味着需要更多的稳压器,因此需要更大的 PCB 来容纳它们。FPGA 还享有更难设计的名声。对于某些项目,入轨时间可能非常短,原始设备制造商将坚持使用熟悉供应商的现有设备以加快硬件设计。一些制造商没有技能或时间来学习新的开发工具或不同的编程语言。的超深亚微米、太空级 FPGA 的六位数价格也是许多 OEM 的障碍,尤其是那些以低成本、NewSpace 应用为目标的 OEM。
下一代在轨边缘处理将结合微处理器、FPGA 和智能计算,形成一个紧密集成的异构平台。需要多种引擎类型,因为没有一种引擎能够以方式执行应用程序所需的所有任务。标量微处理器是控制、复杂决策制定和操作系统支持的理想选择,可重新配置的 FPGA 增加了处理各种要求苛刻的算法的灵活性,而智能引擎则优化了线性代数和矢量算法的计算,以用于机器学习和人工智能推理。
以下雷达图(图 4)比较了 QLS1046-4GB、的超深亚微米、航天级 FPGA 和用于在轨、基于 EDGE 的处理的 ACAP:
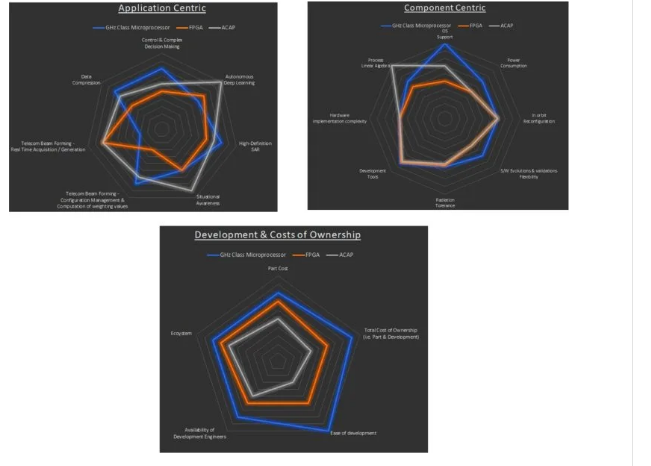
图 4: 板载处理解决方案的比较。


欢迎加入至芯科技FPGA微信学习交流群,这里有一群优秀的FPGA工程师、学生、老师、这里FPGA技术交流学习氛围浓厚、相互分享、相互帮助、叫上小伙伴一起加入吧!
点个在看你最好看
原文标题:用于密集、在轨、基于边缘的计算的微处理器和 FPGA
文章出处:【微信公众号:FPGA设计论坛】欢迎添加关注!文章转载请注明出处。
-
FPGA
+关注
关注
1663文章
22494浏览量
638991
原文标题:用于密集、在轨、基于边缘的计算的微处理器和 FPGA
文章出处:【微信号:gh_9d70b445f494,微信公众号:FPGA设计论坛】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
高性能微处理器DC - DC转换器:HIP6006/7EVAL1深度解析
电子工程师必看:MCF547x ColdFire微处理器深度解析
深入解析MCF537x ColdFire微处理器:设计与应用指南
深入解析MCF5271集成微处理器硬件特性与设计要点
低功耗微处理器监控电路的设计与应用
MAX6323/MAX6324:微处理器监控电路的卓越之选
解析ADM803/ADM809/ADM810微处理器监控电路
ADM8323/ADM8324:微处理器系统的可靠监控伙伴
MAX1232微处理器监控器:高效可靠的系统守护专家
MAXIM 纳米功耗微处理器监控电路:设计与应用指南
MAX6426:低功耗微处理器复位电路
意法半导体推出最新STM32MP21微处理器
探索NXP i.MX 93应用处理器家族:高效边缘计算的理想之选
STM32MP2微处理器技术深度解析:面向工业4.0的边缘计算核心
瑞萨电子RZ/V系列微处理器助力边缘AI开发




评论