 一次JVM GC长暂停的排查过程
一次JVM GC长暂停的排查过程

作者 | 京东云开发者-京东科技徐传乐
背景
在高并发下,Java 程序的 GC 问题属于很典型的一类问题,带来的影响往往会被进一步放大。不管是「GC 频率过快」还是「GC 耗时太长」,由于 GC 期间都存在 Stop The World 问题,因此很容易导致服务超时,引发性能问题。
事情最初是线上某应用垃圾收集出现 Full GC 异常的现象,应用中个别实例 Full GC 时间特别长,持续时间约为 15~30 秒,平均每 2 周左右触发一次;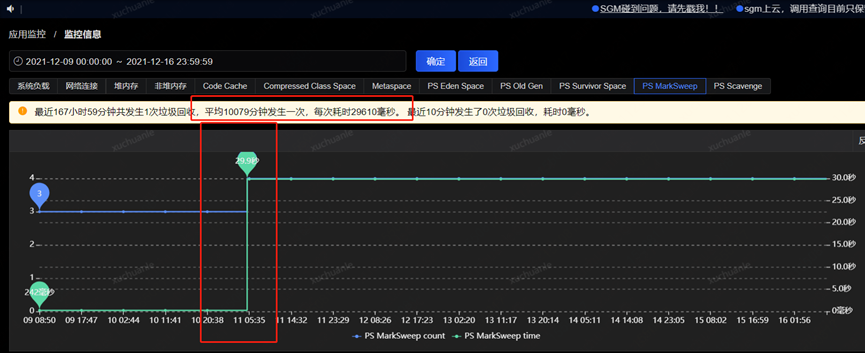
JVM 参数配置 “-Xms2048M –Xmx2048M –Xmn1024M –XX:MaxPermSize=512M”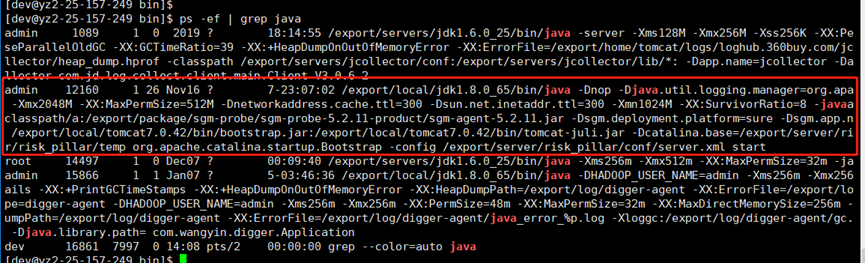
排查过程
Ø分析 GC 日志
GC 日志它记录了每一次的 GC 的执行时间和执行结果,通过分析 GC 日志可以调优堆设置和 GC 设置,或者改进应用程序的对象分配模式。
这里 Full GC 的 reason 是 Ergonomics,是因为开启了 UseAdaptiveSizePolicy,jvm 自己进行自适应调整引发的 Full GC。
这份日志主要体现 GC 前后的变化,目前为止看不出个所以然来。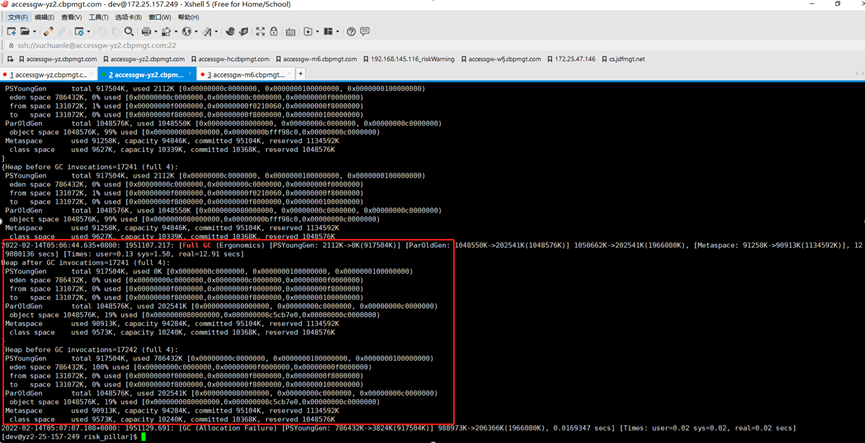
开启 GC 日志,需要添加如下 JVM 启动参数:
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/export/log/risk_pillar/gc.log
常见的 Young GC、Full GC 日志含义如下: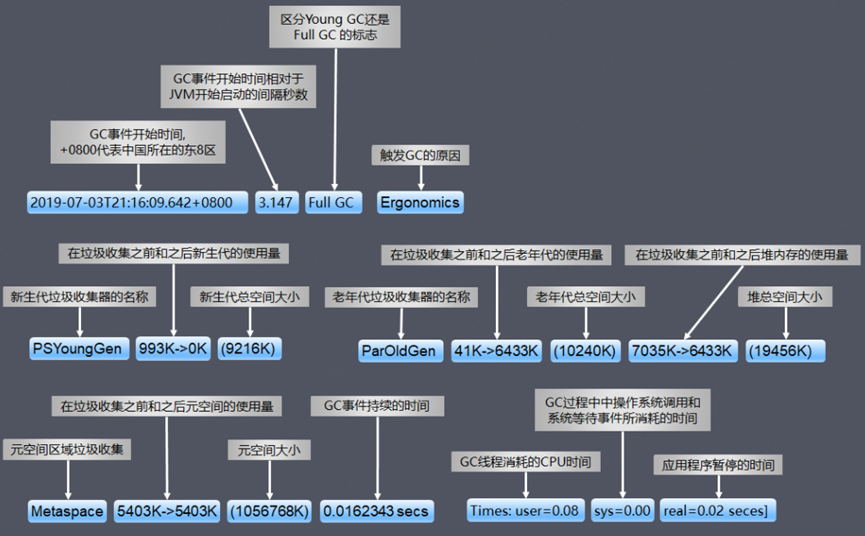
Ø进一步查看服务器性能指标
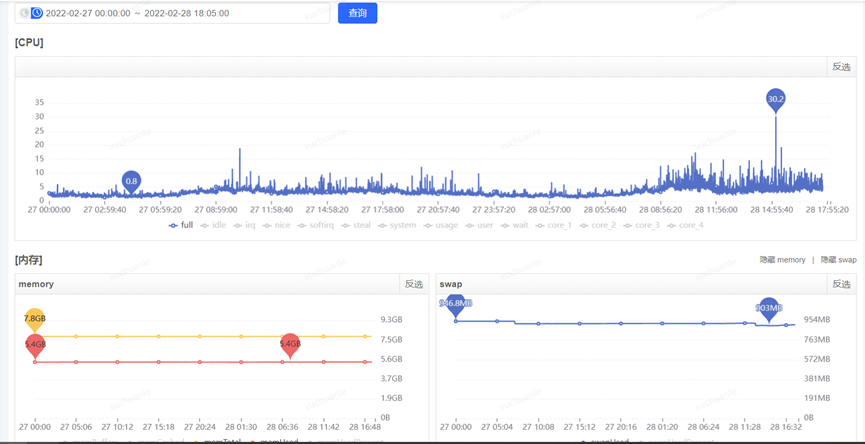
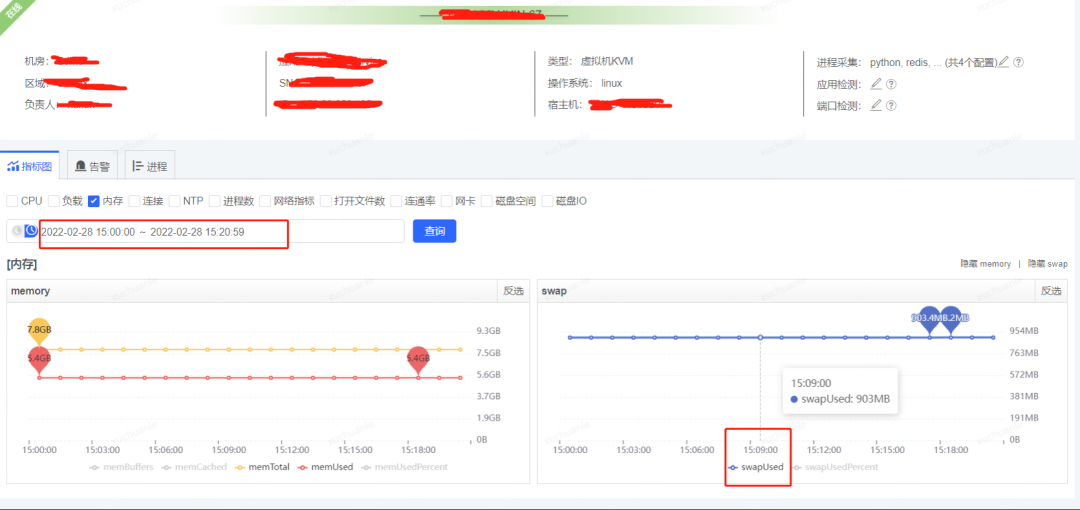
获取到了 GC 耗时的时间后,通过监控平台获取到各个监控项,开始排查这个时点有异常的指标,最终分析发现,在 5.06 分左右(GC 的时点),CPU 占用显著提升,而 SWAP 出现了释放资源、memory 资源增长出现拐点的情况(详见下图红色框,橙色框中的变化是因修改配置导致,后面会介绍,暂且可忽略)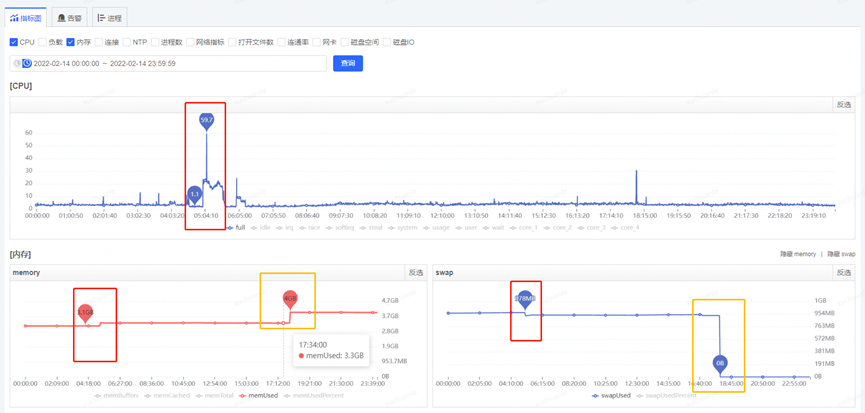
JVM 用到了swap?是因为 GC 导致的 CPU 突然飙升,并且释放了 swap 交换区这部分内存到 memory?
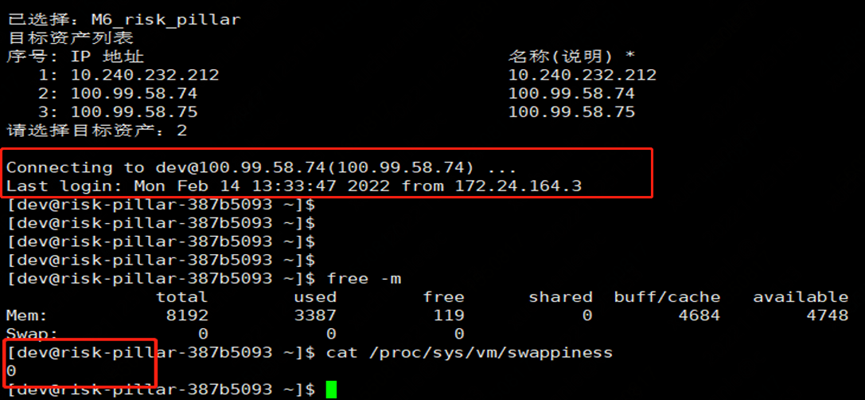
为了验证 JVM 是否用到 swap,我们通过检查 proc 下的进程内存资源占用情况
| for i in $(cd /proc;ls |grep "^[0-9]"|awk ' $0 >100') ;do awk '/Swap:/{a=a+$2} END {print '"$i"',a/1024"M"}' /proc/$i/smaps 2>/dev/null ; done | sort -k2nr | head -10 # head -10 表示 取出 前 10 个内存占用高的进程 # 取出的第一列为进程的 id 第二列进程占用 swap 大小 | | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
看到确实有用到 305MB 的 swap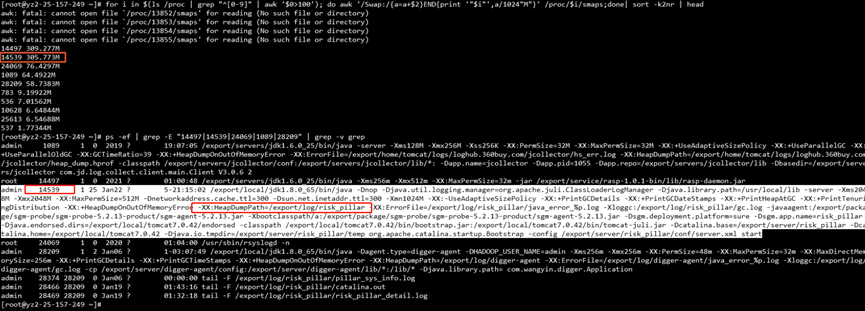
这里简单介绍下什么是swap?
swap 指的是一个交换分区或文件,主要是在内存使用存在压力时,触发内存回收,这时可能会将部分内存的数据交换到 swap 空间,以便让系统不会因为内存不够用而导致 oom 或者更致命的情况出现。
当某进程向 OS 请求内存发现不足时,OS 会把内存中暂时不用的数据交换出去,放在 swap 分区中,这个过程称为 swap out。
当某进程又需要这些数据且 OS 发现还有空闲物理内存时,又会把 swap 分区中的数据交换回物理内存中,这个过程称为 swap in。
为了验证 GC 耗时与 swap 操作有必然关系,我抽查了十几台机器,重点关注耗时长的 GC 日志,通过时间点确认到 GC 耗时的时间点与 swap 操作的时间点确实是一致的。
进一步查看虚拟机各实例 swappiness 参数,一个普遍现象是,凡是发生较长 Full GC 的实例都配置了参数 vm.swappiness = 30(值越大表示越倾向于使用 swap);而 GC 时间相对正常的实例配置参数 vm.swappiness = 0(最大限度地降低使用 swap)。
swappiness 可以设置为 0 到 100 之间的值,它是 Linux 的一个内核参数,控制系统在进 行 swap 时,内存使用的相对权重。
Ø swappiness=0: 表示最大限度使用物理内存,然后才是 swap 空间
Ø swappiness=100: 表示积极的使用 swap 分区,并且把内存上的数据及时的交换到 swap 空间里面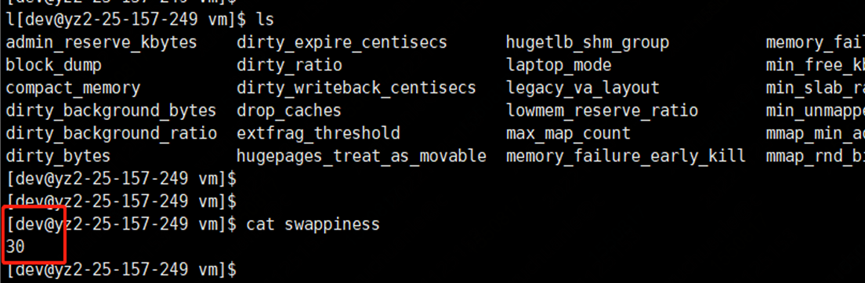
对应的物理内存使用率和 swap 使用情况如下
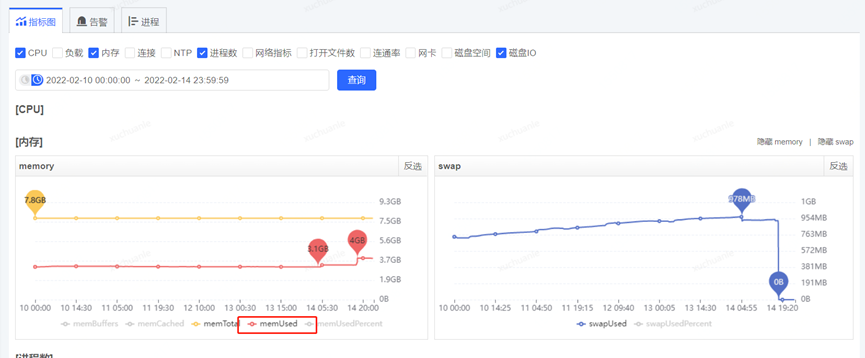
至此,矛头似乎都指向了 swap。
Ø问题分析
当内存使用率达到水位线 (vm.swappiness) 时,linux 会把一部分暂时不使用的内存数据放到磁盘 swap 去,以便腾出更多可用内存空间;
当需要使用位于 swap 区的数据时,再将其换回内存中,当 JVM 进行 GC 时,需要对相应堆分区的已用内存进行遍历;
假如 GC 的时候,有堆的一部分内容被交换到 swap 空间中,遍历到这部分的时候就需要将其交换回内存,由于需要访问磁盘,所以相比物理内存,它的速度肯定慢的令人发指,GC 停顿的时间一定会非常非常恐怖;
进而导致 Linux 对 swap 分区的回收滞后(内存到磁盘换入换出操作十分占用 CPU 与系统 IO),在高并发 / QPS 服务中,这种滞后带来的结果是致命的 (STW)。
Ø问题解决
至此,答案似乎很清晰,我们只需尝试把 swap 关闭或释放掉,看看能否解决问题?
如何释放 swap?
设置 vm.swappiness=0(重启应用释放 swap 后生效),表示尽可能不使用交换内存
a、 临时设置方案,重启后不生效
设置 vm.swappiness 为 0
sysctl vm.swappiness=0
查看 swappiness 值
cat /proc/sys/vm/swappiness
b、 永久设置方案,重启后仍然生效
vi /etc/sysctl.conf
添加
vm.swappiness=0
关闭交换分区 swapoff –a
前提:首先要保证内存剩余要大于等于 swap 使用量,否则会报 Cannot allocate memory!swap 分区一旦释放,所有存放在 swap 分区的文件都会转存到物理内存上,可能会引发系统 IO 或者其他问题。
a、 查看当前 swap 分区挂载在哪?
b、 关停分区
关闭 swap 交换区后的内存变化见下图橙色框,此时 swap 分区的文件都转存到了物理内存上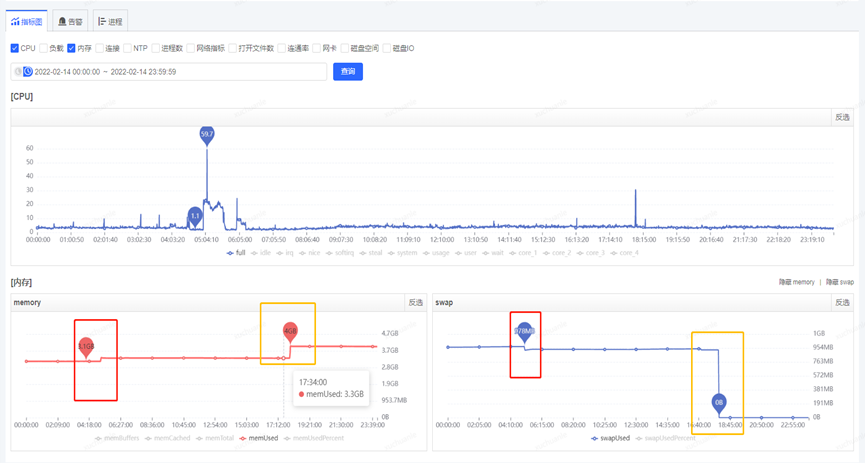
关闭 Swap 交换区后,于 2.23 再次发生 Full GC,耗时 190ms,问题得到解决。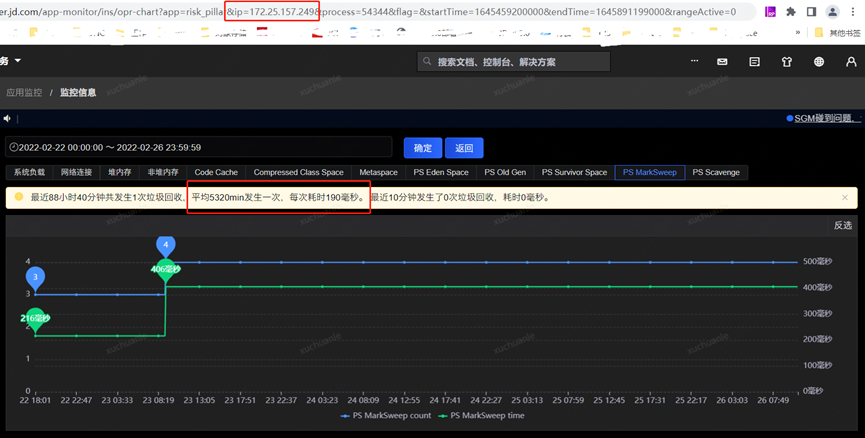
Ø疑惑
1、 是不是只要开启了 swap 交换区的 JVM,在 GC 的时候都会耗时较长呢?
2、 既然 JVM 对 swap 如此不待见,为何 JVM 不明令禁止使用呢?
3、 swap 工作机制是怎样的?这台物理内存为 8g 的 server,使用了交换区内存(swap),说明物理内存不够使用了,但是通过 free 命令查看内存使用情况,实际物理内存似乎并没有占用那么多,反而 Swap 已占近 1G?
free:除了 buff/cache 剩余了多少内存
shared:共享内存
buff/cache:缓冲、缓存区内存数(使用过高通常是程序频繁存取文件)
available:真实剩余的可用内存数
大家可以想想,关闭交换磁盘缓存意味着什么?
其实大可不必如此激进,要知道这个世界永远不是非 0 即 1 的,大家都会或多或少选择走在中间,不过有些偏向 0,有些偏向 1 而已。
很显然,在 swap 这个问题上,JVM 可以选择偏向尽量少用,从而降低 swap 影响,要降低 swap 影响有必要弄清楚 Linux 内存回收是怎么工作的,这样才能不遗漏任何可能的疑点。
先来看看 swap 是如何触发的?
Linux 会在两种场景下触发内存回收,一种是在内存分配时发现没有足够空闲内存时会立刻触发内存回收;另一种是开启了一个守护进程(kswapd 进程)周期性对系统内存进行检查,在可用内存降低到特定阈值之后主动触发内存回收。
通过如下图示可以很容易理解,详细信息参见。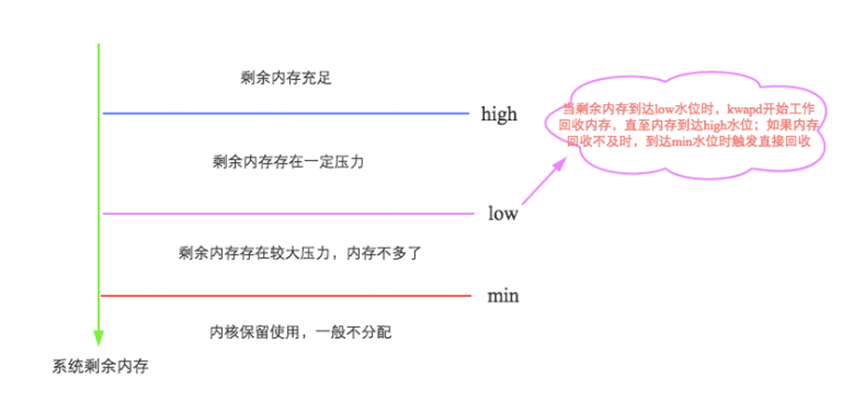
解答是不是只要开启了 swap 交换区的 JVM,在 GC 的时候都会耗时较长
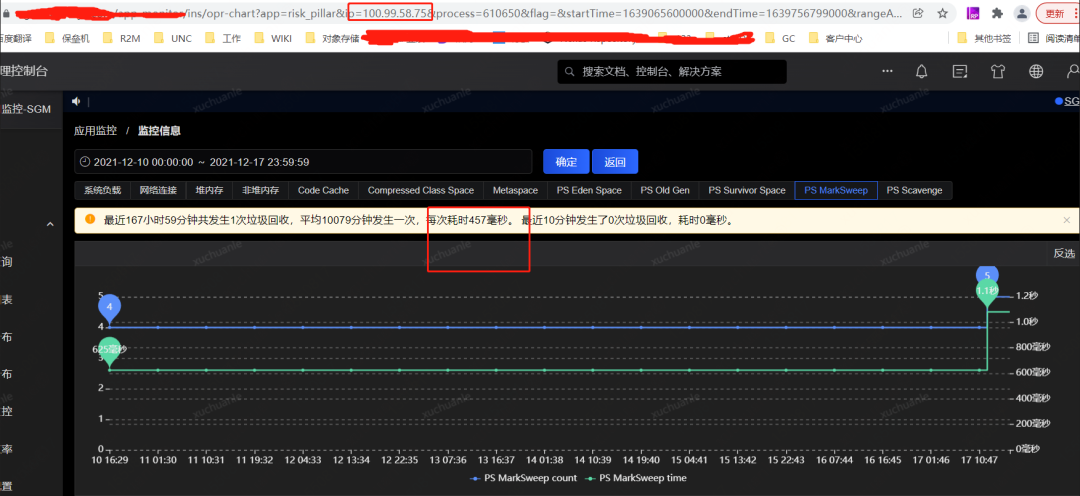
笔者去查了一下另外的一个应用,相关指标信息请见下图。
实名服务的 QPS 是非常高的,同样能看到应用了 swap,GC 平均耗时 576ms,这是为什么呢?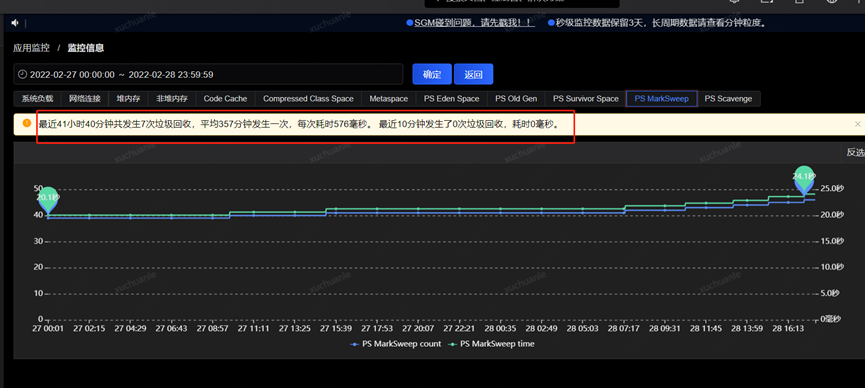
通过把时间范围聚焦到发生 GC 的某一时间段,从监控指标图可以看到 swapUsed 没有任何变化,也就是说没有 swap 活动,进而没有影响到垃级回收的总耗时。 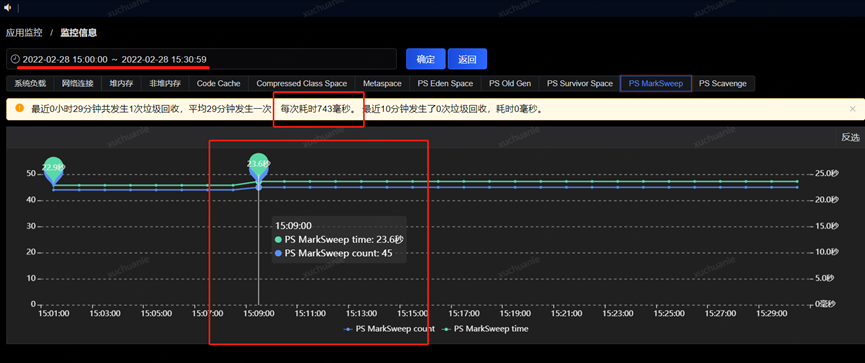
通过如下命令列举出各进程 swap 空间占用情况,很清楚的看到实名这个服务 swap 空间占用的较少(仅 54.2MB) 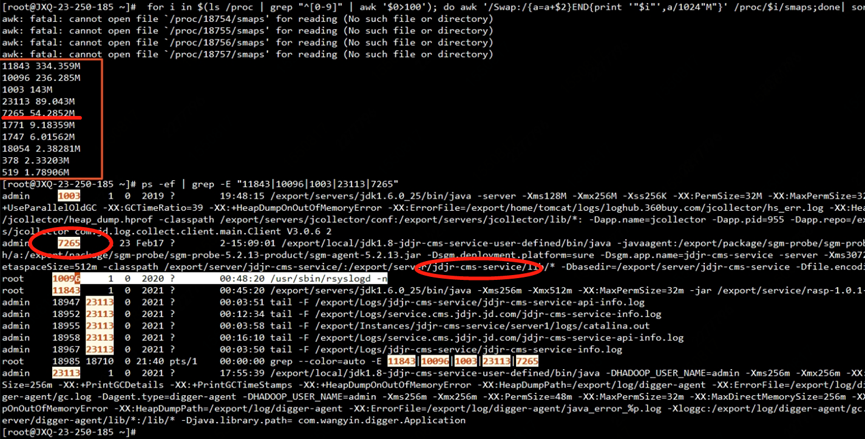
另一个显著的现象是实名服务 Full GC 间隔较短(几个小时一次),而我的服务平均间隔 2 周一次 Full GC 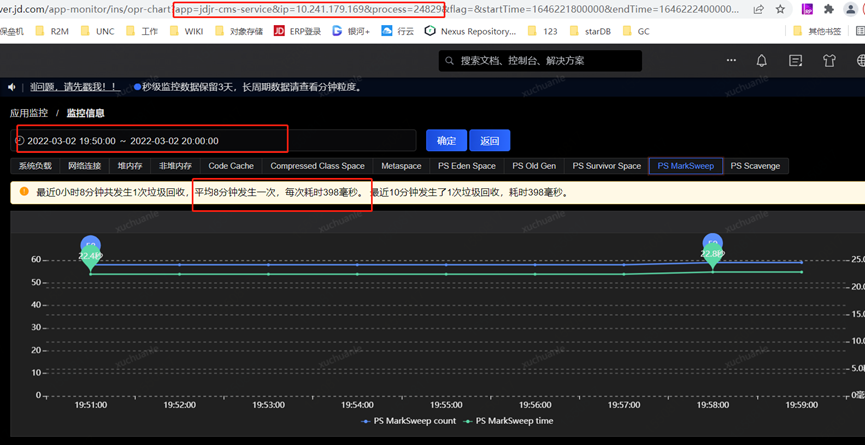
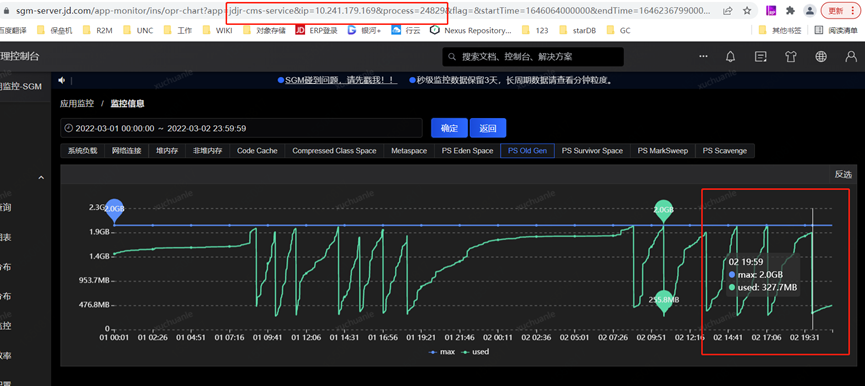
基于以上推测
1、 实名服务由于 GC 间隔较短,内存中的东西根本没有机会置换到 swap 中就被回收了,GC 的时候不需要将 swap 分区中的数据交换回物理内存中,完全基于内存计算,所以要快很多
2、 将哪些内存数据置换进 swap 交换区的筛选策略应该是类似于 LRU 算法(最近最少使用原则)
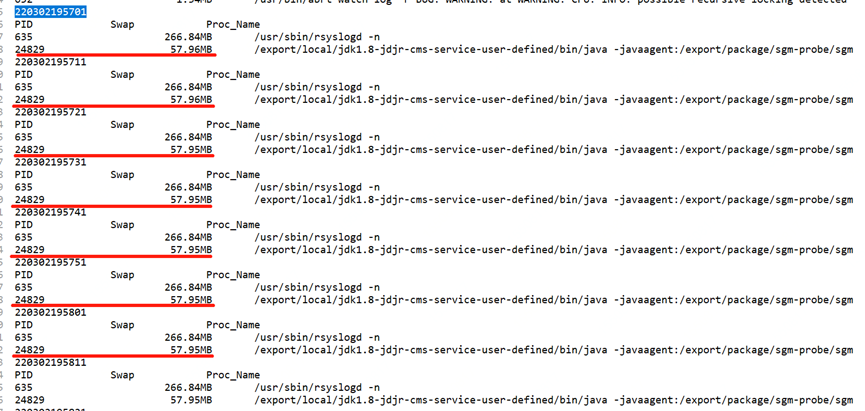
为了证实上述猜测,我们只需跟踪 swap 变更日志,监控数据变化即可得到答案,这里采用一段 shell 脚本实现
#!/bin/bash
echo -e `date +%y%m%d%H%M%S`
echo -e "PID Swap Proc_Name"
#拿出/proc目录下所有以数字为名的目录(进程名是数字才是进程,其他如sys,net等存放的是其他信息)
for pid in `ls -l /proc | grep ^d | awk '{ print $9 }'| grep -v [^0-9]`
do
if [ $pid -eq 1 ];then continue;fi
grep -q "Swap" /proc/$pid/smaps 2>/dev/null
if [ $? -eq 0 ];then
swap=$(gawk '/Swap/{ sum+=$2;} END{ print sum }' /proc/$pid/smaps) #统计占用的swap分区的 大小 单位是KB
proc_name=$(ps aux | grep -w "$pid" | awk '!/grep/{ for(i=11;i<=NF;i++){ printf("%s ",$i); }}') #取出进程的名字
if [ $swap -gt 0 ];then #判断是否占用swap 只有占用才会输出
echo -e "${pid} ${swap} ${proc_name100}"
fi
fi
done | sort -k2nr | head -10 | gawk -F' ' '{ #排序取前 10
pid[NR]=$1;
size[NR]=$2;
name[NR]=$3;
}
END{
for(id=1;id<=length(pid);id++)
{
if(size[id]<1024)
printf("%-10s %15sKB %s
",pid[id],size[id],name[id]);
else if(size[id]<1048576)
printf("%-10s %15.2fMB %s
",pid[id],size[id]/1024,name[id]);
else
printf("%-10s %15.2fGB %s
",pid[id],size[id]/1048576,name[id]);
}
}'
由于上面图中 2022.3.2 1900 至 2022.3.2 1900 发生了一次 Full GC,我们重点关注下这一分钟内 swap 交换区的变化即可,我这里每 10s 做一次信息采集,可以看到在 GC 时点前后,swap 确实没有变化
通过上述分析,回归本文核心问题上,现在看来我的处理方式过于激进了,其实也可以不用关闭 swap,通过适当降低堆大小,也是能够解决问题的。
这也侧面的说明,部署 Java 服务的 Linux 系统,在内存分配上并不是无脑大而全,需要综合考虑不同场景下 JVM 对 Java 永久代 、Java 堆 (新生代和老年代)、线程栈、Java NIO 所使用内存的需求。
总结
综上,我们得出结论,swap 和 GC 同一时候发生会导致 GC 时间非常长,JVM 严重卡顿,极端的情况下会导致服务崩溃。
主要原因是:JVM 进行 GC 时,需要对对应堆分区的已用内存进行遍历,假如 GC 的时候,有堆的一部分内容被交换到 swap 中,遍历到这部分的时候就须要将其交换回内存;更极端情况同一时刻因为内存空间不足,就需要把内存中堆的另外一部分换到 SWAP 中去,于是在遍历堆分区的过程中,会把整个堆分区轮流往 SWAP 写一遍,导致 GC 时间超长。线上应该限制 swap 区的大小,如果 swap 占用比例较高应该进行排查和解决,适当的时候可以通过降低堆大小,或者添加物理内存。
因此,部署 Java 服务的 Linux 系统,在内存分配上要慎重。
以上内容希望可以起到抛转引玉的作用,如有理解不到位的地方烦请指出。
-
Linux
+关注
关注
88文章
11822浏览量
219600 -
服务器
+关注
关注
14文章
10371浏览量
91772 -
JAVA
+关注
关注
20文章
3012浏览量
116874 -
JVM
+关注
关注
0文章
161浏览量
13088 -
日志
+关注
关注
0文章
149浏览量
11098
原文标题:一次JVM GC长暂停的排查过程
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
波特率漂移导致通信异常的故障排查过程
看看基于JDK中自带JVM工具的用法
Native Memory Tracking 详解(4):使用 NMT 协助排查内存问题案例
一次呼叫典型流程
DC-DC电源故障排查过程和总结,珍贵的经验!资料下载

JVM CPU使用率飙高问题的排查分析过程

JVM的一些重要参数
jvm内存溢出故障排查
记录一次使用easypoi时与源码博弈的过程

记一次JSF异步调用引起的接口可用率降低
Java应用OOM问题的排查过程



评论