 RapidIO针对低延迟处理器连接进行优化
RapidIO针对低延迟处理器连接进行优化

随着摩尔定律继续推动处理器的性能和集成,对更高速互连的需求也在持续增长。今天的互连通常运动速度从 10 Gbps 到 80 Gbps 不等,并且具有达到每秒数百千兆位的路线图。
在争取越来越快的互连速度的竞赛中,一些话题很少被讨论,包括支持的事务类型、通信延迟和开销,以及可以轻松支持的拓扑类型。设计人员倾向于认为所有互连都是平等的,并且具有仅基于峰值带宽的品质因数。
现实完全不同。正如针对通用、信号处理、图形和通信应用优化的不同形式的处理器一样,互连也针对不同的连接问题进行设计和优化。互连通常可以解决其设计的问题,并且可以投入使用以解决其他应用程序,但在这些应用程序中效率会降低。
RapidIO 设计目标
在这种情况下查看 RapidIO 是有启发性的。RapidIO 旨在用作低延迟处理器互连,用于需要高可靠性、低延迟和确定性操作的嵌入式系统。它旨在将来自不同制造商的不同类型的处理器连接到一个系统中。正因为如此,RapidIO 已在无线基础设施设备中得到广泛应用,其中需要将通用、数字信号、FPGA 和通信处理器结合在一个紧密耦合的系统中,具有低延迟和高可靠性。
RapidIO 的使用模型需要提供对内存到内存事务的支持,包括原子读取-修改-写入操作。为满足这些要求,RapidIO 提供了无需软件干预即可实现的远程直接内存访问 (RDMA)、消息传递和信令结构。例如,在 RapidIO 系统中,处理器可以发出加载或存储事务,或者集成的 DMA 引擎可以在两个内存位置之间传输数据。这些操作在其源或目标地址所在的 RapidIO 结构中执行,并且通常无需任何软件干预即可发生。从处理器看来,它们与普通的内存事务没有什么不同。
RapidIO 还旨在支持点对点交易。假设系统中有多个主机或主处理器,并且这些处理器需要通过共享内存、中断和消息相互通信。在 RapidIO 网络中可以配置多个处理器(最高 16K),每个处理器都有自己的完整地址空间。
RapidIO 还在交换机和端点的功能之间提供了清晰的分界线。RapidIO 交换机仅根据明确的源/目标地址对和明确的优先级做出切换决策。这允许 RapidIO 端点添加新的事务类型,而无需更改或增强交换设备。
比较互连
随着越来越多的系统被集成到单个硅片上,PCI Express (PCIe) 和以太网正在集成到片上系统 (SoC) 中。然而,这种集成并没有改变这些互连提供的事务的性质(参见图 1)。
图 1: RapidIO、PCI Express 和以太网为连接处理器、I/O 和系统提供了不同的选项。
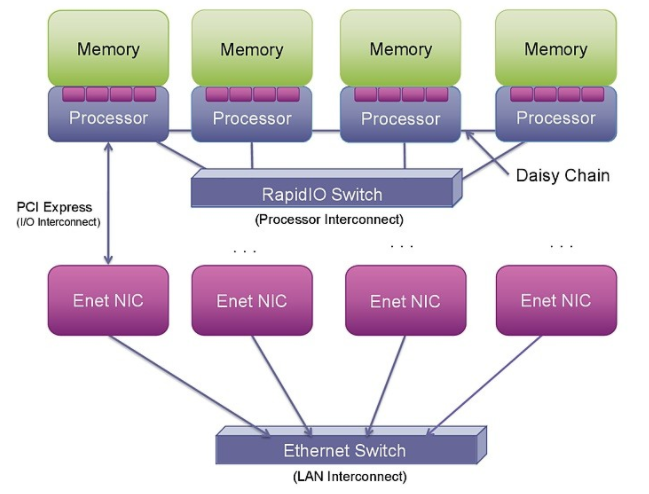
PCIe 本身并不支持点对点处理器连接。使用 PCIe 进行这种连接可能非常复杂,因为它被设计为外围组件互连(因此是 PCI)。它旨在将外围设备(通常是 I/O 和图形芯片等从属设备)连接到主主机处理器。它不是作为处理器互连设计的,而是作为 PCI 总线的串行版本。从 PCI 构建多处理器互连需要超越基本 PCI 规范的步骤,以创建在多个主机或根处理器之间映射地址空间和设备标识符的新机制。迄今为止,执行此操作的提议机制——高级交换 (AS)、非透明桥接 (NTB) 或多根 I/O 虚拟化 (MR-IOV)——都没有在商业上取得成功。
对于有明确的单一主机设备且其他处理器和加速器作为从设备运行的系统,PCIe 是连接的不错选择。然而,为了在更复杂的系统中将许多处理器连接在一起,PCIe 在拓扑结构和对等连接的支持方面存在很大限制。
许多开发人员正在寻求利用以太网作为连接系统中处理器的解决方案。在过去的 35 年中,以太网取得了长足的发展。与计算机处理速度的提高类似,其峰值带宽也在稳步增长。目前可用的以太网网络接口控制器 (NIC) 卡可以支持 40 Gbps 运行,通过四对 SERDES 和 10 Gbps 信号传输。这样的 NIC 卡本身包含重要的处理,能够以这些速度传输和接收数据包。
从解决方案到紧密耦合的处理器间通信,通过 NIC 发送和接收以太网数据包还有很长的路要走。与 PCIe 和以太网事务处理相关的开销(两个堆栈都必须在 NIC 中遍历),加上相关的 SERDES 功能和以太网媒体访问协议和交换增加了延迟、复杂性和更高的功耗以及系统成本可以使用更直接的连接方法(见表 1)。
表 1:以太网和 RapidIO 的比较显示了更直接连接方法的优势。
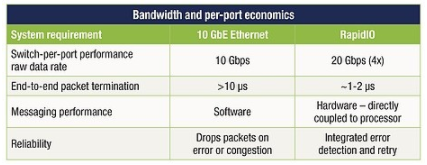
将以太网用作集成嵌入式处理器互连需要对以太网媒体访问控制器 (MAC) 以及以太网交换机设备本身进行显着的事务加速和增强。即使有了这些增强,RDMA 操作也应该仅限于大块交易,以分摊使用以太网的开销。
已部署用于解决此问题的标准包括来自 Internet 工程任务组的 iWARP RDMA 协议和基于融合以太网的 RDMA (RoCE)。iWARP 和 RoCE 通常都是通过加速协处理器实现的。尽管有这种加速,但仍必须仔细管理 RDMA 事务以减少通信开销。原因是尽管以太网提供了高带宽,尤其是在 10 GbE 和 40 GbE 实施中,但它也具有通常以微秒为单位测量的高事务延迟。
当前的 RapidIO 应用程序
多年来,RapidIO 的价值主张已在嵌入式市场中得到广泛认可。同样的价值主张现在可以扩展到更主流的数据处理市场,这些市场正在演变为需要通信网络长期以来需要的许多相同的系统属性。
其中使用 RapidIO 的一种众所周知的应用是无线基站。该应用程序结合了多种形式的处理(DSP、通信和控制),必须在很短的时间内完成。处理设备之间的通信应尽可能快速和确定,以确保实现实时约束。
例如,在 4G 长期演进 (LTE) 无线网络中,每 10 毫秒发送一次帧。这些帧包含多个并发移动会话的数据,分布在多个子载波上,由多个 DSP 设备支持。DSP 和通用处理设备之间的通信必须具有确定性和低延迟,以确保每 10 毫秒就有一个新帧准备好传输。同时,接收路径必须支持来自连接到网络的移动设备的数据。除了这种复杂性之外,系统还必须实时跟踪移动设备的位置并管理设备的信号功率。
RapidIO 应用的另一个例子是半导体晶圆加工。与无线基础设施应用类似,半导体晶圆加工具有实时限制,包括传感器、处理和执行器的控制回路。前沿系统通常有数百个传感器收集信息,传感器数据由数十到数百个处理节点处理。处理节点生成的命令发送到执行器和交流和直流电机,以重新定位晶片和晶片成像子系统。这一切都是在频率高达 100 kHz 或 10 微秒的循环控制循环中执行的。像这样的系统受益于设备之间可能的最低延迟通信。
高性能计算的未来
虚拟化、基于 ARM 的服务器和高度集成的 SoC 设备的引入正在为下一阶段的高性能计算发展铺平道路。这种演变正朝着更紧密耦合的处理器集群发展,这些集群代表为托管数百或数千台虚拟机而构建的处理场。这些处理器集群将由多达数千个通过高性能、低延迟处理器互连连接的多核 SoC 设备组成。这种互连的效率越高,系统的性能和经济性就越好。
PCIe 和 10 GbE 等技术不会很快消失,但它们不会成为这些未来紧密耦合计算系统的基础。PCIe 不是一种结构,只能支持少量处理器和/或外围设备的连接。它可以简单地充当到结构网关设备的桥梁。虽然 10 GbE 可用作结构,但它具有重要的硬件和软件协议处理要求。其广泛可变的帧大小(巨型帧为 46 B 到 9,000 B)推动了对快速处理逻辑的需求,以支持多个小数据包和大型内存缓冲区以支持端点和交换机中的大数据包,从而提高了芯片成本。使用 PCIe 或 10 GbE 将限制可用的拓扑和连接,或者增加系统的成本和开销。
实施集成的服务器、存储和网络系统为 OEM 提供了创新的机会。该创新的一个关键组成部分将是内部系统连接。RapidIO 是一项成熟的、经过充分验证的技术,具有在该市场取得成功所需的属性。与无线基础设施的情况一样,RapidIO 从早期创新发展成为事实上的基站互连标准,RapidIO 在服务器、存储和高性能计算方面的最大挑战将是跨越当今创新者和早期采用者市场的鸿沟大众市场的扩散。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
20330浏览量
254871 -
soc
+关注
关注
40文章
4623浏览量
230163 -
服务器
+关注
关注
14文章
10354浏览量
91743
发布评论请先 登录
IDT Tsi620:RapidIO开关与RapidIO - PCI桥的融合之作
IDT Tsi564A™ Serial RapidIO Switch:高性能嵌入式通信的理想之选
18 - Port, 48 - Lane, 240Gbps, Gen2 RapidIO Switch——CPS - 1848深度解析
深入解析CPS - 1432:一款强大的RapidIO交换机
LT1528:3A低 dropout 稳压器,为微处理器应用量身打造
瑞芯微SOC智能视觉AI处理器
如何对蜂鸟e203内核乘除法器进行优化
【技术讨论】智能戒指手势交互:如何优化PCBA成本与实现<20ms低延迟?
DRA821U-Q1/DRA821U处理器技术文档总结
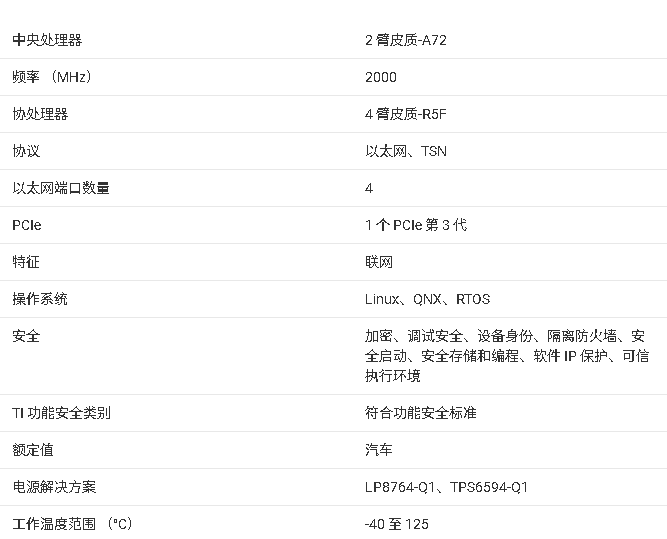
DRA821U处理器技术文档总结
AMD 推出 EPYC™ 嵌入式 4005 处理器,助力低时延边缘应用

Texas Instruments DRA821x Jacinto™ 64位处理器技术解析
有哪些方法可以降低分布式光伏集群通信网络中的延迟?




评论