 使用多个推理芯片需要仔细规划
使用多个推理芯片需要仔细规划

过去两年,推理芯片业务异常忙碌。有一段时间,似乎每隔一周就有另一家公司推出一种新的更好的解决方案。尽管所有这些创新都很棒,但问题是大多数公司不知道如何利用各种解决方案,因为他们无法判断哪一个比另一个表现更好。由于在这个新市场中没有一套既定的基准,他们要么必须快速掌握推理芯片的速度,要么必须相信各个供应商提供的性能数据。
大多数供应商都提供了某种类型的性能数据,通常是任何让它们看起来不错的基准。一些供应商谈论 TOPS 和 TOPS/Watt 时没有指定型号、批量大小或工艺/电压/温度条件。其他人使用了 ResNet-50 基准,这是一个比大多数人需要的简单得多的模型,因此它在评估推理选项方面的价值值得怀疑。
从早期开始,我们已经走了很长一段路。公司已经慢慢发现,在衡量推理芯片的性能时真正重要的是 1) 高 MAC 利用率,2) 低功耗和 3) 你需要保持一切都很小。
我们知道如何衡量——下一步是什么?
既然我们对如何衡量一个推理芯片相对于另一个的性能有了相当好的了解,公司现在正在询问在同一设计中同时使用多个推理芯片的优点(或缺点)是什么。简单的答案是,使用多个推理芯片,当推理芯片设计正确时,可以实现性能的线性增长。当我们考虑使用多个推理芯片时,高速公路的类比并不遥远。公司想要单车道高速公路还是四车道高速公路的性能?
显然,每家公司都想要一条四向高速公路,所以现在的问题变成了“我们如何在不造成交通和瓶颈的情况下交付这条四车道的高速公路?” 答案取决于选择正确的推理芯片。为了解释,让我们看一个神经网络模型。
神经网络被分解成层。ResNet-50 等层有 50 层,YOLOv3 有超过 100 层,每一层都接受前一层的激活。因此,在第 N 层中,它的输出是进入第 N+1 层的激活。它等待该层进入,计算完成,输出是进入第 n+2 层的激活。这会持续到层的长度,直到你最终得到结果。请记住,此示例的初始输入是图像或模型正在处理的任何数据集。
当多个芯片发挥作用时
现实情况是,如果您的芯片具有一定的性能水平,总会有客户想要两倍或四倍的性能。如果你分析神经网络模型,在某些情况下是可以实现的。您只需要查看如何在两个芯片或四个芯片之间拆分模型。
多年来,这一直是并行处理的一个问题,因为很难弄清楚如何对您正在执行的任何处理进行分区并确保它们全部相加,而不是在性能方面被减去。
与并行处理和通用计算不同,推理芯片的好处是客户通常会提前知道他们是否要使用两个芯片,这样编译器就不必在运行时弄清楚——它是在编译时完成的。使用神经网络模型,一切都是完全可预测的,因此我们可以分析并准确确定如何拆分模型,以及它是否能在两个芯片上运行良好。
为了确保模型可以在两个或更多芯片上运行,重要的是逐层查看激活大小和 MAC 数量。通常发生的情况是,最大的激活发生在最早的层中。这意味着随着层数的增加,激活大小会慢慢下降。
查看 MAC 的数量以及每个周期中完成的 MAC 数量也很重要。在大多数模型中,每个循环中完成的 MAC 数量通常与激活大小相关。这很重要,因为如果您有两个芯片并且想要以最大频率运行,则需要为每个芯片分配相同的工作负载。如果一个芯片完成模型的大部分工作,而另一个芯片只完成模型的一小部分,那么您将受到第一个芯片的吞吐量的限制。
如何在两个芯片之间拆分模型也很重要。您需要查看 MAC 的数量,因为这决定了工作负载的分布。您还必须查看芯片之间传递的内容。在某些时候,您需要在您传递的激活尽可能小的地方对模型进行切片,以便所需的通信带宽量和传输延迟最小。如果在激活非常大的点对模型进行切片,激活的传输可能会成为限制双芯片解决方案性能的瓶颈。
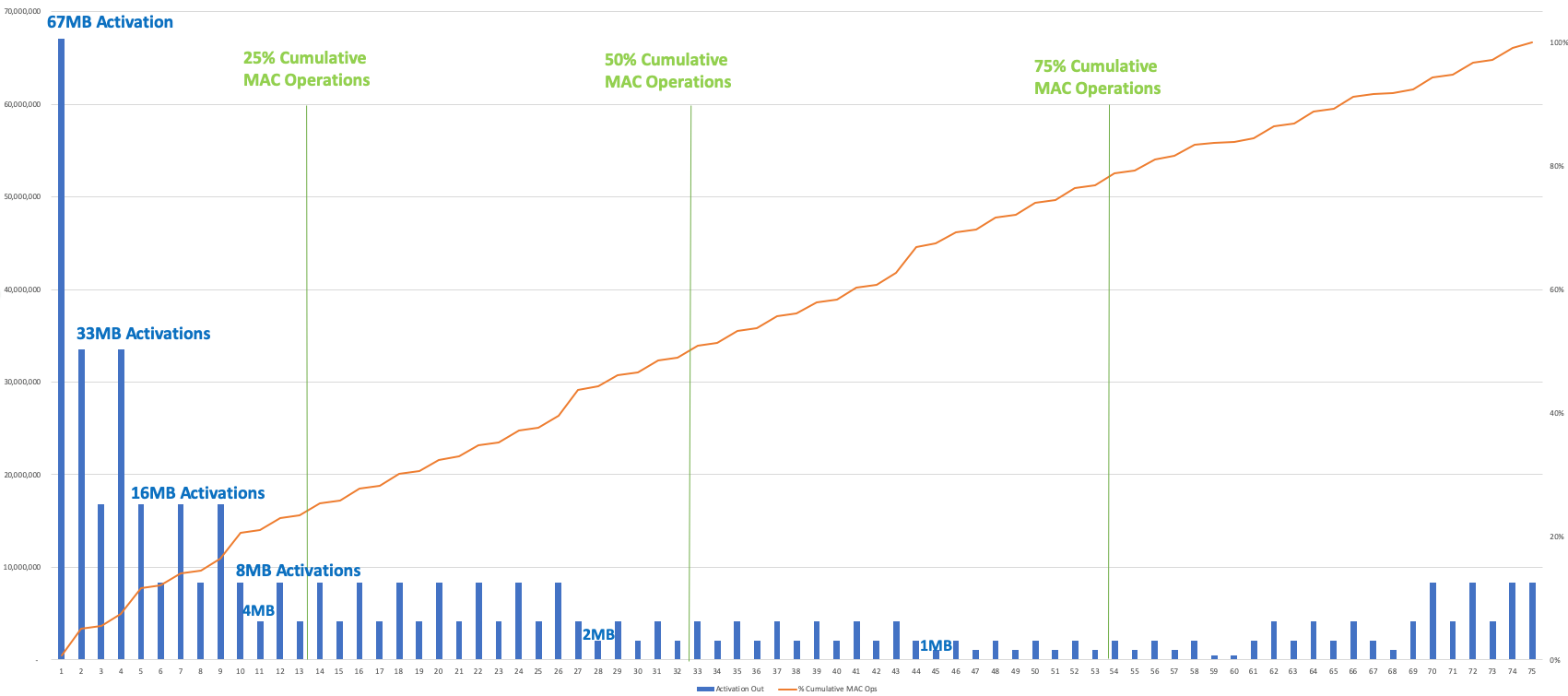
下图显示了 YOLOv3、Winograd、2 百万像素图像的激活输出大小和累积的 Mac 操作逐层(绘制了卷积层)。为了平衡两个芯片之间的工作负载,该模型将减少大约 50% 的累积 MAC 操作——此时从一个芯片传递到另一个芯片的激活为 1MB 或 2MB。要在 4 个筹码之间进行拆分,削减率约为 25%、50% 和 75%;请注意,激活大小在开始时最大,因此 25% 的切点有 4 或 8MB 的激活要通过。
单击此处查看大图
YOLOv3/Winograd/2Mpixel 图像的激活输出大小(蓝条)和逐层累积 MAC 操作(红线),显示工作负载如何在多个芯片之间分配(图片:Flex Logix)
性能工具
幸运的是,现在可以使用性能工具来确保高吞吐量。事实上,模拟单个芯片性能的同一工具可以推广到模拟两个芯片的性能。虽然任何给定层的性能完全相同,但问题是数据传输如何影响性能。建模工具需要考虑这一点,因为如果所需的带宽不够,该带宽将限制吞吐量。
如果您正在做四个芯片,您将需要更大的带宽,因为模型第一季度的激活往往大于模型后期的激活。因此,您投资的通信资源量将允许您使用流水线连接的大量芯片,但这将是所有芯片都必须承担的间接成本,即使它们是独立芯片。
结论
使用多个推理芯片可以显着提高性能,但前提是如上所述正确设计神经网络。如果我们回顾一下高速公路的类比,有很多机会通过使用错误的芯片和错误的神经网络模型来建立交通。如果你从正确的芯片开始,你就走在了正确的轨道上。请记住,最重要的是吞吐量,而不是 TOPS 或 Res-Net50 基准。然后,一旦您选择了正确的推理芯片,您就可以设计一个同样强大的神经网络模型,为您的应用需求提供最大的性能。
— Geoff Tate 是 Flex Logix 的首席执行官
、审核编辑 黄昊宇
-
芯片
+关注
关注
463文章
54409浏览量
469119 -
Mac
+关注
关注
0文章
1131浏览量
55541
发布评论请先 登录
堪称史上最强推理芯片!英伟达发布 Rubin CPX,实现50倍ROI

大模型推理服务的弹性部署与GPU调度方案
把大模型“刻进”芯片,AI芯片推理速度17000 tokens/秒

AI推理芯片需求爆发,OpenAI欲寻求新合作伙伴
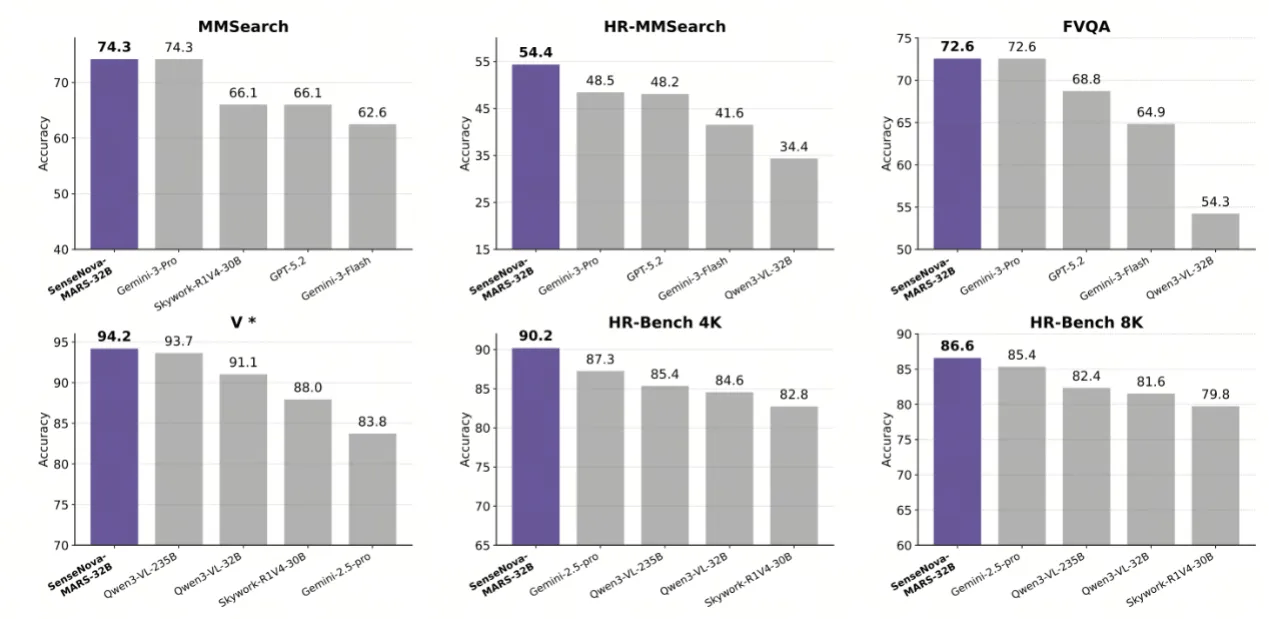
商汤开源SenseNova-MARS:突破多模态搜索推理天花板
曦望发布新一代推理GPU芯片,单位Token推理成本降低90%
今日看点:消息称 AMD、高通考虑导入 SOCAMM 内存;曦望发布新一代推理GPU芯片启望S3
LLM推理模型是如何推理的?

欧洲之光!5nm,3200 TFLOPS AI推理芯片即将量产

使用NVIDIA Grove简化Kubernetes上的复杂AI推理
AI推理芯片赛道猛将,200亿市值AI芯片企业赴港IPO



评论