 特斯拉的下一代AI芯片:存算一体
特斯拉的下一代AI芯片:存算一体

ChatGPT的火爆预示了自动驾驶的方向:大模型(至少超过100亿个参数)和高算力(至少1000TOPS@FP16)。ChatGPT完美展示了大模型的优势,也让英伟达欣喜若狂,英伟达、AMD和英特尔是最大受益者(英伟达最顶级的DGX-H100中的CPU是英特尔的W3495X,国内售价高达每片8万人民币),还有几乎垄断高端服务器市场的中国台湾企业广达和英业达,科技巨头每年需要花费数百亿乃至上千亿美元购买新的服务器来处理越来越大的AI模型,并且会持续数十年。
高算力让存储墙愈加明显,存储系统的成本也持续攀升,AI芯片价格越来越高,未来10万美元甚至百万美元级AI芯片也极有可能。要完美解决存储墙问题是不可能的,折中的办法是存算一体。这虽然无法解决芯片成本趋高的问题,但是可以解决1000TOPS算力的问题。
根据存储与计算的距离远近,将广义存算一体的技术方案分为三大类,分别是近存计算 (Processing Near Memory,PNM)、存内处理(Processingln Memory,PIM) 和存内计算(Computing in Memory, CIM)。其中,存内计算即狭义的存算一体。
存内计算面临的最大挑战是内存和高性能计算都是高度集中的行业,巨头们出于利润的考量,不会允许革命性的存内计算颠覆其所属的垄断行业。内存行业,美光、三星和SK Hynix在高性能存储领域市占率达100%。高性能计算领域,英特尔、AMD和英伟达的市场占有率也接近100%。台积电和三星联合垄断了高性能芯片代工领域。7纳米以下晶圆厂产能是最具话语权的武器,没有这个,高性能计算便是空中楼阁。
PNM已经非常常见,即HBM与CPU一体,所有高性能计算芯片都是如此,采用HBM堆叠,2.5D封装,硅中介层(Interposer)内联在基板上。也可以反推,没有采用HBM就不是高性能计算芯片。特斯拉二代FSD已经用上了GDDR6,下一代基本可以肯定是HBM3了。

PIM则是再下一阶段热点
图片来源:Planet
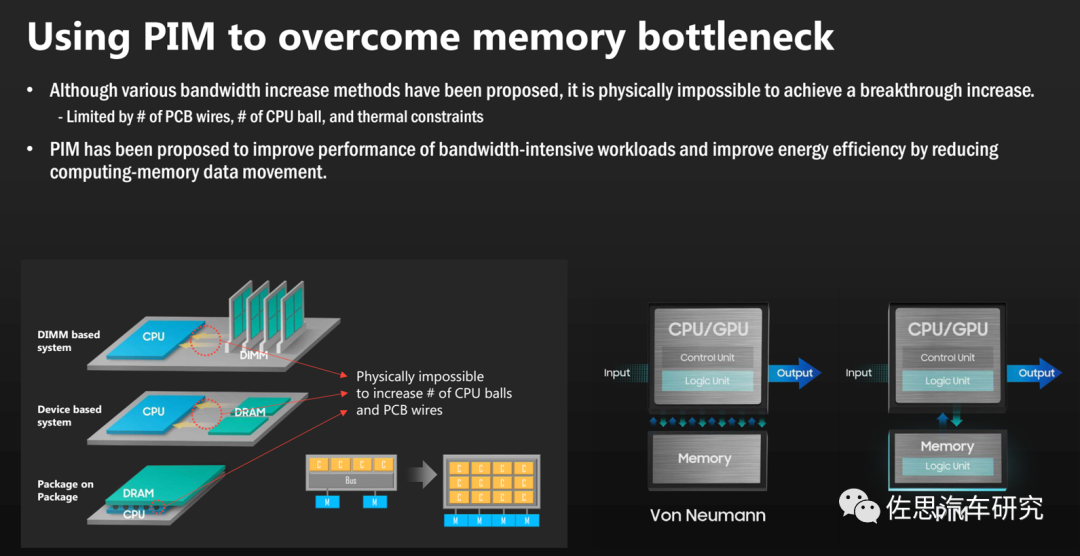
PIM已经有商业化的实例,最早的实例是Xilinx的Alveo U280
图片来源:Planet
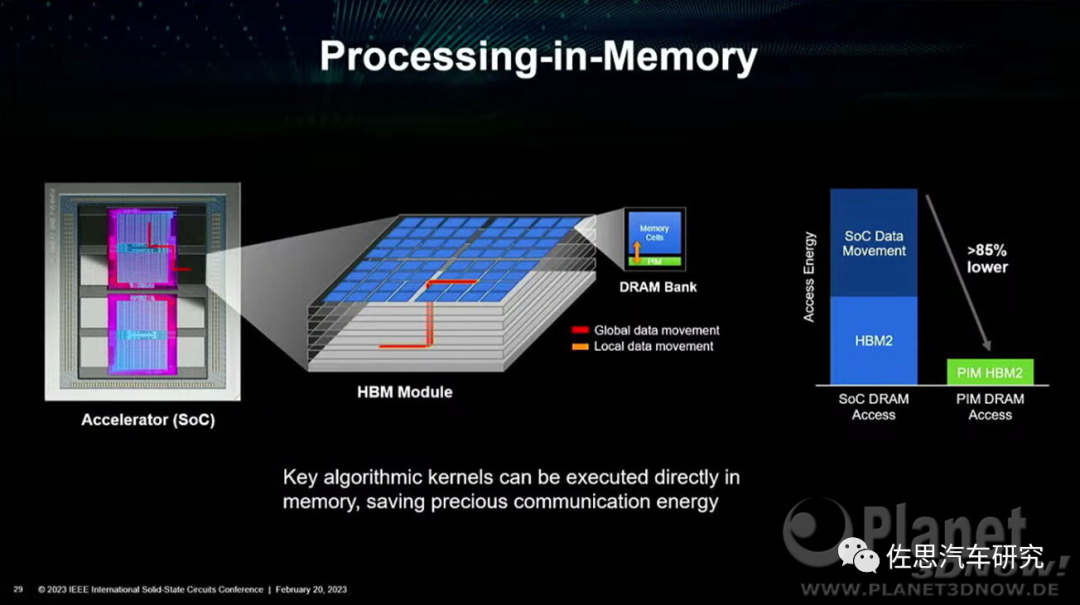
PIM可以大幅度降低存取功耗
图片来源:Planet

图片来源:三星
AMD收购Xilinx,其中最看中的就是PIM堆叠技术,AMD后来将其用在InstinctMI100/MI250/MI150/MI210系列GPU上,这也是美国商务部禁止向中国出售的芯片。MI100的性能能够超越英伟达的上一代旗舰A100,功耗较A100降低约25%,价格也低于A100约30%。MI250与英伟达新旗舰H100持平,在FP32和FP64上,MI250更强;在FP16上,H100远超MI250。
PIM的主角还是三星,配角是AMD,三星Aquabolt-XLHBM2-PIM是目前唯一PIM内存。
Aquabolt-XL HBM2-PIM架构

图片来源:三星
PIM非常简单,就是用硅通孔(Through Silicon Via, TSV)技术将计算单元塞进内存上下BANK之间。TSV技术人类2010年就掌握了,只不过迄今还不算特别成熟,价格还是有点高。
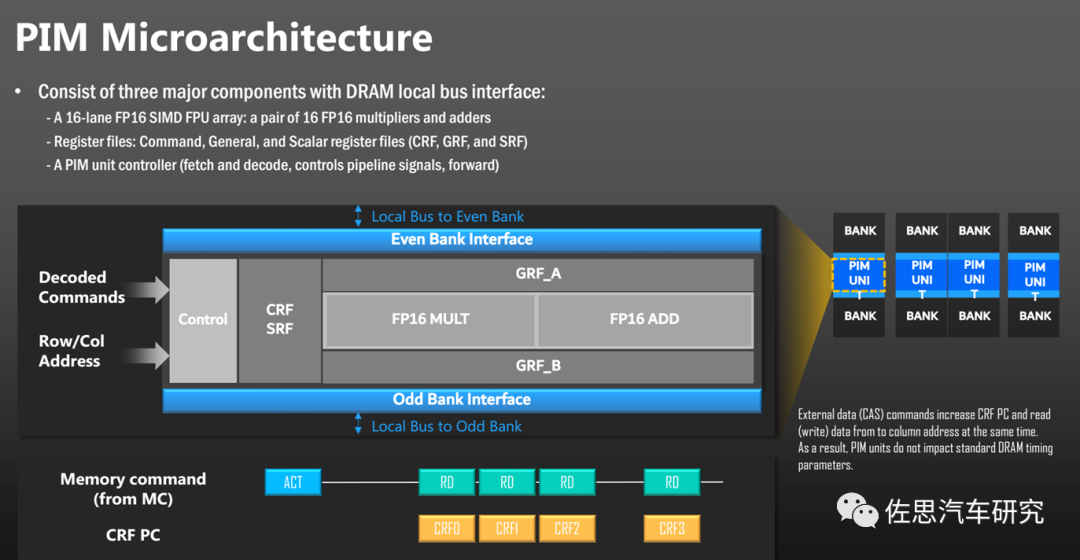
图片来源:三星
计算单元很简单,一个FP16矩阵乘法,一个FP16矩阵加法。输入命令解码和行列地址即可。
PIM运作模式
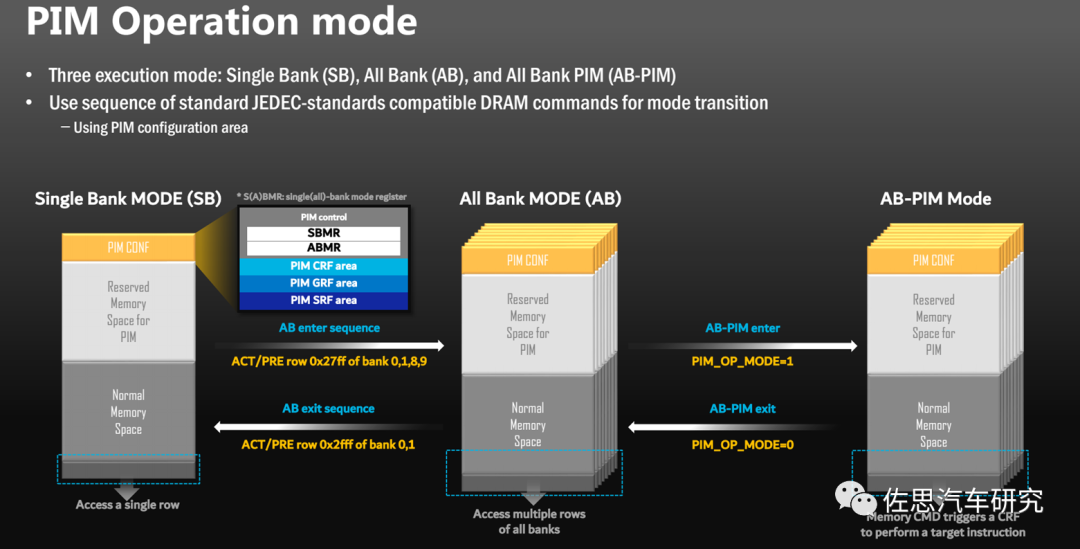
图片来源:三星
PIM的软件栈

图片来源:三星
在2023CES消费电子展上,AMD推出了MI300,PIM似乎升级到了HBM3。

图片来源:AMD
国人一心打破美国的科技垄断,由于缺乏先进2.5D和3D封装产能和技术,中国企业对PNM和PIM完全不感兴趣,聚焦的是真正的存算一体,即存内计算。
其本质是利用不同存储介质的物理特性,对存储电路进行重新设计使其同时具备计算和存储能力,直接消除“存〞“算〞界限,使计算能效达到数量级提升的目标。在存储原位上实现计算,是真正的存算一体。存算一体理论上完美,但目前离实用至少还有10年距离。
存内计算主要包含数字和模拟两种实现方式,二者适用于不同应用场景。模拟存内计算能效高,但误差较大,适用于低精度、低功耗计算场景,如端侧可穿戴设备等。模拟存内计算还涉及复杂的模数转换器(ADC)、数模转换器(DAC)、跨阻放大器(TIA) 等模块。ADC和DAC领域需要几十年经验长期摸索,全球精通ADC和DAC的仅有ADI、德州仪器和NXP三家,其中ADI最强,正是牵涉大量模拟部分,存内计算无法使用EDA工具,导致芯片开发成本高、周期长、规模小、算力低。
一直以来,主流的存内计算大多采用模拟计算实现,近两年数字存内计算的研究热度也有所提升。模拟存内计算主要基于物理定律(欧姆定律和基尔霍夫定律),在存算阵列上实现乘加运算。数字存内计算通过在存储阵列内部加入逻辑计算电路,如与门和加法器等,使数字存内计算阵列具备存储及计算能力。数字存内计算精度高,但是其存储单元只能存储单比特数据,而目前主流人工智能训练是32或64比特数据,这严重限制了其应用范围,并且数字存内计算需增加加法树逻辑电路,很大程度上限制了面积及能效优势。也就是目前存内计算在高算力领域没有容身之地的原因。
存内计算最重要的部分就是存储器件本身,算法之类的软件部分几乎可以忽略。目前存储器主要有易失性存储器和非易失存储器件。易失性存储器在设备掉电之后数据丢失,如SRAM等。非易失性存储器在设备掉电后数据可保持不变,如NOR Flash、可变电阻随机存储器 (Resistive Random Access Memory, RRAM或ReRAM)、磁性随机存储器(Magnetoresistive Random Access Memory, MRAM)、相变存储器 (Phase ChangeMemory, PCM)等。中国企业或机构主要研究的是铁电晶体管FeFET。传统的SRAM、DRAM、NAND被三星、美光和SK Hynix垄断,因此基于传统存储的存内计算无论如何都无法对抗这三大巨头,大部分机构或企业都选择另辟蹊径。
几种新兴存储器的技术对比
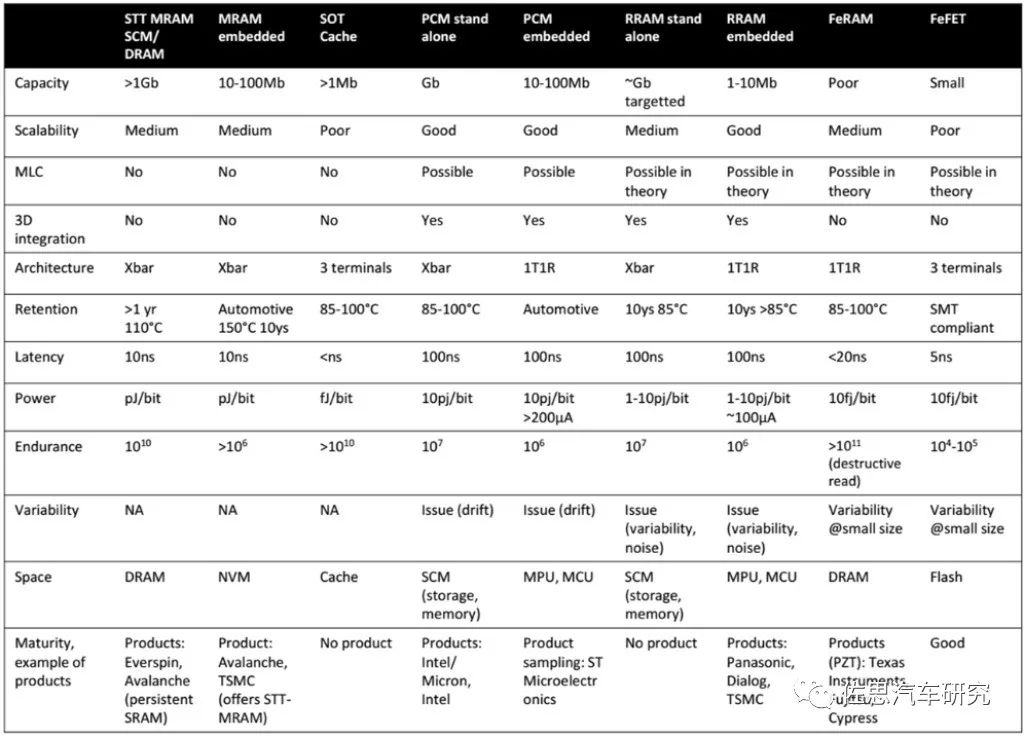
需要指出,目前存储器制造也需要EUV***了,而EUV***被ASML垄断,又听命于美国政府。通常认为,DRAM的天花板是10nm。其原因是在传统1T1C架构下,单位元件面积不断减小,如何保证电容能够存储足够的电荷、防止相邻存储单元之间的耦合,是DRAM推进到10nm以下的无解难题,而EUV是用来做7nm以下的,DRAM目前主流是14纳米。14纳米理论上完全可以用DUV来完成,不需要EUV。
但实际情况并非如此,三星电子的1Znm节点DRAM量产结果表明,相比于DUV浸没式光学***,EUV***极大简化了制造流程,不仅可以大幅度提高光刻分辨率和DRAM性能,而且可以减少所使用的掩模数量,从而减少流程步骤的数量,减少缺陷、提高存储密度,并大幅降低DRAM生产成本,缩短生产周期。也就是说,即使EUV掩模费用(达数百万美元)远高于DUV掩模费用,使用EUV***量产DRAM也具有更高的性价比。三星电子和SK海力士公司将EUV***引入1Znm节点DRAM的量产进展顺利,并一路高歌到第五代1β节点,令DRAM三巨头中最为保守的美光公司很无奈。美光一度宣称自己用DUV也做到了11纳米,然而进入2023年后的DDR5时代,韩国双雄再一次依靠EUV***碾压了美光。美光在DDR5方面严重落后韩国双雄。
全球智能汽车领域,特斯拉是第一个用上GDDR6的企业,特斯拉也很可能第一个用上HBM2或HBM3,当然代价是芯片成本超过1000美元以上,不过以特斯拉的溢价能力,消费者愿意为高价买单。要想超越特斯拉,不如一步到位,直接上HBM3。当然了,对中国企业来说最困难的不是技术,而是供应链,晶圆级2.5D封装HBM的产能95%都在台积电手中,5%在三星手中。
审核编辑 :李倩
-
存储器
+关注
关注
39文章
7757浏览量
172210 -
存储
+关注
关注
13文章
4892浏览量
90290 -
AI芯片
+关注
关注
17文章
2165浏览量
36869
原文标题:特斯拉的下一代AI芯片:存算一体
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
安克创新发布Thus™芯片:存算一体架构重塑AI音频新生态
新思科技AI+EDA推动下一代SoC发展
伟创力携手博通,推进下一代AI液冷解决方案落地


AI存算一体,这家ReRAM新型存储受关注


Telechips与Arm合作开发下一代IVI芯片Dolphin7
存算一体AI芯片公司九天睿芯完成超亿元B轮融资
后摩尔定律时代,3D-CIM+RISC-V打造国产存算一体新范式

芯动科技与知存科技达成深度合作

存算一体技术加持!后摩智能 160TOPS 端边大模型AI芯片正式发布

2025端侧AI芯片爆发:存算一体、非Transformer架构谁主浮沉?边缘计算如何选型?
缓解高性能存算一体芯片IR-drop问题的软硬件协同设计
苹芯科技 N300 存算一体 NPU,开启端侧 AI 新征程




评论