 六个Python进阶用法介绍
六个Python进阶用法介绍

1 列表生成式和生成器
from numpy import random
a = random.random(10000)
lst = []
for i in a:
lst.append(i * i) # 不推荐做法
lst = [i * i for i in a] # 使用列表生成式
gen = (i * i for i in a) # 生成器更节省内存
2 字典推导式创建子集
a = {'apple': 5.6, 'orange': 4.7, 'banana': 2.8}
da = {key: value for key, value in a.items() if value > 4.0}
print(da) # {'apple': 5.6, 'orange': 4.7}
3 Key使用itemgetter多字段排序
from operator import itemgetter
a = [{'date': '2019-12-15', 'weather': 'cloud'},
{'date': '2019-12-13', 'weather': 'sunny'},
{'date': '2019-12-14', 'weather': 'cloud'}]
a.sort(key=itemgetter('weather', 'date'))
print(a)
# [{'date': '2019-12-14', 'weather': 'cloud'}, {'date': '2019-12-15', 'weather': 'cloud'}, {'date': '2019-12-13', 'weather': 'sunny'}]
4 Key使用itemgetter分组
from operator import itemgetter
from itertools import groupby
a.sort(key=itemgetter('weather', 'date')) # 必须先排序再分组
for k, items in groupby(a, key=itemgetter('weather')):
print(k)
for i in items:
print(i)
5 sum类聚合函数与生成器
Python中的聚合类函数sum,min,max第一个参数是iterable类型,一般使用方法如下:
a = [4,2,5,1]
sum([i+1for i in a]) # 16
使用列表生成式[i+1 for i in a]创建一个长度与a一样的临时列表,这步完成后,再做sum聚合。
试想如果你的数组a长度是百万级,再创建一个这样的临时列表就很不划算,最好是一边算一边聚合,稍改动为如下:
a = [4,2,5,1]
sum(i+1for i in a) # 16
此时i+1 for i in a是(i+1 for i in a)的简写,得到一个生成器(generator)对象,如下所示:
In [8]:(i+1for i in a)
OUT [8]: at 0x000002AC7FFA8CF0>
生成器每迭代一步吐出(yield)一个元素并计算和聚合后,进入下一次迭代,直到终点。
6 ChainMap逻辑上合并多个字典
dic1 = {'x': 1, 'y': 2 }
dic2 = {'y': 3, 'z': 4 }
merged = {**dic1, **dic2} # {'x': 1, 'y': 3, 'z': 4}
修改merged['x']=10,dic1中的x值不变
ChainMap只在逻辑上合并,在内部创建了一个容纳这些字典的列表。
from collections import ChainMap
merged = ChainMap(dic1,dic2)
print(merged)
# ChainMap({'x': 1, 'y': 2}, {'y': 3, 'z': 4})
使用ChainMap合并字典,修改merged['x']=10,dic1中的x值审核编辑:汤梓红
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
内存
+关注
关注
9文章
3234浏览量
76512 -
生成器
+关注
关注
7文章
322浏览量
22803 -
python
+关注
关注
58文章
4885浏览量
90307
发布评论请先 登录
相关推荐
热点推荐
人工智能-Python深度学习进阶与应用技术:工程师高培解读
深度学习进阶的技术路线图,来分析解读一下从基础原理到前沿应用的多个关键节点。一、从基础到进阶:构建深度学习的完整认知深度学习的起点,是对神经网络基本结构的理解。B

浅谈Kubernetes的六个核心概念
运维工程师在学习 Kubernetes 时,往往会在某些核心概念上反复卡住。这些概念不是孤立的知识点,而是相互关联、层层递进的体系。理解这些概念的关键在于动手实践,而非仅仅阅读文档。
[VirtualLab] 使用Python运行VirtualLab Fusion光学仿真
摘要
VirtualLab Fusion允许Python外部访问其建模技术、求解器和结果。这个用例介绍了一种使用路径变量和Visual Studio代码将Python连接到VirtualLab
发表于 03-31 09:39
矢量网络分析仪VNA选型的六个核心参数
和工程妥协,才是选型的关键。 本文将避开空泛的介绍,直接切入六个最核心的参数:频率范围、动态范围、输出功率、端口数、迹线噪声和扫描时间。我们将探讨每个参数如何在实际测试场景中发挥作用,以及它们之间的相互制约关系,

六轴驱动,如何一步到位?TMCM-6214 的多轴控制!
多轴运动控制,听起来就让人头大:布线像蜘蛛网、编程像天书、控制柜挤得像沙丁鱼罐头。每增加一个轴,线缆多一堆,代码量蹭蹭涨,空间还得精打细算。一个模块搞定六个轴有没有一个模块能把

C语言函数指针的六个高级的应用场景
函数指针是一种非常强大的编程工具,它可以让我们以更加灵活的方式编写程序。在本文中,我们将介绍 6 个函数指针的高级应用场景,并贴出相应的代码案例和解释。
回调函数
回调函数是指在某个事件发生时被
发表于 01-04 12:25
ETAS INCA软件的五个实用进阶功能
在上一篇文章中我们介绍了INCA软件如何赋能高效的ECU开发及新能源挑战,本篇内容将继续深入探讨INCA的五个实用进阶功能。

C语言的printf基本用法介绍
个小数。f 是 float 的简写。
除了这些,printf 支持更加复杂和优美的输出格式,考虑到读者的基础暂时不够,我们将在《C语言数据输出大汇总以及轻量进阶》一节中展开讲解。
我们把代码补充完整
发表于 11-12 07:04
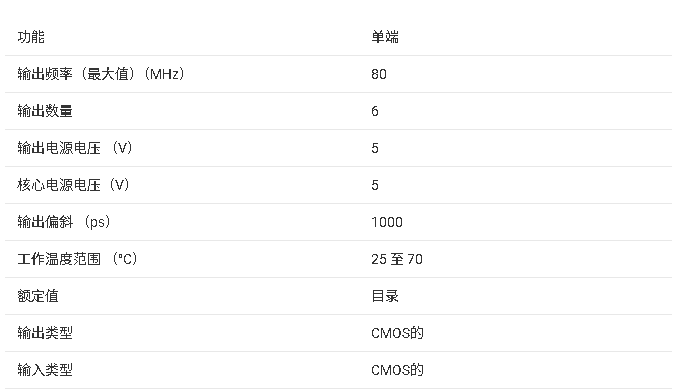
CDC204 3.3V六路反相器/时钟驱动器技术文档总结
CDC204 包含六个独立的逆变器。该器件执行布尔函数 Y = A\。它专为开关输出之间需要低偏斜的应用而设计。
CDC204 的特点是从 T ~一个~ = 25°C 至 70°C。
Linux基础命令的进阶用法
凌晨2点,正在熟睡的你被电话惊醒:"线上服务响应超时,用户大面积投诉!" 你匆忙打开电脑,SSH 登录服务器,面对满屏的进程和日志,脑子一片空白——从哪里开始排查?用什么命令?怎么快速定位问题?
termux调试python猜数字游戏
用termux做一个猜数字游戏
下面是在Termux中创建猜数字游戏的步骤及完整实现方案,结合Python实现(最适配Termux环境):
? 一、环境准备(Termux基础配置)
1.
发表于 08-29 17:15
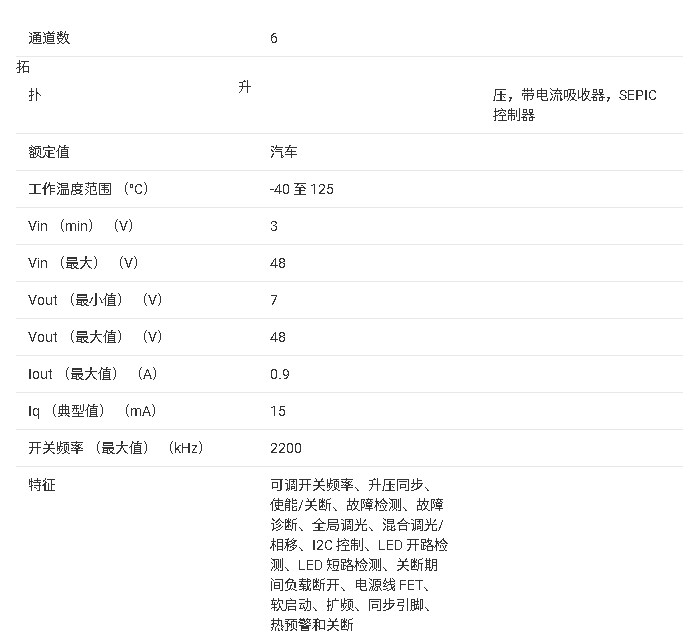
LP8863-Q1 具有六个 150 mA 通道的汽车显示 LED 背光驱动器技术手册
LP8863-Q1 是一款带有升压控制器的汽车高效 LED 驱动器。六个高精度电流吸收器支持相移,相移可根据使用的通道数自动调整。电流吸收器亮度可以通过 SPI 或 I2C 接口单独和全局控制;亮度
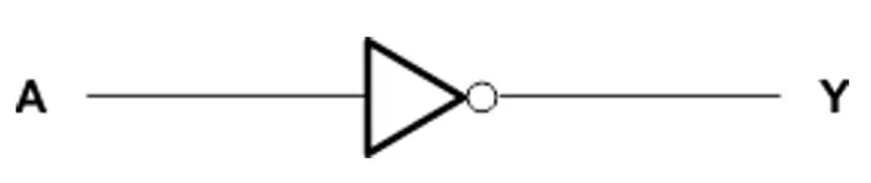
SN74AHCT04六路反相器技术解析与应用指南
Texas Instruments SN74AHCT04六路逆变器包含六个独立的逆变器并执行布尔函数Y = A。Texas Instruments SN74AHCT04具有TTL输入电平,允许从3.3V向上转换到5V。

Altium Designer PCB设计高级进阶
对PCB设计的高级进阶的内容进行相关的介绍
纯分享贴,有需要可以直接下载附件获取完整资料!
(如果内容有帮助可以关注、点赞、评论支持一下哦~)
发表于 04-27 16:40



评论