 多核处理器系统如何维护cache一致性
多核处理器系统如何维护cache一致性

汽车作为一种传统的工业产品,如今也随着科技发展不断推陈出新。如果说动力系统是汽车的心脏,那么车载芯片就是汽车的大脑。随着不断有先进的工艺和架构应用于车载芯片领域,车载芯片得性能日益提升,用以支持多样化的娱乐功能和贴心的辅助驾驶功能,为人们提供了更好的驾乘体验。在单核处理器不能满足车载芯片对性能的需求时,车载芯片会采用多核处理器架构以达到更高的处理能力。每个处理器都带有缓存数据的组件(cache),多核系统设计需要考虑处理器缓存数据的一致性,防止处理器使用过时的数据从而导致运行出错。因此一致性总线应运而生,它保证了各个处理器缓存数据的一致性,使得多个处理器可以共同处理同一项事务,让处理器的性能得到了很好得发挥。本文从一致性总线的由来、结构和功能等方面,对其进行了简单介绍,希望能给读者带来一些启发。
总线的由来
总线最早是源于计算机系统的一个专业术语,是计算机各功能部件之间传送信息的公共通信干线。在芯片系统中也把连接芯片中各个组件的公共线路称为总线。总线由地址线(传送地址信息)、数据线(传送数据信息)以及控制线(传送控制信息)三类组成。在传输过程中发起请求的一方称为主设备,返回响应一方称为从设备。以CPU访问DDR为例,当CPU发起读访问时,总线将读请求和读地址发送到DDR控制器,DDR的控制器收到读请求后,根据读地址将DDR中对应的数据取出并送到总线处,总线再将数据送到CPU,此时读访问结束;当CPU发起写访问时,总线将写请求、写地址和写数据发送到DDR控制器,当DDR完成写数据的存储后,发送写应答到总线处,总线再将其发送给CPU,此时写访问结束。
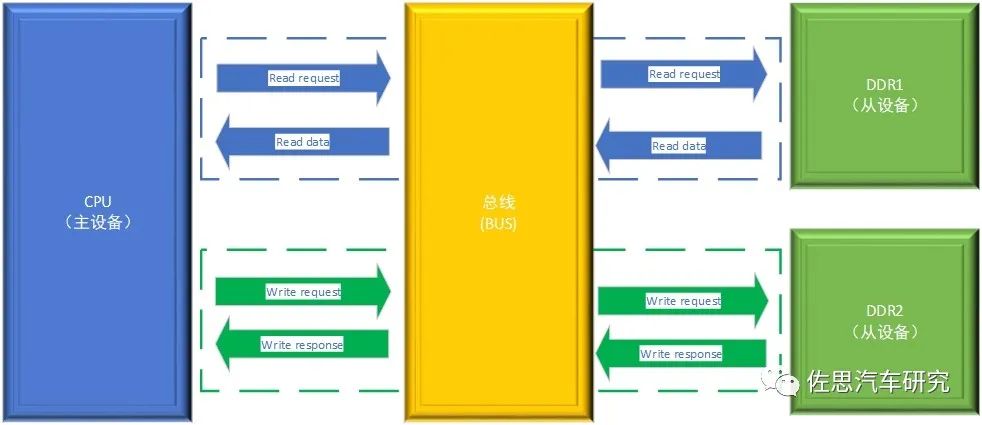
CPU读写DDR示意图
随着对运算能力(计算速度和计算规模)需求的不断提高,在单核CPU无法满足计算需求的情况下,多核CPU计算机系统应运而生。目前的芯片系统中通常会包含多个CPU、DDR和外设,即总线上连接有多个主设备和多个从设备,各个CPU都可以使用总线访问DDR。总线的英文名称“BUS”形象地描述各位“乘客”(各个主设备的请求)都可以乘坐“BUS”去往相应的“目的地”(从设备),从设备的响应也可以通过总线返回对应的主设备,此时总线可以理解为共享的信息通路,总线把各个组件需要传递的信息运送到相应的目的地。
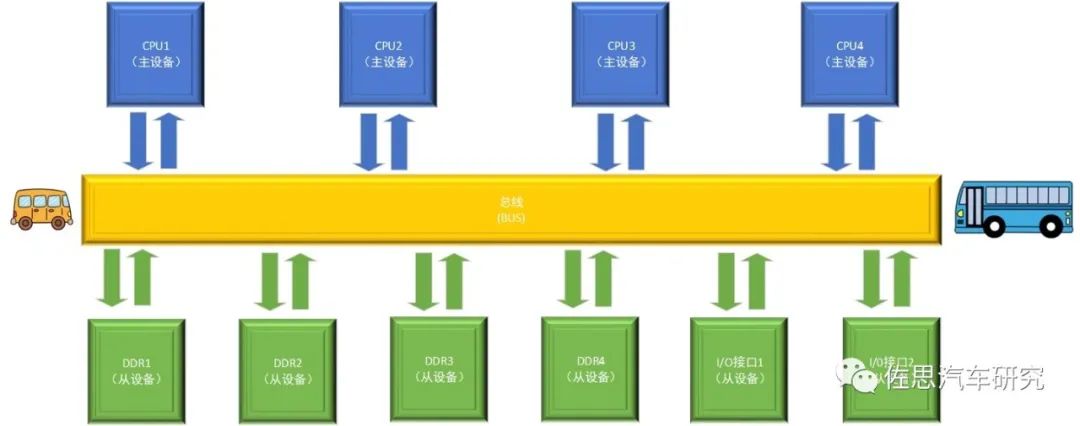
多路主从设备总线示意图
Cache的由来 提高CPU运算能力的方式之一就是提高CPU工作频率,但是单单提高CPU频率带来的性能提升是有限的,芯片的系统性能还取决于系统架构、指令结构、信息在各个部件之间的传送速度以及存储部件的存取速度等因素,特别是CPU与主存之间的存取速度。如果CPU工作速率高于DDR工作速率,就会造成CPU等待,降低芯片性能,浪费CPU运算能力。 此外如果CPU每次访问DDR都要经过总线,然而总线上的资源是有限的,CPU之间中会存在竞争关系,从中产生的延时也会浪费CPU的运算能力。因此Cache应运而生,在DDR和CPU之间加入cache,cache使用速度快而容量小的SRAM来搭建,CPU在读取数据时优先访问cache,如果cache中有相应的数据,即命中,则从cache中获取。反之,如果cache中不存在对应的数据,再通过总线访问DDR。Cache的优点在于既能满足一部分快速读写,又不会增加过多的芯片开销。
多核处理器系统如何维护cache一致性 在多核处理器系统中引入cache之后,每个CPU都有对应的cache,每个CPU都会对相应的cache进行读写操作,由于多个CPU可能对同一地址进行读写操作,当某个CPU对共享cache line进行写操作时,其它CPU的cache中该数据块的副本将成为过时的数据。如果不及时地通知相应的CPU,将导致错误的运行结果。如何保证同一地址的数据在不同cache保持一致成为大家需要考虑的问题。多核处理器系统数据一致性不仅仅涉及各个cache之间的一致性问题,也包含cache和DDR中数据的一致性问题。 我们基于MOESI cache一致性协议假设:CPU A、CPU B以及DDR都保存有同一cache line数据,如果CPU A想要对此cache line中的数据进行改写,那么总线会先使CPU B中的该 cache line无效,之后CPU A再对其cache line进行改写,此时DDR中该cache line的数据也成为了旧的不可用数据,如果CPU B需要使用该cache line的数据就需要向总线发起读请求重新获取新的数据,总线从CPU A的cache中获取改写后的新数据并发送给CPU B的cache;当CPU A和CPU B的cache不再保留该cache line时需要通过总线将其写回到DDR中。可以看出此时的总线具有管理各CPU cache一致性的功能,被称为一致性总线(Coherent Bus)。
目前CPU大部分的数据访问操作都是通过cache完成,不需要和DDR交互,所以cache的出现除了提高CPU访问数据的效率,又极大的节约了总线带宽,进而使系统可容纳的CPU数目增加。当然,维护cache一致性需要一些额外的总线transaction,这稍稍降低了实际的节约量。
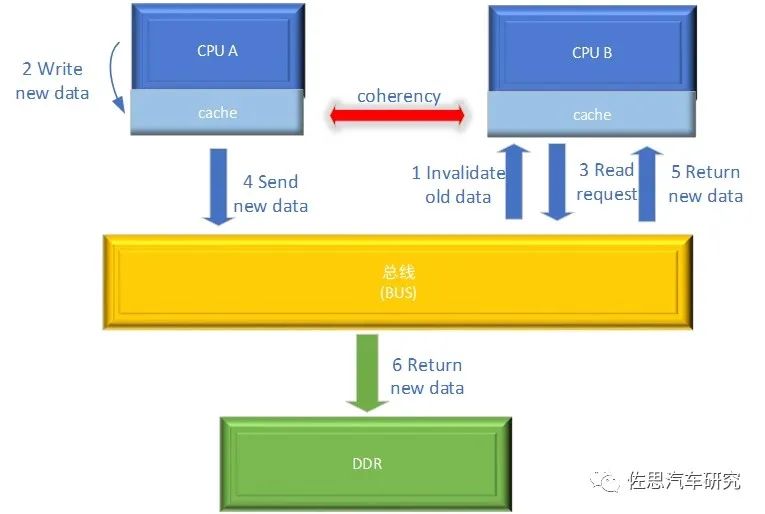
Cache中数据一致性维护示意图
总线在维护cache一致性时,通知相关cache的操作称为snoop;snoop操作分为两种类型:全部通知和精准通知。
全部通知就是通知所有的cache来查询自身是否有与此操作相关的cache line, 这种做法的缺点是由于共享的cache line毕竟是少数的,所以CPU需要处理很多与自身不相关的snoop请求,从而增加CPU的资源开销。由于多数snoop都是无效的,因此全部通知也会浪费总线的资源。
精准通知是指总线会记录各个cache中cache line的信息,当有请求时,先通过snoop filter来筛选出相关的cache并发送snoop。Snoopfilter中记录了各个cache line的地址信息和状态信息。目前一致性总线大多采用精准通知的方式,虽然snoop filter增加了总线的资源开销,但是减少了CPU侧的资源开销,同时也避免总线发送不必要的snoop。
一致性总线通过snoop filter来记录各个cache中的cache line状态,在总线的视角中,cache中每个cache line的状态都在掌握之中。而常用的cache一致性协议包含两种:MESI和MOESI。
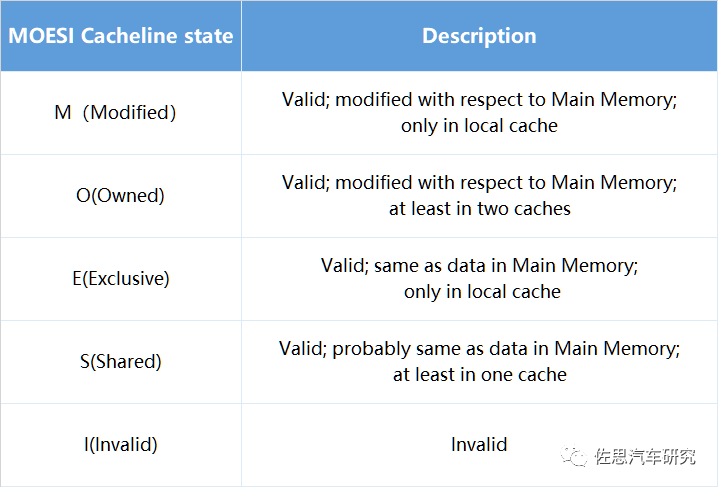
表:cache一致性协议之MESI协议
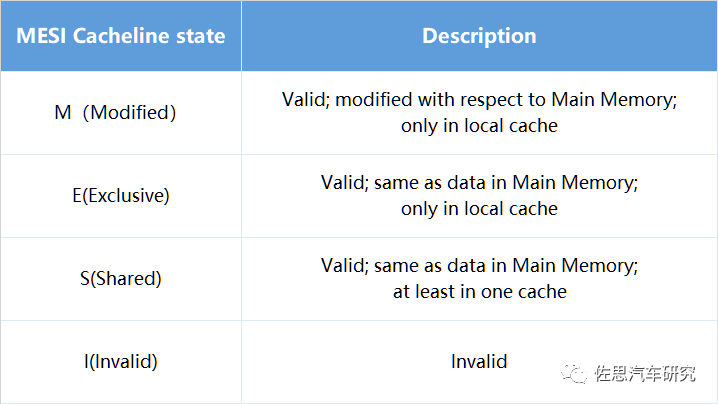
MESI协议的不便之处在于:假设CPUA有个一个M态的cache line,而此时CPU B想获取此cache line,那么总线必须通知CPU A将cache line同步到主存中。在这个过程中,总线与主存的交互会消耗较长的时间,如果可以在不将数据同步回主存的情况,将CPU A的数据通过总线发送给CPU B,将会节省时间,提高效率。 MOESI协议就优化了这一不便之处。MOESI协议允许cache之间共享dirtycache line。Dirty是指cache line相对于主存而言已经发生变化,这样就可以节省与主存交互的时间成本,在cache line不需要写回主存之前,一直在cache之间传输。 MOESI相较于MESI多一个O态,O态代表该cache line与主存中的值不同,至少存在于两个cache中,并由该cache在需要的时刻将cache line刷新到主存中。此外MESI和MOESI的S态有所不同,MESI的S态中的cache line与主存保持一致;而MOESI的S态中的cache line不一定与主存保持一致,可能是共享了dirty cache line,但是没有向主存刷新cache line的义务。
表:cache一致性协议之MOESI协议
目前常采用CHI协议来实现一致性总线上各个组件的通信,该协议就是采用了MOESI来管理相应的cache line 状态。CHI灵活用于设计基于一致性总线的芯片系统,支持构建小型、中型或大型芯片系统。系统包含多个组件,从CPU、GPU、DDR到外设接口,以及互连本身。 CHI协议只定义了网络中不同组件,但是没有规定使用何种方式来连接组件。一致性总线设计者可以根据PPA(Performance/Power/Area)需求灵活定义拓扑结构。拓扑结构包含以下三类:
环形拓扑(Ring)。在环中,每个组件直接连接到其他两个组件,形成一个环状网络结构,所有组件可以在环中相互通信。这种拓扑的缺点是,延迟随着环中组件的数量线性增加。这是因为相关事务只能一直沿着环形网络传输,直到抵达目的地。因此,环形拓扑最适合于中型系统。
网格拓扑(Mesh)。与环相比,网格包含了更多的到达目的地的路径,因此减少了相关事务的访问时间。这在系统中提供了更高的带宽,同时也是以牺牲更多的面积为代价。网状拓扑结构最适合于大规模系统。
交叉连接(Crossbar)。这种拓扑允许每个节点连接到每个可能的节点。这种设计提供了最好的性能,因为每个组件都与需要通信的组件有直接连接。这种拓扑的缺点是连接所有组件的需要很大的资源开销。这是因为每增加一个组件,系统中所需的信号线数量都会显著增加。因此,拓扑最适合于小型系统。
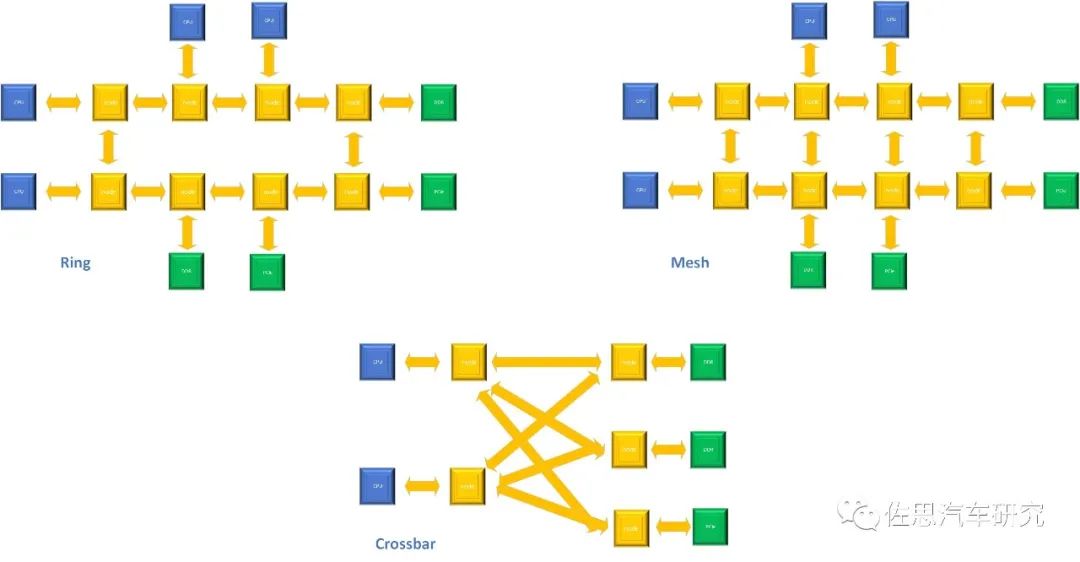
拓扑结构示意图
为了提高CPU存取数据的速率,通常会在一致性总线上加入一级cache,也就是LLC(Last Level Cache)。LLC是一个独占cache,是低于CPUcache的一级cache,用于缓存从总线中经过的cacheline,它增加了芯片上总cache容量。当总线无法从CPU的cache中获取需要的数据时,可以先查询LLC是否含有对应的数据,如果命中,就可以在不访问主存或外设的情况下,为CPU提供数据。这种多级cache结构有效减少了芯片访问主存或外设的次数,为高性能CPU提供了相应数据搬运能力。
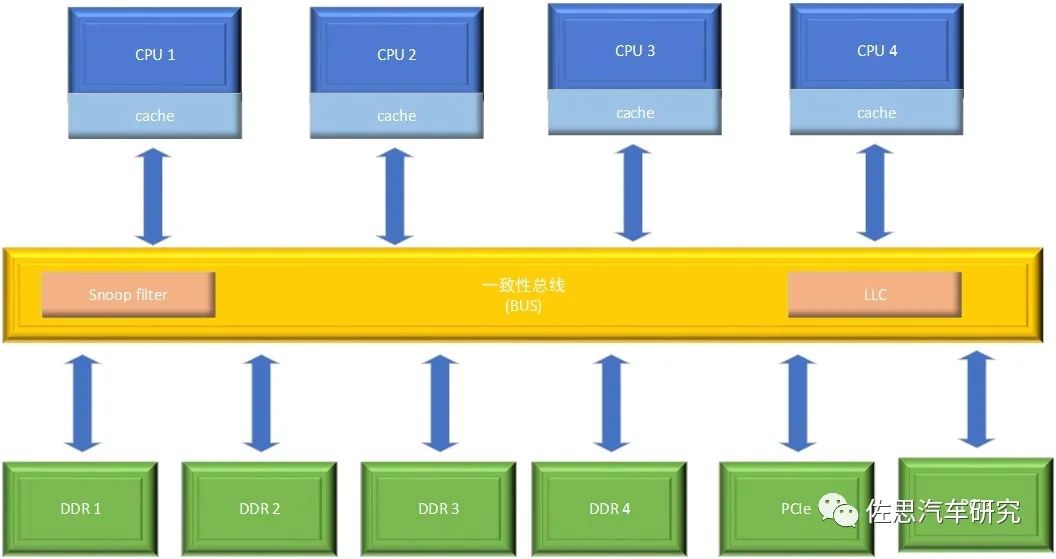
一致性总线示意图 结语 一致性总线的出现有效提升了芯片系统内部数据交流的效率,保证了处理器可以及时获取有效数据,使得高性能处理器可以得到更好的发挥,起到了加速芯片系统运行的作用。随着车载芯片的不断发展,一致性总线会得到更加广泛的应用。
审核编辑 :李倩
-
soc
+关注
关注
40文章
4659浏览量
230607 -
核心技术
+关注
关注
4文章
625浏览量
20538 -
总线
+关注
关注
10文章
3065浏览量
91967 -
芯片系统
+关注
关注
0文章
16浏览量
15986
原文标题:总线一致性:高性能SoC核心技术
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
PCB 热设计必看:SMD 测温元件怎么选才能降低误差、提升一致性

【生产制造】从元器件到成品,尼赛拉一体化设计打造高一致性传感器

是德科技发布全新汽车以太网接收器一致性测试解决方案
是德科技推出全新GDDR7发射端一致性测试解决方案

聚焦一致性:锂电池分选技术的革新者与推动者

比斯特通用分选机四线制测试技术保障电芯性能一致性

以太网一致性测试全解析:保障高性能网络的关键技术
储能电池一致性,已成核心竞争力
比斯特1810B自动分选机实现电池性能一致性的保障设备


电缆组件相位一致性的意义

请教大家一下DP一致性测试问题
直播回顾 | 深度解读CAN总线一致性测试的四大层级与实战方法,虹科技术直播助您破解汽车通信稳定性的关键




评论