 使用NVIDIA Grove简化Kubernetes上的复杂AI推理
使用NVIDIA Grove简化Kubernetes上的复杂AI推理

过去几年,AI 推理的部署已经从单一模型、单一 Pod 演变为复杂的多组件系统。如今,一个模型部署可能包含多个不同的组件——预填充 (prefill)、解码 (decode)、视觉编码器 (vision encoders)、键值 (KV) 路由器等。此外,完整的代理式管道正在兴起,其中多个模型实例协同工作,执行推理、检索或多模态任务。
这种转变将实例扩展和编排的问题从“运行 N 个 Pod 副本”转变为“将一整个组件协调为一个逻辑系统”。管理此类系统需要同步扩展和调度合适的 Pod,了解每个组件不同的配置和资源需求,按特定的顺序启动,并根据网络拓扑结构将它们部署在集群中。最终目标是编排整个系统,并基于组件在整个系统的依赖关系进行扩展,而不是一次扩展一个 Pod。
为了应对这些挑战,我们宣布推出NVIDIA Grove,一个在 Kubernetes 集群上运行现代机器学习推理工作负载的 Kubernetes API。Grove 现已作为模块化组件集成至NVIDIA Dynamo,它完全开源,可在ai-dynamo/groveGitHub 库使用。
NVIDIA Grove如何整体性编排推理负载
Grove 能够将多节点推理部署从单个副本扩展到数据中心规模,支持数万个 GPU。Grove 可将 Kubernetes 中的整个推理服务系统(例如预填充、解码、路由或任何其他组件)描述为单个自定义资源 (Custom Resource, CR)。
根据该单一配置文件,平台可协调层级化调度、拓扑感知的放置、多级自动扩缩容以及明确的启动顺序。您可以精准控制系统的行为方式,而无需将脚本、YAML 文件或自定义控制器拼接在一起。
Grove 最初是为了解决多节点 PD 分离推理系统的编排问题而开发的,它具有足够的灵活性,可以自然地映射到任何现实世界的推理架构,从传统的单节点聚合推理到具有多个模型的代理式管道。Grove 使开发者能够以简洁、声明式且与框架无关的方式定义复杂的 AI 堆栈。
多节点PD分离服务的前提条件详情如下。
多级自动扩缩容以应对相互依赖的组件
现代推理系统需要在多个层面上进行自动扩缩容:单个组件(应对流量高峰的预填充工作节点)、相关组件组(预填充主节点及其工作节点)以及用于扩展整体容量的整体服务副本。这些层级相互依赖:扩展预填充工作节点可能需要更多的解码能力,而新的服务副本需要合理的组件比例。传统的 Pod 级自动扩缩容无法处理这些相互依赖关系。
覆盖恢复与滚动更新的系统级生命周期管理
恢复和更新必须以完整的服务实例为操作对象,而非单个Kubernetes Pod。当预填充工作节点发生故障并重启后,需要正确地重新连接到其主节点,而滚动更新必须保持网络拓扑来维持低延迟。平台必须将多组件系统视为单一操作单元,同时优化其性能和可用性。
灵活的层级化组调度
AI 工作负载调度器应支持灵活的组调度机制,突破传统的全有或全无的放置方式。PD 分离服务带来了新的挑战:推理系统需要保证关键组件组合(例如至少一个预填充和一个解码工作节点),同时允许每种组件类型独立扩展。挑战在于,预填充和解码组件应根据工作负载模式按照不同的比例进行扩展。传统的组调度将所有组件强制绑定到必须同步扩展的组中,阻碍了这种独立扩展。系统需要制定策略,确保强制执行最小可行组件组合的同时,实现灵活的扩展。
拓扑感知调度
组件的布局会影响性能。在如NVIDIA 高性能计算平台这样的系统上,将相关的预填充 Pod 和解码 Pod 调度至同一NVIDIA NVLink域内,可优化 KV 缓存的传输延迟。调度器需要理解物理网络拓扑,在将相关组件就近放置的同时,通过分散副本以提高系统的可用性。
角色感知的编排和明确的启动顺序
组件具有不同的职责、配置和启动要求。例如,预填充和解码主节点需要执行独立的启动逻辑,且工作节点在主节点准备就绪之前无法启动。为实现可靠的系统初始化,平台需要针对角色进行特定配置和依赖关系管理。
综上所述,整体情况可概括为:推理团队需要一种简单且声明式的方法,来描述系统的实际运行状态(多角色、多节点、明确的多级依赖关系),并使系统能够根据该描述进行调度、扩展、恢复和更新。
Grove原语
高性能推理框架使用 Grove 层级化 API 来表达角色特定的逻辑和多级扩展,从而在跨多种集群环境中实现一致且优化的部署。Grove 通过在其 Workload API 中使用三种层次化的自定义资源编排多组件 AI 工作负载,来实现这一点。
在图 1 中,PodClique A 代表前端组件,B 和 C 代表预填充主节点和预填充工作节点,D 和 E 代表解码主节点和解码工作节点。
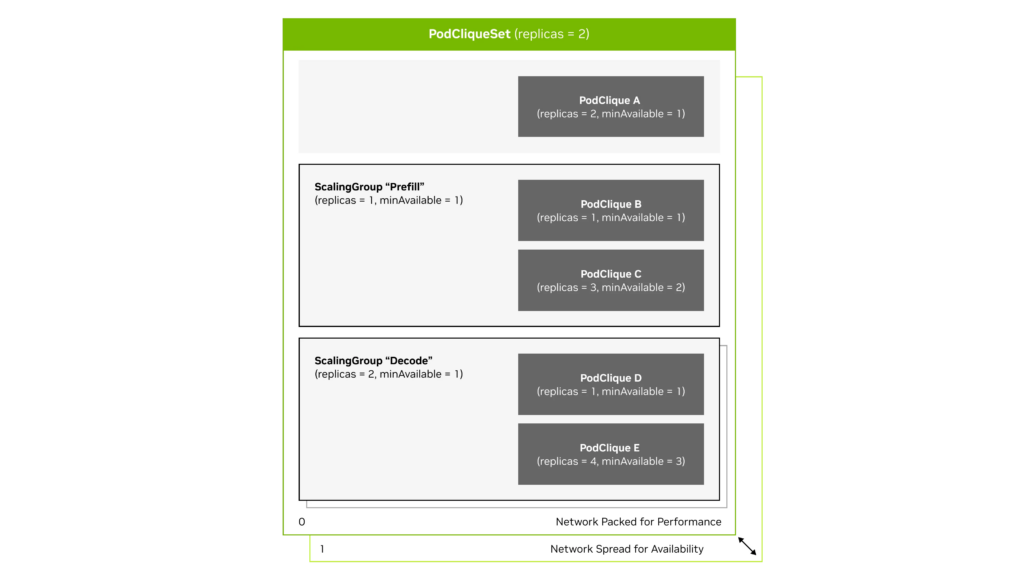
图 1. NVIDIA Grove 的关键组件包括PodClique、 ScalingGroup和 PodCliqueSet,以及它们如何协同工作
PodCliques代表具有特定角色的Kubernetes Pod组,例如预填充主节点或工作节点、解码主节点或工作节点,以及前端服务,每个组都有独立的配置和扩展逻辑。
PodCliqueScalingGroups将必须协同扩展的紧密耦合的 PodCliques 进行打包,例如,预填充主节点和预填充工作节点一起代表一个模型实例。
PodCliqueSets定义完整的多组件工作负载,指定启动顺序、扩展策略及组调度约束,以确保所有组件或者一起启动,或者共同失败。当需要扩展以增加容量时,Grove 会创建整个 PodGangSet 的完整副本,并定义分布约束,将这些副本分布在集群中以实现高可用性,同时保持每个副本的组件在网络拓扑上紧密封装,以优化性能。
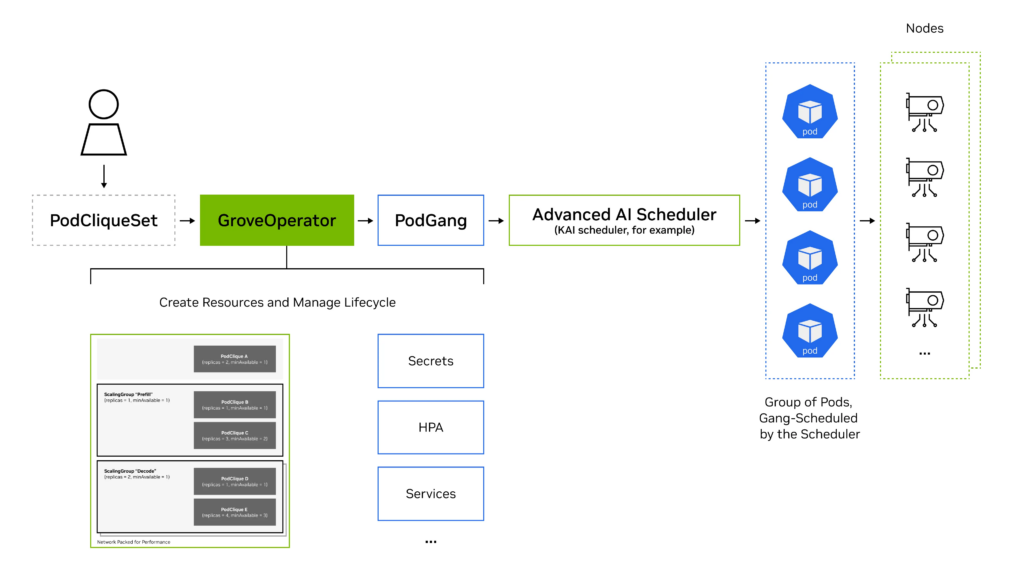
图 2. Grove 工作流
支持 Grove 的 Kubernetes 集群将整合两个关键组件:Grove 操作器和能够识别 PodGang 资源的调度器,例如KAI Scheduler,这是NVIDIA Run:ai 平台的一个开源子组件。
当创建 PodCliqueSet 资源时,Grove operator 会验证配置清单,并自动生成实现所需的底层 Kubernetes 对象。这包括组成的 PodCliques、PodCliqueScalingGroups,以及相关的 Pod、服务 (Services)、密钥 (Secrets) 和自动扩缩容策略。在此过程中,Grove 还会创建 PodGang 资源,这是 Scheduler API 的一部分,将工作负载定义转换为集群调度器的具体调度约束。
每个 PodGang 封装了其工作负载的详细要求,包括最低副本保证、优化组件间带宽的网络拓扑偏好,以及保持可用性的扩散约束。这些共同确保了拓扑感知的放置和集群中资源的高效利用。
Scheduler 持续监测 PodGang 资源,并应用组调度逻辑,确保所有必要组件在资源可用前共同调度或暂缓调度。调度决策基于GPU 拓扑感知和集群局部性优化生成。
最终结果是多组件 AI 系统的协调部署,其中预填充服务、解码工作节点和路由组件按正确顺序启动,紧密放置在网络拓扑上以提高性能,并作为一个整体共同自愈。这防止了资源碎片化,避免了部分部署,并能够大规模稳定高效地运行复杂的模型服务管道。
如何使用Dynamo快速上手Grove
本节将分享如何使用 Dynamo 和 Grove 通过 KV 路由部署组件部署 PD 分离服务架构。该设置使用Qwen3 0.6B模型,并演示了 Grove 通过独立的预填充和解码工作节点管理分布式推理工作负载的能力。
注意:这是一个基础示例,旨在帮助您理解核心概念。有关更复杂的部署,请参考ai-dynamo/groveGitHub 库。
先决条件
首先,确保您的 Kubernetes 集群中准备好以下组件:
支持 GPU 的 Kubernetes 集群
已配置 kubectl 以访问您的集群
安装 Helm CLI
Hugging Face token密钥(称为hf-token-secret),可以使用以下命令创建:
kubectl create secret generic hf-token-secret \ --from-literal=HF_TOKEN=
注意:在代码中,将
步骤1:创建命名空间
kubectl create namespace vllm-v1-disagg-router
步骤2:使用Grove安装Dynamo CRD和Dynamo Operator
# 1. Set environment
export NAMESPACE=vllm-v1-disagg-router export RELEASE_VERSION=0.5.1
# 2. Install CRDs
helm fetchhttps://helm.ngc.nvidia.com/nvidia/ai-dynamo/charts/dynamo-crds-${RELEASE_VERSION}.tgz
helm install dynamo-crds dynamo-crds-${RELEASE_VERSION}.tgz --namespace default
# 3. Install Dynamo Operator + Grove
helm fetchhttps://helm.ngc.nvidia.com/nvidia/ai-dynamo/charts/dynamo-platform-${RELEASE_VERSION}.tgz
helm install dynamo-platform dynamo-platform-${RELEASE_VERSION}.tgz --namespace ${NAMESPACE} --create-namespace --set "grove.enabled=true"
步骤3:验证Grove安装
kubectl get crd | grep grove
预期输出:
podcliques.grove.io podcliquescalinggroups.grove.io podcliquesets.grove.io podgangs.scheduler.grove.io podgangsets.grove.io
步骤4:创建DynamoGraphDeployment配置
创建一个DynamoGraphDeployment清单,定义PD分离服务架构,包含一个前端、两个解码工作节点和一个预填充工作节点:
apiVersion: nvidia.com/v1alpha1 kind: DynamoGraphDeployment metadata: name: dynamo-grove spec: services: Frontend: dynamoNamespace: vllm-v1-disagg-router componentType: frontend replicas: 1 extraPodSpec: mainContainer: image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.5.1 envs: - name: DYN_ROUTER_MODE value: kv VllmDecodeWorker: dynamoNamespace: vllm-v1-disagg-router envFromSecret: hf-token-secret componentType: worker replicas: 2 resources: limits: gpu: "1" extraPodSpec: mainContainer: image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.5.1 workingDir: /workspace/components/backends/vllm command: - python3 - -m - dynamo.vllm args: - --model - Qwen/Qwen3-0.6B VllmPrefillWorker: dynamoNamespace: vllm-v1-disagg-router envFromSecret: hf-token-secret componentType: worker replicas: 1 resources: limits: gpu: "1" extraPodSpec: mainContainer: image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.5.1 workingDir: /workspace/components/backends/vllm command: - python3 - -m - dynamo.vllm args: - --model - Qwen/Qwen3-0.6B - --is-prefill-worker
步骤5:部署配置
kubectl apply -f dynamo-grove.yaml
步骤6:验证部署
验证operator和Grove Pod已创建:
kubectl get pods -n ${NAMESPACE}
预期输出:
NAME READY STATUS RESTARTS AGE dynamo-grove-0-frontend-w2xxl 1/1 Running 0 10m dynamo-grove-0-vllmdecodeworker-57ghl 1/1 Running 0 10m dynamo-grove-0-vllmdecodeworker-drgv4 1/1 Running 0 10m dynamo-grove-0-vllmprefillworker-27hhn 1/1 Running 0 10m dynamo-platform-dynamo-operator-controller-manager-7774744kckrr 2/2 Running 0 10m dynamo-platform-etcd-0 1/1 Running 0 10m dynamo-platform-nats-0 2/2 Running 0 10m
步骤7:测试部署
首先,端口转发前端:
kubectl port-forward svc/dynamo-grove-frontend 8000:8000 -n ${NAMESPACE}
然后测试端点:
curlhttp://localhost:8000/v1/models
或者可以检查PodClique资源,以查看Grove如何将Pod分组在一起,包括副本计数:
kubectl get podclique dynamo-grove-0-vllmdecodeworker -n vllm-v1-disagg-router -o yaml
准备好了解更多了吗?
NVIDIA Grove完全开源,可在ai-dynamo/groveGitHub 库中获取。我们邀请您在自己的 Kubernetes 环境中使用Dynamo的独立组件 Grove,或与高性能 AI 推理引擎一起使用。
探索Grove 部署指南并在GitHub或Discord中提问。要了解 Grove 的实际应用,请访问亚特兰大KubeCon 2025 上的 NVIDIA 展位。我们欢迎社区提供贡献、拉取请求并反馈意见。
致谢
感谢所有参与NVIDIA Grove项目开发的开源开发者、测试人员和社区成员的宝贵贡献,特别感谢SAP (Madhav Bhargava、Saketh Kalaga、Frank Heine)的杰出贡献和支持。开源因协作而蓬勃发展——感谢您成为Grove的一员。
-
NVIDIA
+关注
关注
14文章
5687浏览量
110113 -
AI
+关注
关注
91文章
41101浏览量
302579 -
机器学习
+关注
关注
67文章
8564浏览量
137217 -
kubernetes
+关注
关注
0文章
275浏览量
9534
原文标题:使用 NVIDIA Grove 简化 Kubernetes 上的复杂 AI 推理
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Kubernetes的Device Plugin设计解读
NVIDIA 在首个AI推理基准测试中大放异彩
NVIDIA在最新AI推理基准测试中大获成功
NVIDIA宣布其AI推理平台的重大更新
NVIDIA Triton推理服务器简化人工智能推理
使用NVIDIA GPU和SmartNIC的边缘AI
使用NVIDIA Triton推理服务器简化边缘AI模型部署
蚂蚁链AIoT团队与NVIDIA合作加速AI推理
TinyAnimal:Grove Vision AI上的动物识别实践

英伟达推出AI模型推理服务NVIDIA NIM
英伟达推出全新NVIDIA AI Foundry服务和NVIDIA NIM推理微服务
NVIDIA助力丽蟾科技打造AI训练与推理加速解决方案


NVIDIA 推出开放推理 AI 模型系列,助力开发者和企业构建代理式 AI 平台




评论